







11 Hadoop NameNode HA
11.1 概述
HDFS 2.x
解决 HDFS 1.0 中单点故障和内存受限问题,联邦 HA
HDFS2.x 中 Federation 和 HA 分离,HA 只能有两个 NameNode
解决单点故障
HDFS HA:通过主备 NameNode 解决
如果主 NameNode 发生故障,则切换到备 NameNode 上。
解决内存受限问题
HDFS Federation(联邦);水平扩展,支持多个 NameNode;
(1)所有 NameNode 共享所有 DataNode 存储资源
(2)每个 NameNode 分管一部分目录;
11.1.1 手动 HA
fsimage+edits log 需要

由 StandbyNameNode 做合并工作
| fsimage 推送的时机可以通过参数来调整: dfs.namenode.checkpoint.period 1 小时 dfs.namenode.checkpoint.txns 100 0000 事务 dfs.namenode.checkpoint.check.period 3s dfs.namenode.num.checkpoints.retained dfs.ha.tail-edits.period |
1、一个 NameNode 进程处于 Active 状态,另 1 个 NameNode 进程处于 Standby 状态。Active 的 NameNode 负责处理客户端的请求。
2、Active 的 NN 修改了元数据之后,会在 JNs 的半数以上的节点上记录这个日志。Standby 状态的 NameNode 会监视任何对 JNs 上 edit log 的更改。一旦 edits log出现更改,Standby 的 NN 就会根据 edits log 更改自己记录的元数据。
3、当发生故障转移时,Standby 主机会确保已经读取了 JNs 上所有的更改来同步它本身记录的元数据,然后由 Standby 状态切换为 Active 状态。
4、为了确保在发生故障转移操作时拥有相同的数据块位置信息,DNs 向所有 NN 发送数据块位置信息和心跳数据。
5、JNs只允许一台NameNode向JNs写edits log数据,这样就能保证不会发生“脑裂”。
11.1.2 自动 HA

11.1.3 总结
主备 NameNode
解决单点故障(属性,位置)元数据
主 NameNode 对外提供服务,备 NameNode 同步主 NameNode 元数据,以待切换
所有 DataNode 同时向两个 NameNode 汇报数据块信息(位置)
JNN:集群(属性)同步 edits log
standby:备,完成了 edits.log 文件的合并产生新的 fsimage,推送回 ANN
两种切换选择
手动切换:通过命令实现主备之间的切换,可以用 HDFS 升级等场合
自动切换:基于 Zookeeper 实现
基于 Zookeeper 自动切换方案
ZooKeeper Failover Controller:监控 NameNode 健康状态,并向 Zookeeper
注册 NameNode。NameNode 挂掉后,ZKFC 为 NameNode 竞争锁,获得 ZKFC 锁的
NameNode 变为 active
zookeeper 的分布式锁,keepalived
11.2 NameNode 自动 HA 集群搭建
11.2.1 规划

