









原文链接:https://arxiv.org/pdf/2012.11926.pdf
Abstract
为预先训练好的语言模型提供简单的任务描述或自然语言提示,可以在文本分类任务产生令人印象深刻的few shot结果。
在本文中,我们表明了这个潜在的想法也可以应用于文本生成任务:我们采用Pattern Exploiting Training(PET)范式,这是一种最近提出的few shot方法,用于微调文本生成任务上的生成语言模型。在几个文本摘要和标题生成数据集上,我们提出的PET的变体模型均优于强基线模型。
作者贡献如下:
1.我们描述了如何修改PET,用于微调序列生成任务的生成语言模型。
2.我们证明,使用PET训练PEGASES(飞马)模型(google的一篇PET的工作)在大量任务和训练集大小上优于常规微调。
3.我们分析了影响PET强大性能的因素。
Intro & method
首先对本文结合前人工作,飞马模型与PET做一个简要的介绍:
1.PEGASES(飞马)模型:
引用一篇解读模型的文章:https://blog.csdn.net/Airstudy/article/details/107599128

谷歌的研究人员提出了一个自监督的预训练来生成文本摘要, 重点在于预训练的时候的目标是把生成间隙句子(GSG), 所以在提取文本摘要的时候,简单的finetuning有很大的提升。其步骤如下:
- 随机mask掉一部分句子,然后将这些Gap sentence直接拼接,作为一个“伪摘要”。 mask调的句子则被[Mask] token 替换掉,为了更接近我们的下游任务,我们选择在文章中比较重要的句子。然后使用transformer模型进行训练,以生成这个被mask部分句子文档的伪摘要。
- GSR(gap sentence ratio)是GSG(Gap Sentences Generation)的超参, 指的是文档中选择间隔句子的个数除以句子总数,相当于其他研究中的mask比例。
- 句子选取,论文中采用3种策略来选取gap sentence
1.Randam:均匀的随机选出m个句子
2.Lead:选取前m个句子
3.Principal:根据重要性选择top-m最重要的句子。使用句子A和除该句子A外的剩余文档的RANGE-F1来作为重要性的计算指标。公式如下,
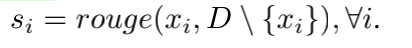
2.PET
我们首先讨论用于文本分类任务的模式利用训练(PET),即,对于某些文本输入x∈X必须从有限集合Y映射到单个输出y的问题。设M是一个掩码模型(MLM),T是它的标记集合和__∈T为掩码标记;我们将所有标记序列的集合表示为T∗。PET要求:
一个模式Pattern:P(x),它将原本的输入映射到一个包含1个mask token的问题;
一个表达器verbalizer:v(y),它将每个输出映射到代表其含义的单个token上。
所以原本的问题也得到了转换,给定x后获得y的概率,也变成了掩码模型M在P(x)的mask位置预测为v(y)的概率。
之后将P与V进行配对训练,并遵循:
- 在训练时,对于每一对(P,v)设置,都有一个单独的MLM。
- 训练好的MLM用伪标签标注一组未标记的示例。
- MLM在得到的伪标签数据集上被finetune,并结合一个分类头,作为最终的分类器。
3.PET for Text Generation(作者方法)
作者在设计一种适合文本生成的PET时,有几个差异需要考虑:
- 首先,文本生成不需要表达器,因为输出的摘要已经由自然语言句子组成。
- 其次,大多数生成语言模型的编码器-解码器架构支持对模式应用的一些微妙的调整。最后,我们需要一种新的策略来组合多个模式,因为我们不能简单地以一种有意义的方式平均由不同模型产生的文本序列。
在本节中,让P作为一个模式,对于x∈X,y∈Y和P(x)=z。我们考虑了一个使用掩码语言建模目标预先训练的编码器-解码器模型M。该模型必须能够计算一个概率PM(y|z),以测量y在多大程度上是z中mask位置的合理替代。我们进一步假设这是通过将y的联合概率分解如下来实现的:
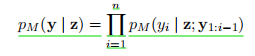
其中z代表x转化成mask掉1个token的模板,y1-i为在生成模型生成 yi 时,之前的输出序列,yi为当前输出的token。生成的序列长度为n所以进行n次连乘。如果我们碰巧已经知道y的一些前缀y1:k−1(之前已经训练过的),那么剩余序列y k:n的概率可以表示为:
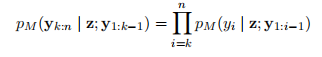
作者在初步实验中,我们发现属于部分生成的输出序列的token(即使用解码器处理的tokens)比常规输入的token对模型的预测有更大的影响。这更适用于飞马模型,因为是经过预先训练才能生成完整的句子,如果使用的Pattern的某些部分是要生成句子的前缀(例如,短摘要这种提示),飞马在使用编码器处理时往往会简单地忽略这部分。
基于这一观察结果,我们用一个解码器前缀d来帮助每个模式P,该模型作为生成序列的一部分,而不是观察到的输入。因此,我们将y给定x的概率定义为
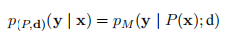
用一个实例说明,最开始的想法作者希望输入P(x)以及一个空解码前缀d。

