






代码的实现是简单的,背后的思绪是复杂的。
如果单纯的将《 彻底实现Linux TCP的Pacing发送逻辑-普通timer版》中的timer_list换成hrtimer,必然招致失败。因为在hrtimer的function中,调用诸如tcp_write_xmit这样的长路径函数是一种用丝袜装榴莲的行为。好吧,在无奈中我只能参考TSQ的做法。旧恨心魔!
在Linux的TCP实现中,TSQ保证了一个单独的流不会过多地占据发送缓存,从而保证的多个数据流的相对公平。这个机制是用tasklet实现的,那么我觉得TCP的pacing也能通过tasklet来实现。
-------------------------------------
TCP毁了整个网络世界的和谐!Why?
是谁说TCP发送端一定要维护一个拥塞窗口了?这人树立了权威!然而“拥塞窗口”这个概念只说明了事情的一个方面而对另一个方面只字未提!我说过,拥塞窗口是一个标量而不是一个矢量,这样说的含义在于,它仅仅是在一个维度上度量的一个数值而已,表示“目前可以发送的数据量”,仅此而已。拥塞窗口根本不懂网络上发生了什么。不过可以肯定的是,接收端观察到的数据到达行为是真实的,即两个数据包到达之间是有间隔的!如果你分别在发送端和接收端抓包并分析,将会很容易看到这个事实。
我们再看发送端,以Linux为例,其发送行为是tcp_write_xmit主持的,它会一次性发送所有可供发送的数据包,每个数据包之间的延迟仅仅是数据包走一趟协议栈的主机延迟,这种延迟对于长肥网络延迟是可以忽略不计的!请我们不要被千兆/万兆以太网以及DC内部的假象所蒙蔽,我们在互联网上访问的内容大多数来自“千里之外”,中间的路途崎岖坎坷,不要相信什么CDN,全都扯淡,商业宣传的噱头,没个鸟用。回到正文,既然发送端是一次性突发发送的数据包,而接收端是间歇性接收到数据包,中间一定发生了什么!是的,这就是根本,但是我们不用关心这个,只要好好跪舔TCP就好了。我们注意一种类似的现象,那就是结婚的婚车,接新娘出发的时候,几十辆德系BBA(奔驰,宝马,奥迪)由一辆“超级豪车”(比如改装的宾利)领衔,一字排开列队,集体统一出发,可是在快到达新娘子家的时候,头车必须停下来等待后车,以营造一种一路上队形持续保持并且今天太阳为你升起的假象,这就是流量整形的作用,首先,车队经由的道路是一个统计复用的系统,并没有卖给哪个个人,加上路上红绿灯,插队,交通拥堵等因素,车队会被打散,本来前后车仅仅相隔几米,最终这个距离会拉开到以公里计算,快要到达目的地的时候,为了以出发时的阵容到达,就必须等待所有的车辆到齐,然后一字排开进入新娘子家。其实这些在网卡数据传输技术中,都有对应的东西,比如最后那个等车到齐的行为,其实就是LRO(large-receive-offload)或者分片重组之类的。
我要说的不是这个,我要说的是,你知道你结个婚搞这么个车队,给交通带来多大影响吗?!我们假设所有人都是毫无感性的,谁也不让谁,但你能想象这么大的一字车队从一个小巷子里开出的场景吗?令人遗憾的是,我们的互联网上几乎每一台可以发送数据的主机(不管是DC的机器,还是你我的电脑),每时每刻都在有这么大阵容的车队出发!难道就不能互相谦让一下,在起码在两车之间拉开一辆车的距离,至少过十字路口的时候,有别的车辆可以交叉通过啊!但事实上,在中国,傻逼才会这么做,劣币驱良币,因为没人这么做!大家都恨不得让车队更长些呢!
在网络上,虽然TCP的拥塞窗口指示了可以发送多少数据,但是为什么不能按照接收端实际接收的行为来指导发送行为呢?为什么几十年来都是一次性发送并依然如故呢?至少Linux的TCP是这样的,我相信别的也好不到哪去,毕竟“作恶的,必被剪除”只是一个心愿。劣币驱良币,大家都作恶,恶就成了善。
这就是TCP的悲哀!Google的工程师看到了这种悲哀,造出了BBR算法,引无数人跪舔,这更悲哀。Google的BBR patch如是说:
The primary control is the pacing rate: BBR applies a gain
multiplier to transmit faster or slower than the observed bottleneck
bandwidth. The conventional congestion window (cwnd) is now the
secondary control; the cwnd is set to a small multiple of the
estimated BDP (bandwidth-delay product) in order to allow full
utilization and bandwidth probing while bounding the potential amount
of queue at the bottleneck.
