






锁的开销
锁的开销是巨大的,特别是对于多核多处理来讲。引入多处理,本身就是为了将并行化处理以提高性能,然而由于存在共享临界区,而这个临界区同时只能有一个线程访问(特别是对于写操作),那么本来并行的执行流在这里被串行化了,形象地看,这里好像是宽阔马路上的一个瓶颈,由于串行化是本质上存在的,因此该瓶颈就是不可消除的。问题是线程执行流如何度过这个瓶颈,很显然,它们谁都绕不开,现在问题是是它们到达这个瓶颈时该怎么办。
很显然,斗殴抢先是一种不合理但实用的简单方案,朴素的自旋锁就是这么设计的。然而,更加绅士的做法就是,既然暂时得不到通行权,那么自己先让出道路,sleep一会儿,这种方式就是sleep-wait方式,与之对应的就是持续spin-wait方式。问题是线程本身如何对这二者做出明智的选择。事实上,这种选择权交给了程序,而不是执行中的线程。
不要试图比较sleep-wait和spin-wait的性能,它们都是损耗了性能-因为串行化。其中,sleep-wait的开销在切换(涉及到进程,线程的切换比较,比如寄存器上下文,堆栈,某些处理器上cache刷新,MMU tlb刷新等),而spin-wait的开销很显然,就是持续浪费CPU周期,虽然没有切换的开销,但事实上,它这段时间什么也做不了。
为什么要引入spin-wait这种方式呢?因为如果始终是sleep-wait,那么sleep线程A切换到别的线程B后,锁被释放了,系统不一定能保证sleep的那个线程可以获得CPU从而切回来,即便如此,付出巨大的切换代价,有时间隔很短,线程B并没有由于线程A的绅士行为获得收益,这种姿态显然是不值得的,还不如保留本质,持续斗殴。
和中断相比,锁的开销更加巨大,如果可以通过关中断的方式换取无锁操作,那么这是值得的,但是(最讨厌且永恒的“但是”),你要考虑关中断的副作用,比如增加了处理延迟,然后你必须拿这种新的代价和锁的开销进行对比,权衡这种交易是否值得。
要开始本文了,为了简便起见,我不会给出太多的和处理器相关的细节,而是集中针对自旋锁本身。这些细节比如CPU cache机制,缓存一致性协议,内存屏障,Intel的pause指令,流水线,总线锁等,还好,这些概念都是可以很方便baidu出来的,不用去墙外。
关于自旋锁
Linux内核一开始就引入了自旋锁,所谓的自旋锁在等待锁过程中的行为就是原地打转,有人会觉得这浪费了CPU周期,但是你要明白,系统设计就是一场博弈,虽然不是零和,但是也要尽力寻找折中点,然而却没有两全其美的方案。
如果不原地打转,又该如何呢?很显然就是切换到别的线程,等待持锁者释放锁的时候,再将它唤醒,然而这里又有两次斗殴,首先,如果有多方都竞争一个锁,那么全部将它们唤醒,提供一个斗殴场地,等待一个胜出吗?退而求其次,即便仅仅唤醒首先排队的那个线程,task切换的开销算进去了吗?所以说,如果原地打转浪费的CPU周期小于两次切换开销浪费的CPU周期,那么原地打转就是合理的,这么说来,原地打转的时间越短越好。
就是如此。自旋锁的应用场合就是短时间持有临界区的场合,它是一种短期锁,如果占据临界区过久,随着原地打转浪费的CPU周期的增加,其开销将逐渐大于两次切换(切换开销是固定的-不考虑cache等),因此,理论上,能算出自旋锁在持锁期间可以执行多少代码。爆炸!