11.2.2 搭建步骤
如何让 ssh 不提示 fingerprint 信息,然后输入 yes 或者 no
/etc/ssh/ssh_config(客户端配置文件) 区别于 sshd_config(服务端配置文件)
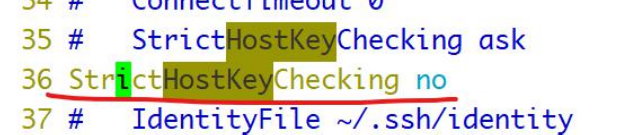
11.2.2.1 四台服务器之间免密登录
四台服务器之间互相均可以免密登录
a、 首先在四台服务器上都要执行:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsab、在 node1 上将 node1 的公钥拷贝到 authorized_keys 中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给 node2:
scp ~/.ssh/authorized_keys node2:/root/.ssh/c、在 node2 中将 node2 的公钥追加到 authorized_keys 中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给 node3:
scp ~/.ssh/authorized_keys node3:/root/.ssh/d、在 node3 中将 node3 的公钥追加到 authorized_keys 中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给 node4:
scp ~/.ssh/authorized_keys node4:/root/.ssh/e、在 node4 中将 node4 的公钥追加到 authorized_keys 中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将该文件拷贝给 node1、node2、node3:
scp ~/.ssh/authorized_keys node1:/root/.ssh/
scp ~/.ssh/authorized_keys node2:/root/.ssh/
scp ~/.ssh/authorized_keys node3:/root/.ssh/11.2.2.2 JDK 安装环境变量配置
首先将 node1 中的 hadoop-2.6.5 删除,或者通过快照还原到单机伪分布安装前的环境。
node1-node4
mkdir /opt/apps将 jdk-8u221-linux-x64.rpm 上传到 node1/opt/apps
将/opt/apps 下的 jdk.rpm scp 到 node2、node3、node4 的对应目录中
scp jdk-8u221-linux-x64.rpm node2:/opt/apps
scp jdk-8u221-linux-x64.rpm node3:/opt/apps
scp jdk-8u221-linux-x64.rpm node4:/opt/apps在 node1、node2、node3、node4 上安装 jdk 并配置 profile 文件
rpm -ivh jdk-8u221-linux-x64.rpmnode1 上修改环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin将 node1 的/etc/profile 拷贝到 node2、node3、node4 上并执行. /etc/profile
scp /etc/profile node[234]:`pwd`11.2.2.3 zookeeper 集群搭建
a) 将 zookeeper.tar.gz 上传到 node2
b) 解压到/opt
tar -zxvf zookeeper-3.4.6.tar.gz -C /optc) 配置环境变量:
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin然后./etc/profile 让配置生效
最后将该文件 scp 到 node3 和 node4 上,并分别./etc/profile 让配置生效.
scp /etc/profile bk3:/etc/
scp /etc/profile bk4:/etc/d) 到$ZOOKEEPER_PREFIX/conf 下
复制 zoo_sample.cfg 为 zoo.cfg
cp zoo_sample.cfg zoo.cfge) 编辑 zoo.cfg
添加如下行:
server.1=node2:2881:3881
server.2=node3:2881:3881
server.3=node4:2881:3881修改
dataDir=/var/bjsxt/zookeeper/dataf) 创建/var/bjsxt/zookeeper/data 目录,并在该目录下放一个文件:myid
在 myid 中写下当前 zookeeper 的编号
mkdir -p /var/bjsxt/zookeeper/data
echo 1 > /var/bjsxt/zookeeper/data/myidg)将配置好 zookeeper 拷贝到 node3、node4 上
scp -r zookeeper-3.4.6/ bk3:/opt/
scp -r zookeeper-3.4.6/ bk4:/opt/h) 在 node3 和 node4 上分别创建/var/bjsxt/zookeeper/data 目录,并在该目录下放一个文件:myid
node3
mkdir -p /var/bjsxt/zookeeper/data
echo 2 > /var/bjsxt/zookeeper/data/myidnode4
mkdir -p /var/bjsxt/zookeeper/data
echo 3 > /var/bjsxt/zookeeper/data/myidi) 分别启动 zookeeper
| zkServer.sh start 启动 zk zkServer.sh stop 停止 zk zkServer.sh status 查看 zk 状态 zkServer.sh start|stop|status |
j) 关闭 zookeeper
| zkServer.sh stop |
l) 连接 zookeeper
| zkCli.sh node2、node3、node4 都可以 |
m) 退出 zkCli.sh 命令
| quit |
11.2.2.4 hadoop 配置
在 一律在 node1 上操作,做完后 scp 到 到 node2 、node3 、node4
1. hadoop-env.sh 配置 JDK
export JAVA_HOME=/usr/java/default2. 修改 slaves 指定 datanode 的位置
[root@node1 hadoop]# vim slaves
node2
node3
node43. core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/bjsxt/hadoop/ha</value>
</property>
<!-- 指定每个 zookeeper 服务器的位置和客户端端口号 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>4. hdfs-site.xml
<configuration>
<!-- 指定副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 解析参数 dfs.nameservices 值 hdfs://mycluster 的地址 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster 由以下两个 namenode 支撑 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 指定 nn1 地址和端口号 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<!-- 指定 nn2 地址和端口号 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<!-- 指定客户端查找 active 的 namenode 的策略:
会给所有 namenode 发请求,以决定哪个是 active 的 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定三台 journal node 服务器的地址 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bjsxt/hadoop/ha/jnn</value>
</property>
<!-- 当 active nn 出现故障时,ssh 到对应的服务器,将 namenode 进程 kill 掉-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!--启动 NN 故障自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>5. 先同步配置文件到 node2、node3、node4
node1 上执行:
[root@node1 opt]# tar -zcvf hadoop-2.6.5.tar.gz hadoop-2.6.5/
[root@node1 opt]# scp hadoop-2.6.5.tar.gz node2:/opt/apps/
[root@node1 opt]# scp hadoop-2.6.5.tar.gz node3:/opt/apps/
[root@node1 opt]# scp hadoop-2.6.5.tar.gz node4:/opt/apps/node2、node3、node4 分别执行解压:
tar -zxvf /opt/apps/hadoop-2.6.5.tar.gz -C /opt/Hadoop 环境变量配置:
node1 上:
[root@node1 opt]# vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.6.5
export
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinnode2 上:
[root@node1 opt]# vim /etc/profile
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.6
export HADOOP_HOME=/opt/hadoop-2.6.5
export
PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@node1 opt]#source /etc/profile
[root@node1 opt]# scp /etc/profile bk3:/etc/
[root@node1 opt]# scp /etc/profile bk4:/etc/node3、node4 分别执行:
source /etc/profile11.2.2.5 启动 ha 的 hdfs
a) 启动 zookeeper 集群, node2、node3、node4 分别执行:
zkServer.sh startb) 在 node1\node2\node3 上启动三台 journalnode
hadoop-daemon.sh start journalnodec) 选择 node1,格式化 HDFS
hdfs namenode -format/var/bjsxt/hadoop/ha/dfs/name/current/目录下产生了 fsimage 文件格式化后,启动 namenode 进程
hadoop-daemon.sh start namenoded) 在另一台 node2 上同步元数据
hdfs namenode -bootstrapStandby出现以下提示:
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://node1:50070
Other NN's IPC address: node1/192.168.20.201:8020
Namespace ID: 178118551
Block pool ID: BP-1909026874-192.168.20.201-1577760263511
Cluster ID: CID-8105daf4-bdbb-40e8-a9d0-8d3f3867535b
Layout version: -60
isUpgradeFinalized: true
=====================================================e) 初始化 zookeeper 上的内容 一定是在 namenode 节点(node1 或 node2)上。
执行格式命令之前在 node2-node4 任一节点上:
[root@node4 hadoop]# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]只有默认的一个节点。
接下来在 node1 上执行:
[root@node1 ~]# hdfs zkfc -formatZK然后在 node4 上接着执行:
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha
[mycluster]
[zk: localhost:2181(CONNECTED) 3] ls /hadoop-ha/mycluster
[]f) 启动 hadoop 集群,可在 node1 到 node4 这四台服务器上任意位置执行
[root@node1 ~]# start-dfs.shnode4 上:
[zk: localhost:2181(CONNECTED) 5] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 6] get
/hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2node2 �>(�>
cZxid = 0x500000007
ctime = Tue Dec 31 11:04:24 CST 2019
mZxid = 0x500000007
mtime = Tue Dec 31 11:04:24 CST 2019
pZxid = 0x500000007
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x26f599f159b0000
dataLength = 27
numChildren = 0node2 占用着锁,它的状态是 active 的