总结一下本段的抱怨。只用拥塞窗口控制TCP的发送行为是一个垃圾方式,都是鸡屎。有破才有立,我决定实现Linux TCP pacing的hrtimer版了。
-------------------------------------
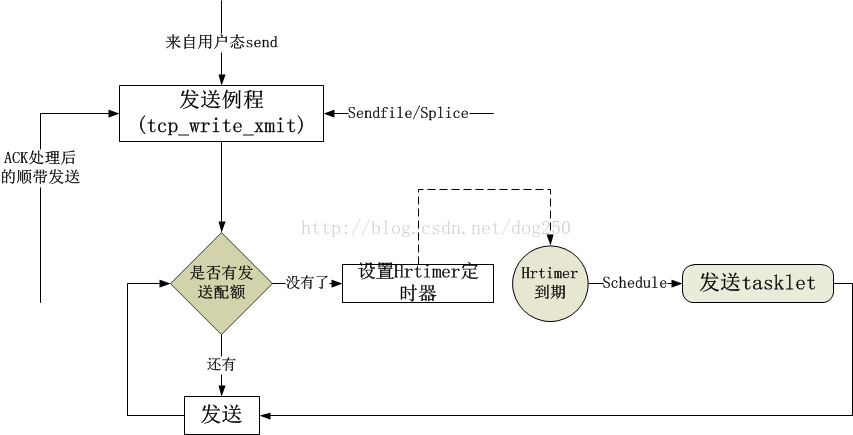
总的框架如下:
-------------------------------------
还是跟普通timer版一样,我把代码拆解成几个部分列如下,然而这并不是代码的全部,我省掉了一些诸如list_head初始化的代码,以及一些变量初始化的代码。
2.hrtimer相关:
4.tcp_release_cb中执行
以上4个部分就是几乎全部的逻辑了。
-------------------------------------
现在看看效果,使用netperf的结果我就不贴了,我只贴一个使用curl下载10M文件的对比结果。
我的想法并不是要在TCP上搞什么pacing,整个TCP,如果你想改变点什么的话,在中国就是个丑行,因为中国人根本不懂真正的博弈。实际上我的目标是UDP之上承载的VPN流量!因为相比一个普通的TCP数据包,一个VPN数据包被丢掉的代价太大了。这部仅仅意味着网络带宽被浪费,由于重传还会把CPU拉入泥潭!上周写了一个基于DTLS的VPN,在我的测试中,CPU一直飙高,后来查出来是因为丢包太严重导致,然后在用户态实现了一个pacing发送,问题就解决了。
UDP当然可以在用户态实现pacing,而TCP却不能,因为TCP的发送并不受用户的控制,所以就想到了这个方案并简单实现了个Demo。然而多多少少让人觉得我身在曹营心在汉,其实则不然,我其实身在曹营心也在曹营,只是哀其不幸,而怒其不争。
如果单纯的将《 彻底实现Linux TCP的Pacing发送逻辑-普通timer版》中的timer_list换成hrtimer,必然招致失败。因为在hrtimer的function中,调用诸如tcp_write_xmit这样的长路径函数是一种用丝袜装榴莲的行为。好吧,在无奈中我只能参考TSQ的做法。旧恨心魔!
在Linux的TCP实现中,TSQ保证了一个单独的流不会过多地占据发送缓存,从而保证的多个数据流的相对公平。这个机制是用tasklet实现的,那么我觉得TCP的pacing也能通过tasklet来实现。
-------------------------------------
TCP毁了整个网络世界的和谐!Why?