Ticket自旋锁的设计非常巧妙,它将一个CPU变量,比如32位的值分为高16位和低16位,每次lock的时候,CPU将高16位原子加上0x01(通过锁总线),然后将该值和低16位比较,如果相等则成功,如果不等则自旋的同时持续比较这两个值,而unlock操作则是简单递增锁的低16位加0x01(理论上不需要锁总线,因为不会有两个及以上的CPU同时拥有锁进行unlock操作,但是还是要考虑CPU的特性...)。这就是所谓的Ticket自旋锁的全部。
最近遇到了锁优化的问题,众所周知,锁优化是一个很精细的活儿,它既不能太复杂也不能太简单,特别是自旋锁的设计,更是如此。然而自旋锁设计的优势也很明显,那就是它让你少考虑很多问题:
1.一个CPU同时只能在一个自旋锁上自旋;
2.一旦开始自旋,直到获得锁,中间不能放弃退出自旋。
自旋锁的应用场合必须要明了,它不适合保护很大的临界区,因为这将导致自旋过久,它也不适合大量CPU的情况,因为它会导致自旋延时的N倍,虽然一段临界区很小,但是一个CPU自旋的时间可能是N倍,N为CPU的数量。这就引出了一个争论,Ticket排队自旋锁真的比斗殴型哄抢自旋锁好吗?如果不考虑cache亲和,斗殴型的自旋锁可以将每个CPU自旋的时间收敛到平均时间,而Ticket自旋锁将出现两极分化,也就是说,最长自旋时间和最短自旋时间是一个固定的倍数关系,随着CPU数量的增加,排队公平导致的不合理性将加大,你要知道,任何情况下队列都不可能超过一个临界值,超过了不满情绪将会增加,虽然这种长延时只是因为你来得晚导致的,看似很公平,实际上并不公平,因为并不清楚你来得晚的原因。
目前没有一种好的方案解决这个问题,一般情况,如果队列过长,工作人员会建议你一会儿再来看看,或者贴上大致的预估时间,你自己来绝对是排队还是放弃。
此外,对于该统计信息,可以对spin操作本身进行优化,就是说,内部的pause指令可以进行优化,这对流水线是有益的。
如果不原地打转,又该如何呢?很显然就是切换到别的线程,等待持锁者释放锁的时候,再将它唤醒,然而这里又有两次斗殴,首先,如果有多方都竞争一个锁,那么全部将它们唤醒,提供一个斗殴场地,等待一个胜出吗?退而求其次,即便仅仅唤醒首先排队的那个线程,task切换的开销算进去了吗?所以说,如果原地打转浪费的CPU周期小于两次切换开销浪费的CPU周期,那么原地打转就是合理的,这么说来,原地打转的时间越短越好。
就是如此。自旋锁的应用场合就是短时间持有临界区的场合,它是一种短期锁,如果占据临界区过久,随着原地打转浪费的CPU周期的增加,其开销将逐渐大于两次切换(切换开销是固定的-不考虑cache等),因此,理论上,能算出自旋锁在持锁期间可以执行多少代码。爆炸!
