







以前优化都是使用的SGD,今天学习了几种更好的优化方法(momentum、Nesterov、Adagrad、RMSProp、Adam),这里将它们的原理和自己的理解记录下来,
SGD(stochastic gradient descent)
随机梯度下降法,即随机抽取一批样本,根据这批样本进行梯度下降,其实为梯度下降的batch版本,之前的作业都是用的这种方法。工作过程为:

其中α为学习率,不断计算当前batch的梯度,然后进行更新,这种方式的更新完全依赖于当前的梯度。
缺点:
1. 难以选择合适的学习率,易出现如下震荡的效果,收敛非常慢。

2. SGD容易收敛到局部最优,有时可能会被困在局部最小与鞍点。

SGD+Momentum
这种方法是在SGD的基础上加上了动量项,以它模拟物体运动的惯性,这样在进行参数更新时有两个参数,分别是上次更新的速度方向以及当前位置梯度方向,增加了稳定性,同时在到达鞍点时也会因为惯性而通过不会被困住,因此学习得更快。


ρ为momentum系数,α为学习率,它们控制两个方向对最后结果的影响程度。
下降初期时,使用上一次参数更新,下降方向一致,乘上较大的ρ,能够进行很好的加速;
下降中后期时,在来回震荡的时候,动量方向与速度方向不同,速度方向对梯度下降的方向进行修正,由此更快收敛。

由上图可以看到,加上动量项后,SGD存在的问题都得到一定程度的改善。
Nesterov Momentum
这是对传统Momemtum方法的改进,由下图可以看出两者的区别,Momentum使用当前位置梯度而Nesterov使用预估下个位置的梯度进行update。

因此update的式子改为:

经过变量代换:

相对于momentum的改变已经框了出来,对位置的预测也开始与速度有关,该项在梯度更新时做一个校正,提高自身的灵敏度,如下图可见Nesterov在拥有了“超前的眼光”后,波动小了很多。

看到上面这几种优化的方式都需要设定学习率,所有的参数使用同一个更新速率,但同一个更新速率不一定适合所有参数。如有的参数已经到了需要微调的阶段,而又有的参数由于对应样本少等原因,还需要大幅度的调动。下面便是几种自适应学习率的优化方法。
AdaGrad
AdaGrad自适应地为各个参数自适应分配一个学习率。
\[\Delta {{\text{x}}_t} = - \frac{\alpha }{{\sqrt {\sum\limits_{\tau = 1}^t {dx_\tau ^2 + \varepsilon } } }}d{x_\tau }\]

其中α为初始定义的学习率,dx为当前梯度。ε为一个很小的数字,保证分母不为零。我们可以看到,由于grad_squared的累加作用,当当前梯度较小时,学习率减小得更慢;反之如果当前梯度较大,那么学习率也会因为除以一个较大的数字而迅速减小。
为每个参数都保留一个学习率以此提升在稀疏梯度(自然语言、计算机视觉)上的性能。
不过AdaGrad也存在几个问题:
1.grad_squared单调递增,因此学习率将单调递减,训练后期网络的更新能力越来越弱,能学习能力也越来越弱。
2.初始学习率仍需要我们自行设置。
RMSProp
RMSProp针对上述AdaGrad的第一个问题进行了改进,这里我直接放上两者的公式,大家比较即可发现区别:
AdaGrad: 
grad_squared += dx * dxRMSProp: 
grad_squared = decay_rate * grad_squared + (1 - decay_rate) * dx *dxRMSProp的梯度更新不再仅仅依赖于此前的grad_squard,而是将其与当前位置梯度平方取加权和,decay_rate会不断对历史累计grad_squared进行衰减,为每一个参数适应性地保留学习率,一定程度上解决了AdaGrad单调递增的问题,在非稳态问题上有优秀性能。

Adam
Adam可以看作是Momentum与RMSProp的结合,充分利用了一阶与二阶矩均值,因此适用于解决大噪声和稀疏梯度的非稳态(non-stationary)问题。