是谁说TCP发送端一定要维护一个拥塞窗口了?这人树立了权威!然而“拥塞窗口”这个概念只说明了事情的一个方面而对另一个方面只字未提!我说过,拥塞窗口是一个标量而不是一个矢量,这样说的含义在于,它仅仅是在一个维度上度量的一个数值而已,表示“目前可以发送的数据量”,仅此而已。拥塞窗口根本不懂网络上发生了什么。不过可以肯定的是,接收端观察到的数据到达行为是真实的,即两个数据包到达之间是有间隔的!如果你分别在发送端和接收端抓包并分析,将会很容易看到这个事实。
我们再看发送端,以Linux为例,其发送行为是tcp_write_xmit主持的,它会一次性发送所有可供发送的数据包,每个数据包之间的延迟仅仅是数据包走一趟协议栈的主机延迟,这种延迟对于长肥网络延迟是可以忽略不计的!请我们不要被千兆/万兆以太网以及DC内部的假象所蒙蔽,我们在互联网上访问的内容大多数来自“千里之外”,中间的路途崎岖坎坷,不要相信什么CDN,全都扯淡,商业宣传的噱头,没个鸟用。回到正文,既然发送端是一次性突发发送的数据包,而接收端是间歇性接收到数据包,中间一定发生了什么!是的,这就是根本,但是我们不用关心这个,只要好好跪舔TCP就好了。我们注意一种类似的现象,那就是结婚的婚车,接新娘出发的时候,几十辆德系BBA(奔驰,宝马,奥迪)由一辆“超级豪车”(比如改装的宾利)领衔,一字排开列队,集体统一出发,可是在快到达新娘子家的时候,头车必须停下来等待后车,以营造一种一路上队形持续保持并且今天太阳为你升起的假象,这就是流量整形的作用,首先,车队经由的道路是一个统计复用的系统,并没有卖给哪个个人,加上路上红绿灯,插队,交通拥堵等因素,车队会被打散,本来前后车仅仅相隔几米,最终这个距离会拉开到以公里计算,快要到达目的地的时候,为了以出发时的阵容到达,就必须等待所有的车辆到齐,然后一字排开进入新娘子家。其实这些在网卡数据传输技术中,都有对应的东西,比如最后那个等车到齐的行为,其实就是LRO(large-receive-offload)或者分片重组之类的。
我要说的不是这个,我要说的是,你知道你结个婚搞这么个车队,给交通带来多大影响吗?!我们假设所有人都是毫无感性的,谁也不让谁,但你能想象这么大的一字车队从一个小巷子里开出的场景吗?令人遗憾的是,我们的互联网上几乎每一台可以发送数据的主机(不管是DC的机器,还是你我的电脑),每时每刻都在有这么大阵容的车队出发!难道就不能互相谦让一下,在起码在两车之间拉开一辆车的距离,至少过十字路口的时候,有别的车辆可以交叉通过啊!但事实上,在中国,傻逼才会这么做,劣币驱良币,因为没人这么做!大家都恨不得让车队更长些呢!
在网络上,虽然TCP的拥塞窗口指示了可以发送多少数据,但是为什么不能按照接收端实际接收的行为来指导发送行为呢?为什么几十年来都是一次性发送并依然如故呢?至少Linux的TCP是这样的,我相信别的也好不到哪去,毕竟“作恶的,必被剪除”只是一个心愿。劣币驱良币,大家都作恶,恶就成了善。
这就是TCP的悲哀!Google的工程师看到了这种悲哀,造出了BBR算法,引无数人跪舔,这更悲哀。Google的BBR patch如是说:
The primary control is the pacing rate: BBR applies a gain
multiplier to transmit faster or slower than the observed bottleneck
bandwidth. The conventional congestion window (cwnd) is now the
secondary control; the cwnd is set to a small multiple of the
estimated BDP (bandwidth-delay product) in order to allow full
utilization and bandwidth probing while bounding the potential amount
of queue at the bottleneck.