Linux自旋锁历史概览
Linux自旋锁发展了两代,第一代自旋锁是一种完全斗殴模式的无序自旋锁,也就是说,如果多个CPU同时争抢一个自旋锁,那么待持锁者解锁的时候,理论上它们获得锁的机会是不固定的,和cache等一系列因素相关,这就造成了不公平,第一个开始争抢的CPU不一定第一个获得...这就需要引入一个秩序,于是第二代Ticket自旋锁就设计出来了。Ticket自旋锁的设计非常巧妙,它将一个CPU变量,比如32位的值分为高16位和低16位,每次lock的时候,CPU将高16位原子加上0x01(通过锁总线),然后将该值和低16位比较,如果相等则成功,如果不等则自旋的同时持续比较这两个值,而unlock操作则是简单递增锁的低16位加0x01(理论上不需要锁总线,因为不会有两个及以上的CPU同时拥有锁进行unlock操作,但是还是要考虑CPU的特性...)。这就是所谓的Ticket自旋锁的全部。
最近遇到了锁优化的问题,众所周知,锁优化是一个很精细的活儿,它既不能太复杂也不能太简单,特别是自旋锁的设计,更是如此。然而自旋锁设计的优势也很明显,那就是它让你少考虑很多问题:
1.一个CPU同时只能在一个自旋锁上自旋;
2.一旦开始自旋,直到获得锁,中间不能放弃退出自旋。
自旋锁的应用场合必须要明了,它不适合保护很大的临界区,因为这将导致自旋过久,它也不适合大量CPU的情况,因为它会导致自旋延时的N倍,虽然一段临界区很小,但是一个CPU自旋的时间可能是N倍,N为CPU的数量。这就引出了一个争论,Ticket排队自旋锁真的比斗殴型哄抢自旋锁好吗?如果不考虑cache亲和,斗殴型的自旋锁可以将每个CPU自旋的时间收敛到平均时间,而Ticket自旋锁将出现两极分化,也就是说,最长自旋时间和最短自旋时间是一个固定的倍数关系,随着CPU数量的增加,排队公平导致的不合理性将加大,你要知道,任何情况下队列都不可能超过一个临界值,超过了不满情绪将会增加,虽然这种长延时只是因为你来得晚导致的,看似很公平,实际上并不公平,因为并不清楚你来得晚的原因。
目前没有一种好的方案解决这个问题,一般情况,如果队列过长,工作人员会建议你一会儿再来看看,或者贴上大致的预估时间,你自己来绝对是排队还是放弃。
try lock返回的预估信息
我建议在自旋锁加锁前,先try lock一次,正如现如今的实现一样,然而这个try并没有给出除了成功或者失败之外的信息,事实上更好的方式是,try,并且try返回一些有用的信息,比如等待预估时间,队长等统计信息,以供调用者决定是就地自旋还是干点别的。谁说内核中不能做大数据分析,很多统计信息和建议都可以通过数据分析得到。此外,对于该统计信息,可以对spin操作本身进行优化,就是说,内部的pause指令可以进行优化,这对流水线是有益的。