具体来看,Adam计算了梯度的移动均值,而超参数beta1、beta2控制这些移动均值的衰减率。
推荐的默认参数与Tensorflow中都设定为:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
beta1 beta2初始值接近1,因此初始矩估计得偏差接近与0,偏差通过计算带偏差的估计与偏差修正后的估计而提升。也因为偏差修正使其在梯度稀疏时表现更为优秀。
CS231n中也推荐它作为默认的优化算法。
最后放一张图镇楼啦
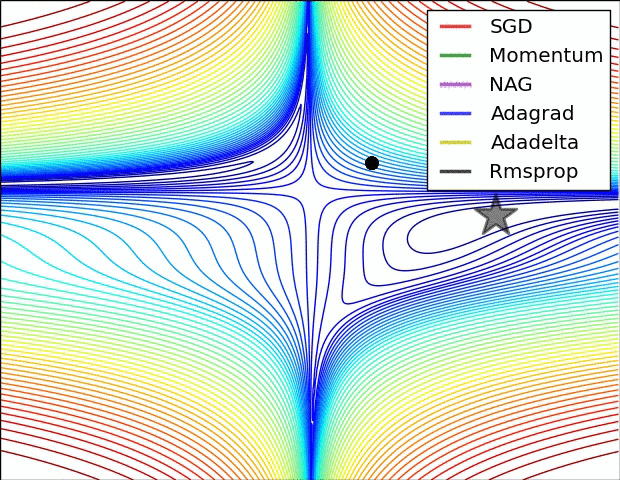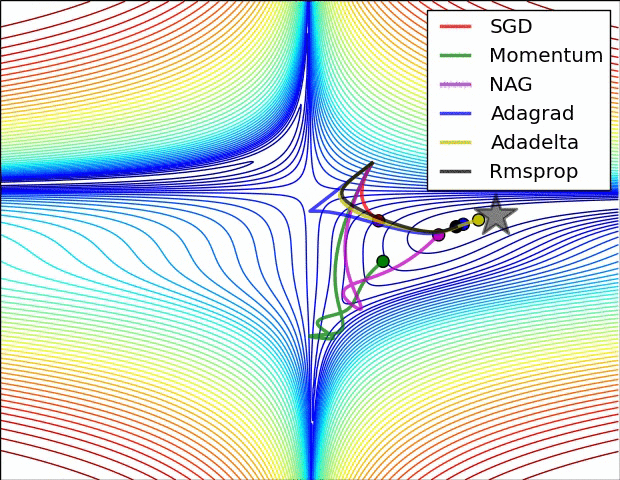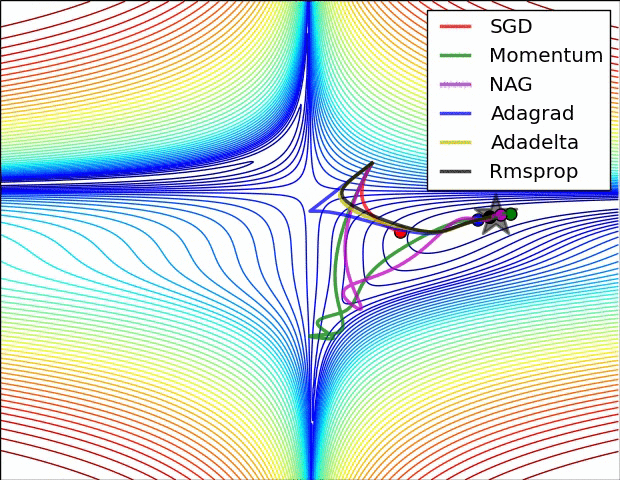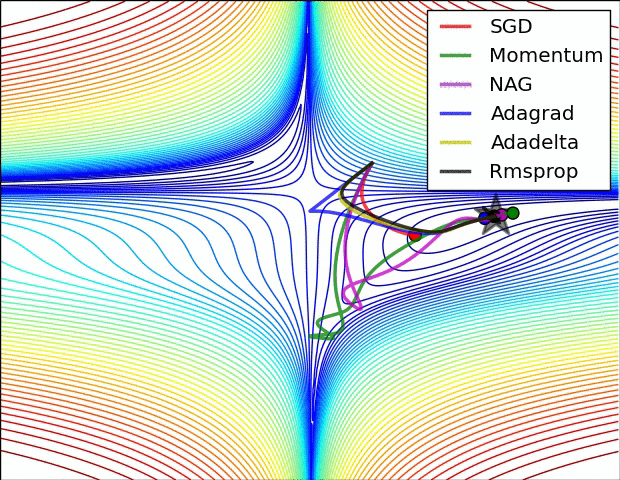















 7111
7111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