总结一下本段的抱怨。只用拥塞窗口控制TCP的发送行为是一个垃圾方式,都是鸡屎。有破才有立,我决定实现Linux TCP pacing的hrtimer版了。
-------------------------------------
总的框架如下:
-------------------------------------
还是跟普通timer版一样,我把代码拆解成几个部分列如下,然而这并不是代码的全部,我省掉了一些诸如list_head初始化的代码,以及一些变量初始化的代码。
1.tasklet的实现:
// 定义pacing_tasklet:
/* include/net/tcp.h */
struct pacing_tasklet {
struct tasklet_struct tasklet;
struct list_head head; /* queue of tcp sockets */
};
extern struct pacing_tasklet pacing_tasklet;
/* net/ipv4/tcp_output.c */
// 定义per cpu的tasklet变量
DEFINE_PER_CPU(struct pacing_tasklet, pacing_tasklet);
// 独立出来的handler,仅仅为了与tasklet的action分离,使其不至于太长
static void tcp_pacing_handler(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
if(!sysctl_tcp_pacing || !tp->pacing.pacing)
return ;
if (sock_owned_by_user(sk)) {
if (!test_and_set_bit(TCP_PACING_TIMER_DEFERRED, &tcp_sk(sk)->tsq_flags))
sock_hold(sk);
goto out;
}
if (sk->sk_state == TCP_CLOSE)
goto out;
if(!sk->sk_send_head){
goto out;
}
tcp_push_pending_frames(sk);
out:
if (tcp_memory_pressure)
sk_mem_reclaim(sk);
}
// pacing tasklet的action函数
static void tcp_pacing_func(unsigned long data)
{
struct pacing_tasklet *pacing = (struct pacing_tasklet *)data;
LIST_HEAD(list);
unsigned long flags;
struct list_head *q, *n;
struct tcp_sock *tp;
struct sock *sk;
local_irq_save(flags);
list_splice_init(&pacing->head, &list);
local_irq_restore(flags);
list_for_each_safe(q, n, &list) {
tp = list_entry(q, struct tcp_sock, pacing_node);
list_del(&tp->pacing_node);
sk = (struct sock *)tp;
bh_lock_sock(sk);
tcp_pacing_handler(sk);
bh_unlock_sock(sk);
clear_bit(PACING_QUEUED, &tp->tsq_flags);
}
}
// 初始化pacing tasklet(完全学着tsq的样子来做)
void __init tcp_tasklet_init(void)
{
int i,j;
struct sock *sk;
local_irq_save(flags);
list_splice_init(&pacing->head, &list);
local_irq_restore(flags);
list_for_each_safe(q, n, &list) {
tp = list_entry(q, struct tcp_sock, pacing_node);
list_del(&tp->pacing_node);
sk = (struct sock *)tp;
bh_lock_sock(sk);
tcp_pacing_handler(sk);
bh_unlock_sock(sk);
clear_bit(PACING_QUEUED, &tp->tsq_flags);
}
}
2.hrtimer相关:
/* net/ipv4/tcp_timer.c */
// 重置hrtimer定时器
void tcp_pacing_reset_timer(struct sock *sk, u64 expires)
{
struct tcp_sock *tp = tcp_sk(sk);
u32 timeout = nsecs_to_jiffies(expires);
if(!sysctl_tcp_pacing || !tp->pacing.pacing)
return;
hrtimer_start(&sk->timer,
ns_to_ktime(expires),
HRTIMER_MODE_ABS_PINNED);
}
// hrtimer的超时回调
static enum hrtimer_restart tcp_pacing_timer(struct hrtimer *timer)
{
struct sock *sk = container_of(timer, struct sock, timer);
struct tcp_sock *tp = tcp_sk(sk);
if (!test_and_set_bit(PACING_QUEUED, &tp->tsq_flags)) {
unsigned long flags;
struct pacing_tasklet *pacing;
// 仅仅调度起tasklet,而不是执行action!
local_irq_save(flags);
pacing = this_cpu_ptr(&pacing_tasklet);
list_add(&tp->pacing_node, &pacing->head);
tasklet_schedule(&pacing->tasklet);
local_irq_restore(flags);
}
return HRTIMER_NORESTART;
}
// 初始化
void tcp_init_xmit_timers(struct sock *sk)
{
inet_csk_init_xmit_timers(sk, &tcp_write_timer, &tcp_delack_timer,
&tcp_keepalive_timer);
hrtimer_init(&sk->timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_PINNED);
sk->timer.function = &tcp_pacing_timer;
}/* net/ipv4/tcp_output.c */
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
...
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
u64 now = ktime_get_ns();
...
