







一、前言
分库分表是在不得已的情况下使用数据库的策略,如果系统没必要分库分表,最好不要使用。因为分库分表对于查询极度不友好,不管从资源的开销,但是数据的查询,数据的管理,计算等都是不好的。在大规模系统中只有出现不停增长的大数据,超过亿级的单表数据量才考虑分库分表。比如订单数据,比如超过一个亿的用户数据,比如交易数据等这些才用分库分表。这也是不得已的,因为不分表,数据量达到一定的量级,比如10亿,查数据的速度将指数级下降。
二、如何做分库
一般分库以业务来分库最好,在库里再进行分表。一般需要分表才需要分库。有时候只是一两种数据需要分表就无需分库,关联性太多的表不易在不同的库,或者最好不要分库。
比如订单 ,交易数据库我们可以放在A库。用户数据,配置信息,后台管理数据我们放在B库。A库的订单,交易数据能与A库关联的无非是用户数据。我们就可以在A库中对订单数据,和交易数据进行分表。而B库完全不需要分表。这便于管理。

三、如何分表
订单表的分表,这其实就是一种 水平分表 。因为订单表随着时间的积累,数据会越来越多,到那时候一个订单表的查询和写入会变得特别的慢。例如现在订单表有200亿条数据,但是水平分表成1024张表,每张表大概只有2000万条数据,这个时候的查询与写入操作效率还是很好的。
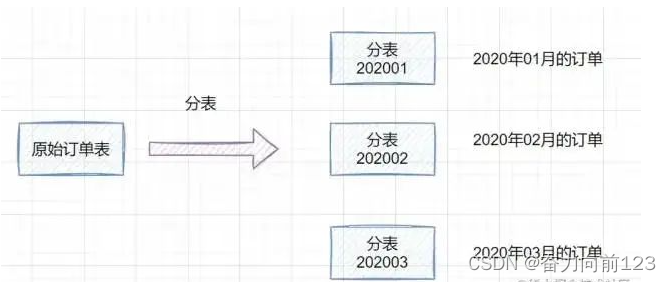
四、分库分表框架与应用
分库分表是数据库架构优化的常用手段,用于解决单库或单表在数据量增大、访问频率提高时遇到的性能瓶颈。以下是一些常见的分库分表框架以及它们的应用场景:
- 分库分表框架:
- Sharding-JDBC:这是一个轻量级的Java框架,提供数据分片、读写分离、分布式主键等功能。它支持多种分片策略,并可以无缝地与Spring Boot等主流框架集成。
- MyCAT:MyCAT是一个开源的、支持自动分片、读写分离、多数据源整合的数据库中间件。它提供了全局序列、全局表、ER关系等功能,简化了分库分表的复杂度。
- Vitess:Vitess是YouTube开源的一个数据库集群解决方案,它提供了水平分片、读写分离、故障转移等功能。Vitess特别适用于大规模、高并发的在线服务。
- 应用场景:
- 数据量巨大:当单表数据量达到千万级甚至亿级时,查询效率会显著下降,此时可以考虑使用分库分表来提高性能。
- 高并发访问:对于大型互联网应用,数据库可能面临极高的并发访问压力。分库分表可以分散请求,减轻单库或单表的负载。
- 业务模块拆分:在某些场景下,可以根据业务模块将数据拆分到不同的库中,以便进行独立的管理、维护和监控。
- 数据安全性与隔离性:分库分表可以提高数据的安全性,防止数据泄露和非法访问。同时,不同业务的数据可以相互隔离,避免相互影响。
总之,分库分表框架在解决数据库性能瓶颈方面发挥着重要作用。在应用时,需要根据具体业务场景和需求选择合适的框架和策略。同时,分库分表也带来了一些复杂性,如数据一致性、跨库查询等问题,需要在设计和实现时进行充分考虑。
五、springboot使用Sharding-JDBC
在Spring Boot中使用Sharding-JDBC进行分库分表主要需要以下几个步骤:
- 添加依赖
在Spring Boot项目的pom.xml文件中添加Sharding-JDBC的依赖。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>你的Sharding-JDBC版本号</version>
</dependency>确保你使用的是与你的Spring Boot版本兼容的Sharding-JDBC版本。
- 配置数据源和分片策略
在application.yml或application.properties文件中配置数据源、分片键和分片策略。
以application.yml为例:
spring:
shardingsphere:
datasource:
names: ds0,ds1 # 配置数据源名称,与下面的数据源配置对应
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/ds0
username: root
password: password
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/ds1
username: root
password: password
rules:
sharding:
tables:
your_table: # 配置分片的表名
actual-data-nodes: ds$->{0..1}.your_table$->{0..1} # 数据节点配置,表示分两个库两个表
table-strategy:
inline:
sharding-column: id # 分片键
algorithm-expression: your_table$->{id % 2} # 分片算法
key-generator:
type: SNOWFLAKE # 主键生成策略
column: id
binding-tables: # 绑定表,用于多表联合查询
- your_table
default-data-source-name: ds0 # 默认数据源
default-table-strategy: # 默认表策略,当未配置分片策略的表使用
none:
props:
sql-show: true # 是否打印SQL语句
上面的配置中,我们定义了两个数据源ds0和ds1,并且配置了表your_table的分片策略。这里使用了内联分片算法,将id字段的值对2取模,决定数据应该存储在哪个表中。
- 创建实体类和Mapper
创建对应的实体类(Entity)和MyBatis的Mapper接口。
@Data
public class YourTable {
private Long id;
// 其他字段...
}
public interface YourTableMapper {
// Mapper方法...
}- 使用Mapper
在Service或Controller中注入Mapper,并正常使用。
@Service
public class YourTableService {
@Autowired
private YourTableMapper yourTableMapper;
// 业务逻辑...
}- 启动应用
启动Spring Boot应用,Sharding-JDBC将会根据配置自动进行分库分表操作。
请注意,这只是一个简单的示例,实际使用中可能需要根据业务场景调整分片策略、数据源配置以及其他相关设置。另外,当进行分库分表时,还需要考虑事务管理、跨库联合查询等问题。Sharding-JDBC提供了一些解决方案,例如使用广播表或绑定表来处理跨库查询的场景。
在进行分库分表之前,建议详细了解业务需求、数据量、访问模式等,并仔细规划和测试分片策略,以确保系统的稳定性和性能。
















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