node1 为 standby

将 node2 上 namenode 进程 kill 掉:
[root@node2 hadoop]# jps
1970 Jps
1158 QuorumPeerMain
1335 JournalNode
1546 DataNode
1660 DFSZKFailoverController
1871 NameNode
[root@node2 hadoop]# kill -9 1871
[root@node2 hadoop]# jps
1158 QuorumPeerMain
1335 JournalNode
1546 DataNode
1980 Jps
1660 DFSZKFailoverControllernode4 上继续:
[zk: localhost:2181(CONNECTED) 10] get
/hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2node1 �>(�>
cZxid = 0x50000000bnode2 访问不了,node1 变为 active。
node2 上再次启动 namenode:
[root@node2 hadoop]# hadoop-daemon.sh start namenodenode2 依然为 standby。变为备机。
node1 上停掉 zkfc 执行:
[root@node1 hadoop]# hadoop-daemon.sh stop zkfc或
[root@node1 hadoop]# jps
1158 QuorumPeerMain
1335 JournalNode
1546 DataNode
2012 NameNode
1660 DFSZKFailoverController
2111 Jps
[root@node1 hadoop]# kill -9 1660
[root@node1 hadoop]# jps
1158 QuorumPeerMain
1335 JournalNode
2136 Jps
1546 DataNode
2012 NameNodenode2 变为 active 状态
stop-dfs.sh 停止 hadoop 服务。
node1 上编写 zk、hdfs 启动脚本
[root@node1 ~]# vim starthdfs.sh
#!/bin/bash
for node in node2 node3 node4
54
do
ssh $node "source /etc/profile;zkServer.sh start"
done
sleep 1
start-dfs.sh
echo "-------node1 jps-----"
jps
for nd in node2 node3 node4
do
echo "-------$nd jps-----"
ssh $nd "source /etc/profile;jps"
done
:wq
[root@node1 ~]# chmod +x starthdfs.sh
[root@node1 ~]# cp starthdfs.sh stopdfs.sh
[root@node1 ~]# vim stopdfs.sh
#!/bin/bash
stop-dfs.sh
sleep 1
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh stop"
done
echo "-------node1 jps-----"
jps
for nd in node2 node3 node4
do
echo "-------$nd jps-----"
ssh $nd "source /etc/profile;jps"
done
:wq如果格式化之后,启动:
启动三台 zk
随意节点:start-dfs.s
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop zkfc
11.2.2.6 zookeeper 操作
在 node2 或者 node3 或者 node4 上运行
zkCli.sh
ls /hadoop-ha/mycluster 查看临时文件
get /hadoop-ha/mycluster/ActiveStandbyElectorLock 查看临时文件的内容
退出 zkCli.sh
quit
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