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
/* Force out a loss probe pkt. */
cwnd_quota = 1;
else if(tp->pacing.pacing == 0) // 这里是个创举,既然pacing rate就是由cwnd算出来,检查了pacing rate就不必再检测cwnd了,但是在bbr算法中要慎重,因为bbr的pacing rate真不是由cwnd算出来的,恰恰相反,cwnd是由pacing算出来的!
break;
}
// 通告窗口与网络拥塞无关,还是要检测的。
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now)))
break;
// 这里的逻辑与普通timer版的一样!
if (sysctl_tcp_pacing && tp->pacing.pacing == 1) {
u32 plen;
u64 rate, len;
if (now < tp->pacing.next_to_send) {
tcp_pacing_reset_timer(sk, tp->pacing.next_to_send);
break;
}
rate = sysctl_tcp_rate ? sysctl_tcp_rate:sk->sk_pacing_rate;
plen = skb->len + MAX_HEADER;
len = (u64)plen * NSEC_PER_SEC;
if (rate)
do_div(len, rate);
tp->pacing.next_to_send = now + len;
if (cwnd_quota == 0)
cwnd_quota = 1;
}
if (tso_segs == 1) {
...
}4.tcp_release_cb中执行
/* net/ipv4/tcp_output.c */
void tcp_release_cb(struct sock *sk)
{
...
if (flags & (1UL << TCP_PACING_TIMER_DEFERRED)) {
