







Java内存模型及线程实现案例分析
-- 1、Java内存模型
- 了解操作系统CPU的内存模型
- 了解Java的内存模型
- 熟悉指令重排和Happens-before
为什么讲内存模型
- 了解更深层次内存的使用和读取实现,方便日后分析多线程内存相关问题。
- 工作中遇到的并发问题,并不好重现,需要对理论知识掌握足够深刻,才能更好分析。
操作系统内存模型

L1和L2是每个CPU自己的高速缓存
L3是多个CPU之间共享的缓存
理解:L1办公桌上的文件,L2抽屉里的文件,L3公司内部共享文件

L1和L2的缓存命中率均约为 80%
L3 达到L3缓存的数据占比4%左右
Java内存模型

每个线程有自己的工作内存
工作内存包含线程本地的局部变量和主内存的副本拷贝
线程之间的共享变量通过主内存在各线程间同步

- 线程工作内存的值写入到主内存,另一个线程从主内存读取这个值
- 由于可见性问题,另一个线程拿到的值并不是实时的。
重排序


Happens-before规则
- 程序次序规则:在程序中若操作A先于操作B发生,那么线程中操作A也先于操作B发生
- 对象终结规则:一个对象的构造函数的完成先行发生于其finalize()方法
- 锁规则:对同一个锁,加锁操作先行发生于解锁
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则操作A先行发生于操作C
- volatile变量规则:对于一个volatile变量的写操作先行发生于对这个变量读操作
- 线程启动规则:Thread对象的start()方法先行发生于此线程中的每一个指令操作
- 线程中断规则:一个线程对另一个线程调用interrupt()方法,先行发生于被中断线程检测到中断事件
- 线程结束规则:线程中所有的操作都先行发生于线程终止,如线程结束、Thread.join()返回
-- 2、synchronized和volatile关键字
- 了解synchronized关键字的实现和使用
- 了解volatile关键字的存取规则
- 了解synchronized和volatile关键字的区别
synchronized是什么
synchronized是java语言关键字,用来给方法或代码块加锁,控制方法或代码块同一时间只有一个线程执行,用来解决多个线程同时访问时出现的并发问题。
synchronized使用分类
synchronized方法
- 方法使用ACC_SYSNCHRONIZEDB标识
- 如果是static方法,锁是作用在类上的(多线程串行)
- 如果是非statics方法,锁作用在具体的类对象上(多线程并行)
synchronized代码块
使用monitorenter和monitorexit指令控制线程进出
Sychronized和ReentrantLock
相同点
- 都是用于多线程中对资源加锁,控制代码同一时间只有单个线程在执行
- 当一个线程获取了锁,其他线程均需要阻塞等待
- 均为可重入锁
不同点
- synchronized是java语言的关键字,由虚拟机指令实现
ReentrantLock是java sdk提供的API级别锁实现
- synchronized可以在方法级别锁,ReentrantLock则不行
- ReentrantLock可以通过方法tryLock等待指定时间的锁,超时返回,synchronized则不行
- ReentrantLock提供了公平锁和非公平锁实现,synchronized只有非公平锁
说明:
公平锁:队列中等待执行的线程,按排队顺序逐个执行
非公平锁:等待执行的线程同时竞争CPU资源
可重入锁?
Volatile是什么

Volatile是java语言的关键字,也是一个指令的关键字
- 用来保证多线程间对变量的内存可见性,将最新变量值及时通知给其它线程
- 禁止volatile前后的程序指令重排序
- 不保证线程安全,不可用于数字的线程安全递增。
Volatile使用场景
- 修饰状态变量
用于线程间访问该变量,保证各线程看到最新的内存值