我的自旋锁设计
为什么我要设计一个新的自旋锁,一方面是我觉得Ticket自旋锁多个CPU虽然靠递增高位实现了排队,但是它们同时不断地检测自旋锁本身的值,cache有点浪费,所有的CPU cache上均会出现完全一样的自旋锁,并且一旦锁被unlock,还会触发cache一致性协议行为,另一方面,我觉得用一个32位(或者随便其它什么CPU内部类型)分为高低两部分来实现自旋锁虽然巧妙但是又过于简单,第三方面,我前些日子特别推崇小巧结构体实现的IP转发表,如今又重温更加小巧的Ticket自旋锁,心里总是有些嫉妒,所以怎么也得按照我的思路来一个”符合我的观念的“设计吧,事情就是这么开始的。
为什么要在自旋锁本身上集体自旋呢?如果有500多个CPU,大家一起探测同一个内存地址,然后持锁者释放锁,修改了该内存地址的CPU cache值,这将导致大量的cache一致性动作...为何不在自己的本地变量上自旋呢?如果持锁者释放锁,那么就将下一个等待者的本地变量置0,这意味着CPU只需要拿本地变量和0比较即可。
因此就需要有一个本地的地方保存这个变量,我为每一个CPU申请了一个per CPU变量,内部保存一个栈,用于实现严格的”后加锁先解锁“顺序的自旋锁,当然这样对调用者有要求,或者说把栈改成一个空闲队列,用于实现任意顺序加锁/解锁得自旋锁,这个对调用者没有要求,但是可能会引起死锁。
为了实现多个CPU同时争抢自旋锁的优雅排队,势必要维护一个队列,单向推进的即可,没有必要用list_head结构体。排入队中的元素就是栈帧,而栈帧是per CPU的。操作栈帧只有三个机会:
自己加锁时:加锁时需要用自己的栈帧排队,不可避免要操作链表,而可能同时有多个CPU的栈帧要排队,因此需要保证整个排队动作的单向链表操作是原子的,锁总线是一个办法。
自己自旋时:这个时段不涉及别的CPU,甚至自己的栈帧都不会到达别的CPU的cache中,栈帧是CPU本地变量。
排在前面的栈帧解锁时:这个时候理论上也和其它CPU无关,因为队列是严格顺序的,取下一个即可,无需争抢,但是有一种竞争情况,即开始取下一个栈帧时,队列已经没有下一个,然而按照空队列处理时,却有了下一个栈帧,这将使得刚刚排入的新栈帧永远无法获得锁,因此这个动作必须是原子的。至于说取到下一个排队栈帧,设置它时,就不用保证原子了,因为它就是它后面的它,一个栈帧不会排到两个队列,且排入了就不能放弃,别人也不会动它的。
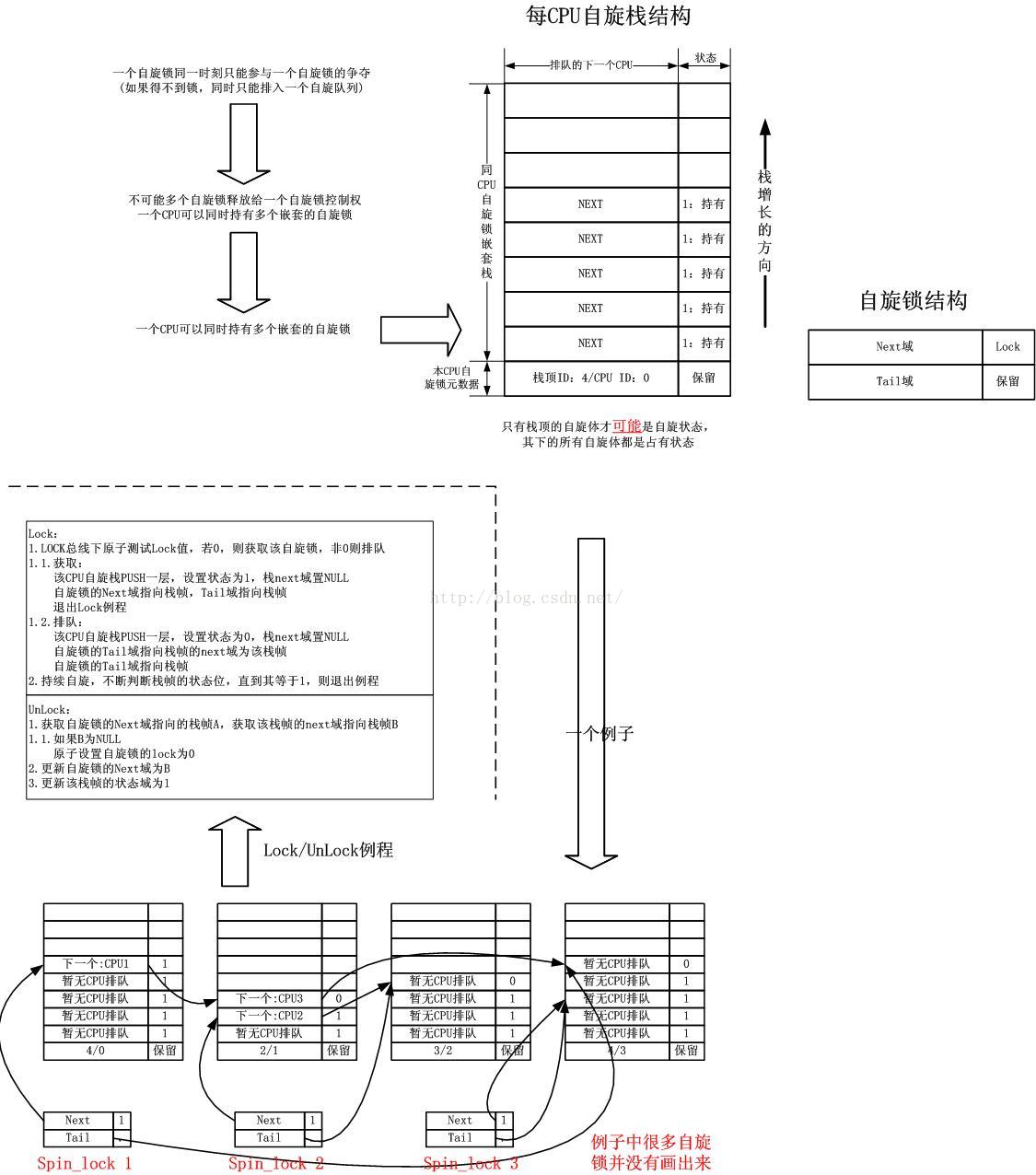
在per CPU结构体上自旋