if(sk->sk_send_head) {
tcp_push_pending_frames(sk);
}
__sock_put(sk);
}
...
}以上4个部分就是几乎全部的逻辑了。
-------------------------------------
现在看看效果,使用netperf的结果我就不贴了,我只贴一个使用curl下载10M文件的对比结果。
首先看标准cubic算法的曲线:
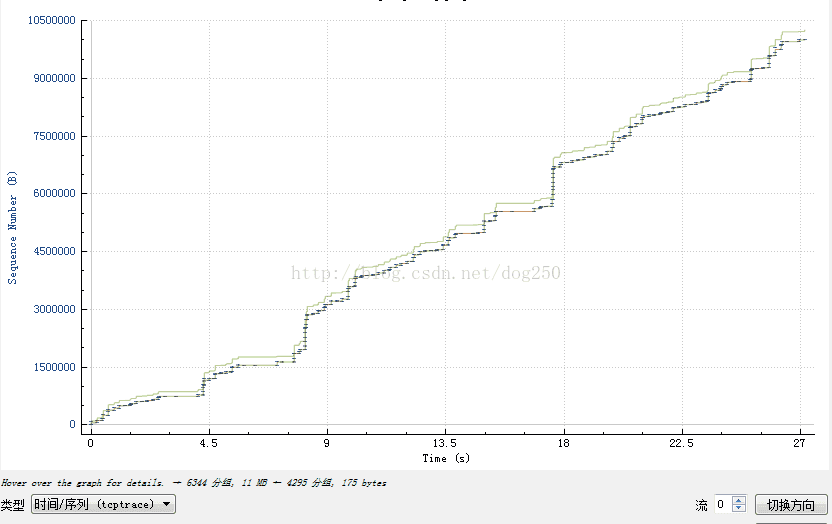
CTMB,垃圾!都他妈的是垃圾!
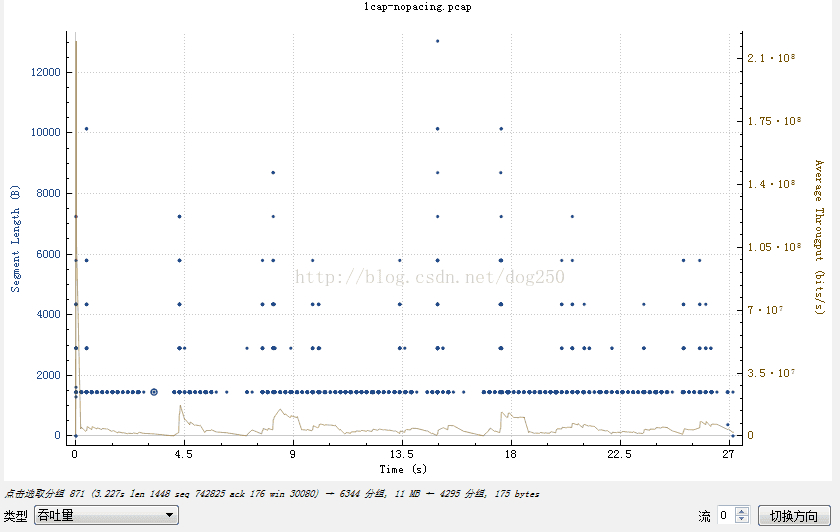
其吞吐量曲线如下图所示:
然后再看我的pacing曲线:
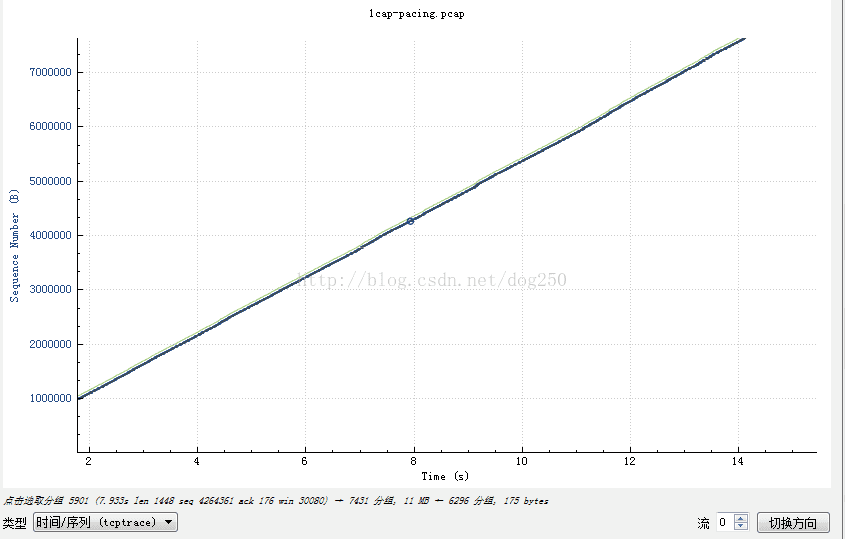
然后再看看吞吐量的图!我虽然没有上过大学,其实我也是不屑于大学的,我的圈子里,都是硕博连读的,好久不回一次国,而我,不知本科为何?!那么看看结果吧:
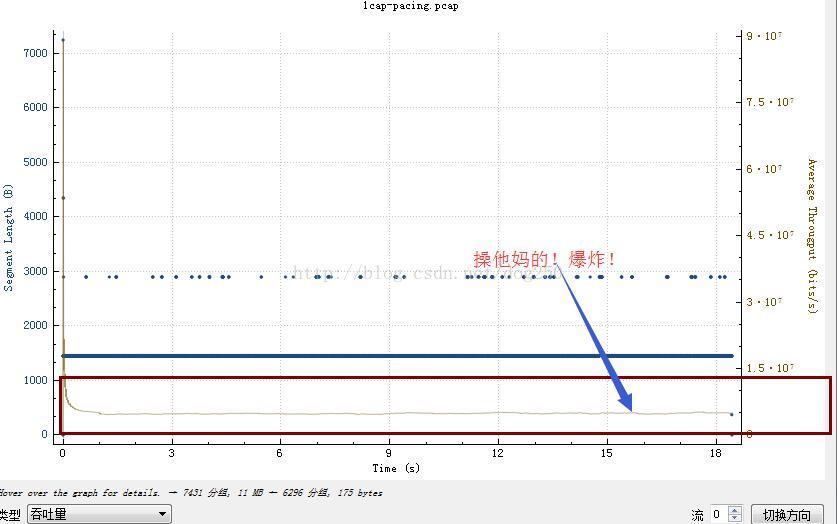
-------------------------------------
最后看看我最初的愿景。我的想法并不是要在TCP上搞什么pacing,整个TCP,如果你想改变点什么的话,在中国就是个丑行,因为中国人根本不懂真正的博弈。实际上我的目标是UDP之上承载的VPN流量!因为相比一个普通的TCP数据包,一个VPN数据包被丢掉的代价太大了。这部仅仅意味着网络带宽被浪费,由于重传还会把CPU拉入泥潭!上周写了一个基于DTLS的VPN,在我的测试中,CPU一直飙高,后来查出来是因为丢包太严重导致,然后在用户态实现了一个pacing发送,问题就解决了。
UDP当然可以在用户态实现pacing,而TCP却不能,因为TCP的发送并不受用户的控制,所以就想到了这个方案并简单实现了个Demo。然而多多少少让人觉得我身在曹营心在汉,其实则不然,我其实身在曹营心也在曹营,只是哀其不幸,而怒其不争。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