2、单实例对象构造
避免多线程情况下由于内存不可见而重复多次构造对象

Synchronized和volatile区别
- synchronized是用于同步锁控制,具有原子性,控制同一时间只有一个线程执行一个方法或代码块
- Volatile只保证线程间的内存可见性,不具备锁的特征,无法保证修饰对象的原子性
小结
- 了解synchronized和volatile的概念和常见用法
- 本质上对两个关键字进行区分,避免错用乱用
思考
不适用synchronized等锁同步控制,怎么构造单实例对象?
-- 3、创建线程的几种方式
- 了解创建线程的几种方式
- 了解线程的执行过程
- 了解Future获取线程结果的过程
线程创建方式一
通过Runnable接口创建线程
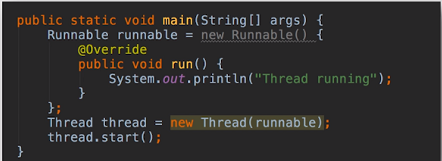
- 重写Runnable的run方法
- 使用runnable对象构造Thread对象
- 启动线程
线程创建方式二
继承Thread类创建线程

- 继承Thread类,重写run方法
- 构造这个Thread子类
- 调用start()方法启动线程
线程创建方式三
使用Callable和FutureTask创建线程

- 实现Callable接口,重写call方法
- 传入Callable对象,构造FutureTask(Runnable的子类)对象
- 传入FutureTask对象构造Thread对象,启动线程
线程创建方式四
将Runnable或者Callable放到线程池ExecutorService中执行

- 实现Callable/Runnable接口,重写call/run方法
- 构建ExcutorService线程池对象,调用线程池execute或者submit方法执行线程
- 对于submit方式提交,使用Future来获取线程执行结果
线程执行过程

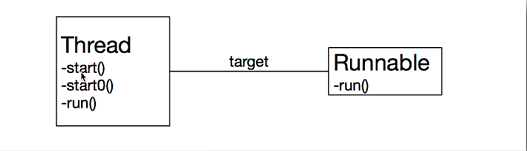
如何获取线程执行结果
上面的案例中FutureTask怎么获取结果?

- 从线程执行流程我们知道,最终是执行Runnable实现run方法
- 看FutureTask里的run方法
- FutureTask会维护线程的状态,在未完成时会一直等待直到完成
- FutureTask会把结果和异常等信息存储在对象内部变量中
- FutureTask支持超时获取结果,指定具体等待时间
小结
1、解了4中创建线程的方式
2、了解了线程的执行过程
3、分析源码,了解了线程执行结果的获取过程
思考
ExecutorService.submit(callable)是怎么获取执行结果的?
-- 4、ThreadLocal的定义和使用场景
- 了解ThreadLocal定义和用途
- ThreadLocal使用示例
什么是ThreadLocal?
ThreadLocal为解决多线程程序的并发问题提供了一种新的思路。使用这个工具类可以很简洁地编写出优美的多线程程序,ThreadLocal并不是一个Thread,而是Thread的局部变量。
(摘自百度百科)
没有ThreadLocal时
先看一下没有ThreadLocal的话,程序要怎么写?
模拟场景:HTTP服务端使用多线程处理来自不同用户的请求


总结
不使用ThreadLocal时,需在整个上下文调用的方法中将关键参数透传
存在的问题
- 从代码整洁度上看,每个方法要加这个参数,如果内部方法调用链路较长,那么方法入参看起来会很臃肿
- 如果某处透传时将参数值改掉或者设置为null,后续调用方法中用到这个参数的代码会受到影响
使用ThreadLocal改进
同样的场景:HTTP服务端使用多线程处理来自不同的用户请求



小结
- 理解了ThreadLocal的定义和用途
- 熟悉了ThreadLocal的使用场景和代码写法
思考
本节的场景中,除了使用ThreadLocal的方式,还有什么其他途径达到相同目的?
-- 5、ThreadLocal的实现原理
- 了解java的四种引用方式
- 了解ThreadLocal的数据结构
- 了解ThreadLocal的实现原理
- 了解ThreadLocal误用引起的OOM问题
Java四种引用关系

弱引用示例




ThreadLocal数据结构


ThreadLocal实现原理

- Entry对象,key为ThreadLocal,为弱引用
- value为真实要存储的对象
- key本身不会存储内容,只是用来做哈希寻找table的下标和key一致判断。
ThreadLocal OOM问题避免
- 在使用ThreadLocal时,都要在线程全部执行完成之后在finally代码块中调用remove()方法,清除内存(线程池中使用要尤为注意)
- 保存在ThreadLocal的数据不要太大
思考
在你使用过的哪些中间件中,ThreadLocal是怎样扮演着重要的角色?
















 9496
9496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