如何解决线程间同步问题,这个问题确实不好解决,但是自己管自己,也就是操作本地数据,总是一个合理的思路。为什么要在自旋锁本身上集体自旋呢?如果有500多个CPU,大家一起探测同一个内存地址,然后持锁者释放锁,修改了该内存地址的CPU cache值,这将导致大量的cache一致性动作...为何不在自己的本地变量上自旋呢?如果持锁者释放锁,那么就将下一个等待者的本地变量置0,这意味着CPU只需要拿本地变量和0比较即可。
因此就需要有一个本地的地方保存这个变量,我为每一个CPU申请了一个per CPU变量,内部保存一个栈,用于实现严格的”后加锁先解锁“顺序的自旋锁,当然这样对调用者有要求,或者说把栈改成一个空闲队列,用于实现任意顺序加锁/解锁得自旋锁,这个对调用者没有要求,但是可能会引起死锁。
为了实现多个CPU同时争抢自旋锁的优雅排队,势必要维护一个队列,单向推进的即可,没有必要用list_head结构体。排入队中的元素就是栈帧,而栈帧是per CPU的。操作栈帧只有三个机会:
自己加锁时:加锁时需要用自己的栈帧排队,不可避免要操作链表,而可能同时有多个CPU的栈帧要排队,因此需要保证整个排队动作的单向链表操作是原子的,锁总线是一个办法。
自己自旋时:这个时段不涉及别的CPU,甚至自己的栈帧都不会到达别的CPU的cache中,栈帧是CPU本地变量。
排在前面的栈帧解锁时:这个时候理论上也和其它CPU无关,因为队列是严格顺序的,取下一个即可,无需争抢,但是有一种竞争情况,即开始取下一个栈帧时,队列已经没有下一个,然而按照空队列处理时,却有了下一个栈帧,这将使得刚刚排入的新栈帧永远无法获得锁,因此这个动作必须是原子的。至于说取到下一个排队栈帧,设置它时,就不用保证原子了,因为它就是它后面的它,一个栈帧不会排到两个队列,且排入了就不能放弃,别人也不会动它的。
设计框架图示
下面用一个图示展示一下我的这个排队自旋锁的设计吧
自旋锁分析
看起来有点复杂了,那么性能一定不高,其实确实比Ticket自旋锁复杂,但是你能找到比Ticket自旋锁更简单优雅的设计吗?我不图更简单,但图够优雅。虽然我的一个原子操作序列比Ticket自旋锁的单纯加1操作复杂了很多,涉及到很多链表操作,但是我的局部性利用会更好,特别是采用了per CPU机制,在集体自旋的时间段,CPU cache数据同步效率会更高,你要知道,自旋的时间和锁总线的时间相比,那可久多了。采用数组实现的堆栈(即便是空闲链表也一样),数据的局部性利用效果会更好,也就说,一个CPU的所有自旋锁的自旋体均在这个数组中,这个数组有多大,取决于系统同时持有的自旋锁有多少。
未完成的伪代码
以下是根据上述的图示写出的测试代码,代码未经优化,只是能跑。在用户空间做过测试。#define NULL 0
/* 总线锁定的开始与结束 */
#define LOCK_BUS_START
#define LOCK_BUS_END
/* pause指令对性能非常重要,具体可参阅Intel指令手册,