之后作者经过调整,P(x)与d如下,且d在解码层作为提示输入:

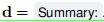
如果我们有多对(P1,d1),…,(Pk,dk)的patterns和解码器前缀,我们首先为每个(Pi,di)fintune一个单独的模型Mi,就像在常规PET中一样。为了将他们的知识结合起来并将其提炼成一个单一的模型M^,我们再次需要一组未标记的示例U。然而,我们需要一个不同于文本分类的模型结合方法,因为我们不能简单地对单个模型生成的所有序列取平均值。
相反,我们采用以下方法:对于每个x∈U,我们首先使用贪婪解码生成一个输出序列y(Pi,di),从而产生一组候选摘要输出Cx={y(Pi,di)|1≤i≤k}。然后我们给每个候选的y∈Cx分配一个分数。为此,我们首先计算对于每个(Pi,di),y的归一化对数似然值为:
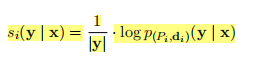
其中我们除以长度y来纠正长度偏差。最终每个(pi,di)候选摘要的分数进行平均
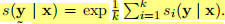
最后对最终的模型M^进行成对(x,y)的训练,其中x∈U和y从Cx={y(Pi,di)|1≤i≤k}中抽取,且概率与s(y|x)成正比。
作者认为这样我们可以训练最终的模型来简单地最大化pM^(y|x),但我们注意到这在预训练和微调之间造成了强烈的差异:y因为在预训练中,飞马模型处理的都是包含至少一个mask token的序列。本着我们意图使预训练和微调尽可能相似的精神,因此我们使用一个基础的Pattern P(x)=__x来训练M ^。
Exp
set up
PEGASUS:常规的finetune程序。
PEGASUS-M:用一个最简单的Pattern进行训练与fintune,例如P(x)=__x,且不引入解码器前缀。
PEGASUS-PET:使用PET对上述所有pattern进行微调,且作者为每种数据集均设计了两个前缀:

1.主实验

考虑到所有任务的R1/R2/RL分数和训练集的大小;所有的结果都在三个不同设置的训练集(zeroshot,10shots,100shots)上取平均值。最后一列显示了所有数据集上的平均性能。
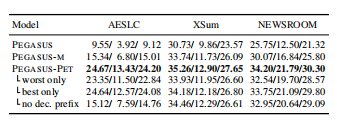
作者使用训练中最好的与最差的Pattern进行训练,发现结果还是优于基线,说明前缀(prefix)的重要性。且作者简单组合训练效果最佳。
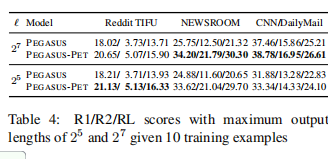
作者讨论了前缀是否会随着输出长度变短而减弱,结果发现前缀对长摘要也有着不错的效果。















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