然而它并不是有优化作用,而是减轻了恶化效果
*/
#define cpu_relax()
/* 内存屏障对于多核心特别重要 */
#define barrier()
#define MAX_NEST 8
/*
* 定义per CPU自旋栈的栈帧
* */
struct per_cpu_spin_entry {
struct per_cpu_spin_entry *next_addr;
char status;
};
/*
* 定义自旋锁的per CPU自旋栈
* */
struct per_cpu_stack {
/* per CPU自旋栈 */
struct per_cpu_spin_entry stack[MAX_NEST];
/* 为了清晰,将CPU ID和栈顶ID独立为char型(仅支持256个CPU) */
char top;
char cpuid;
};
/*
* 定义自旋锁
* */
typedef struct {
/* 为了代码清晰,减少bit操作,独立使用一个8位类型 */
char lock;
/* 指向的下一个要转交给的per CPU栈帧 */
struct per_cpu_spin_entry *next;
/* 指向排队栈帧的最后一个per CPU栈帧 */
struct per_cpu_spin_entry *tail;
} relay_spinlock_t;
static void relay_spin_lock(relay_spinlock_t *lock)
{
struct per_cpu_stack *local = .....按照per CPU变量去取值
struct per_cpu_spin_entry *entry;
local->top++;
local->stack[local->top].status = 0;
entry = &(local->stack[local->top]);
LOCK_BUS_START
if (unlikely(!lock->lock)) {
lock->tail = lock->next = entry;
entry->status = 1;
lock->lock = 1;
LOCK_BUS_END
return;
} else {
lock->tail->next_addr = entry;
lock->tail = entry;
}
LOCK_BUS_END
for (;;) {
if (entry->status == 0) {
break;
}
cpu_relax();
}
barrier();
}
static void relay_spin_unlock(relay_spinlock_t *lock)
{
struct per_cpu_stack *local = .....按照per CPU变量去取值
struct per_cpu_spin_entry *next;
LOCK_BUS_START
next = lock->next->next_addr;
LOCK_BUS_END
local->top--;
/* 在confirm之前,可以保证只有一个CPU在操作 */
if (unlikely(!next)) {
lock->lock = 0;
lock->tail = lock->next = NULL;
return;
}
confirm:
lock->next = next;
next->status = 0;
}地址指针索引化改进
请看上面的那个图,多个CPU的per CPU自旋堆栈是地址独立的,这就意味着我们要么在栈帧中保存一个指针,要么就是采用base地址加偏移的方式,这样可以省掉几个字节,采用对齐方案的话,一个栈帧的后几个bit对于地址和偏移而言是不用的,所以就可以做status位,这些都是基本的空间优化。我要做的就是把所有的CPU的自旋堆栈全部整合在一张表中,分为二维,一维代表CPU,一维代表栈帧,这样就可以在栈帧中写索引而不是地址了,这样就能节省大量的内存了,除却空间节省之外,连续内存的时间局部性也更好利用。因为系统中所有的自旋锁的自旋体,全部都在这一张表中了,整个系统的自旋锁操作完全不离此表,它就像MMU一样,全然成了一个服务性基础设施。上述例子地址索引化后如下图所示:
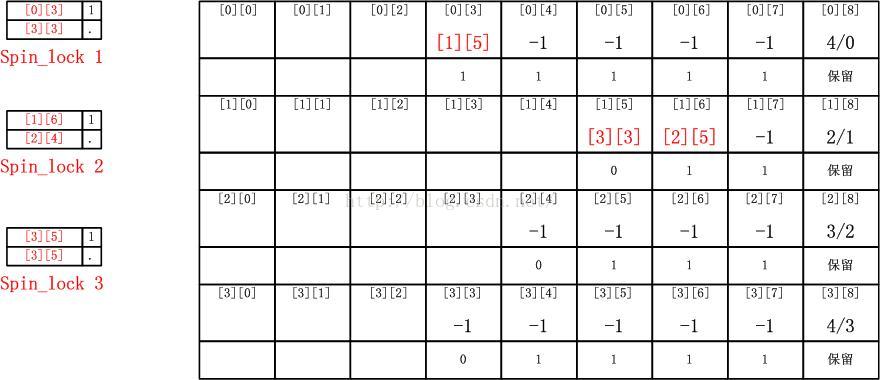
不限制解锁顺序改进
采用堆栈的方式保存自旋体,就要严格按照push的反顺序pop,这就要求加锁和解锁操作要和push/pop操作完全一致。而这种限制虽然不错,但并不必须,如果不要求解锁顺序,那就需要将堆栈做成空闲链表,它的操作如下图所示: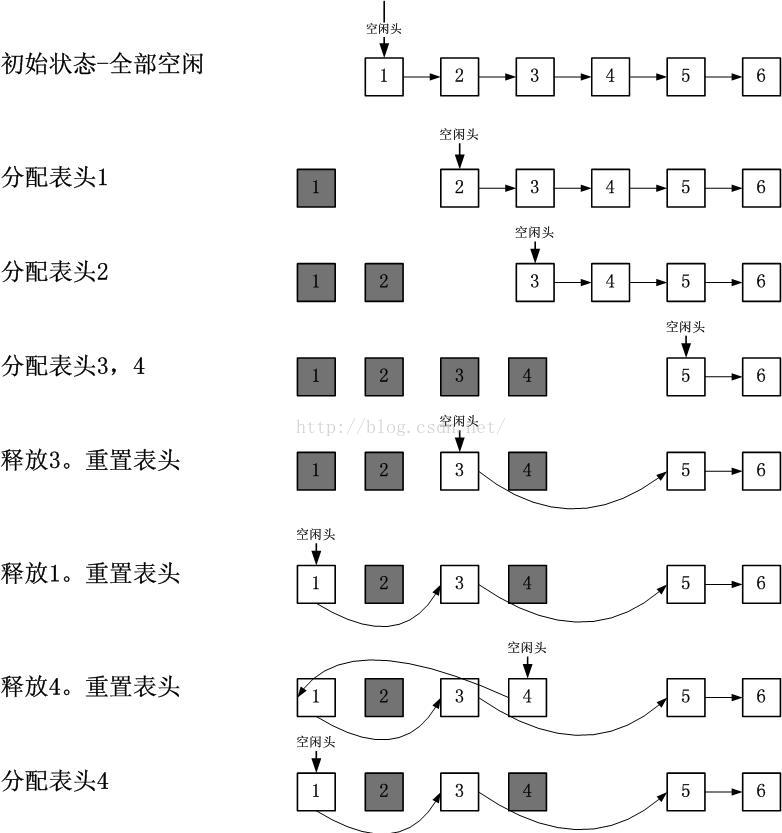
这种空闲链表组织方式和UNIX文件的空闲块组织方式类似,另一个例子就是Linux内核的Slab分配器中的hot cache的组织方式。采用这种组织方式。这种方式的好处在于,最先释放的最先被分配,这样会cache会好一点。其实这是一种不受空间约束的堆栈,因此我不把它作为一种特殊的方式,也称它为堆栈。
采用单链表而不是双链表的一个原始是确实用不到双向链表,另一个更加隐蔽的原因在于,单链表修改时只需要修改一个指针,而一个修改操作可以是原子的,锁总线锁cache的开销更小
好像没写完的样子.....















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









