






在如今AI无处不在的时代,许多人认为AI已经无所不能了。
AI代写文章、代写代码、AI绘画甚至AI制作PPT等功能,可能会让你觉得AI已经超越了人类。
然而,最新的一个研究表明,AI在处理一些简单的逻辑推理问题时,水平甚至还不如小学生。
这就是“爱丽丝梦游仙境”测试,研究人员设计了一项名为“爱丽丝梦游仙境”(AIW)的测试。

这个测试对我们来说并不算难:“爱丽丝有N个兄弟,她还有M个姐妹,请问爱丽丝的兄弟有多少个姐妹?”
只需稍加思考,答案显而易见:M+1(爱丽丝的姐妹数量加上爱丽丝自己)。
然而,当研究人员让当前最先进的语言模型如GPT-3.5/4、Claude、Llama等回答这个问题时,结果却令人吃惊。
论文地址:
https://arxiv.org/abs/2406.02061
GPT-4o

GPT3.5

LLaMa3-8B

再看一下国内的大模型表现如何。
讯飞星火

清华智浦GLM4

月之暗面Kimi
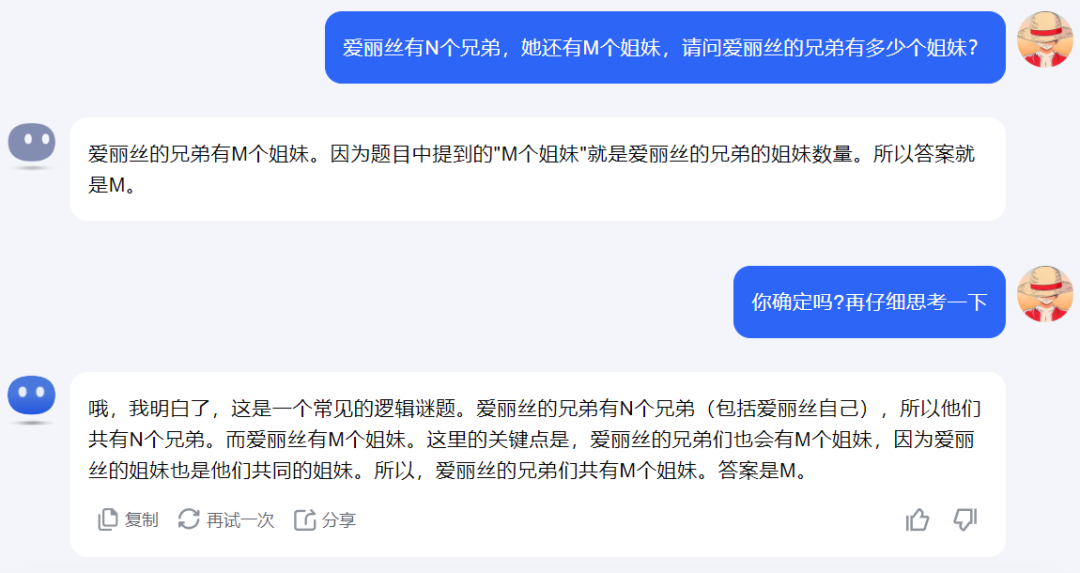
阿里通义千问2.5
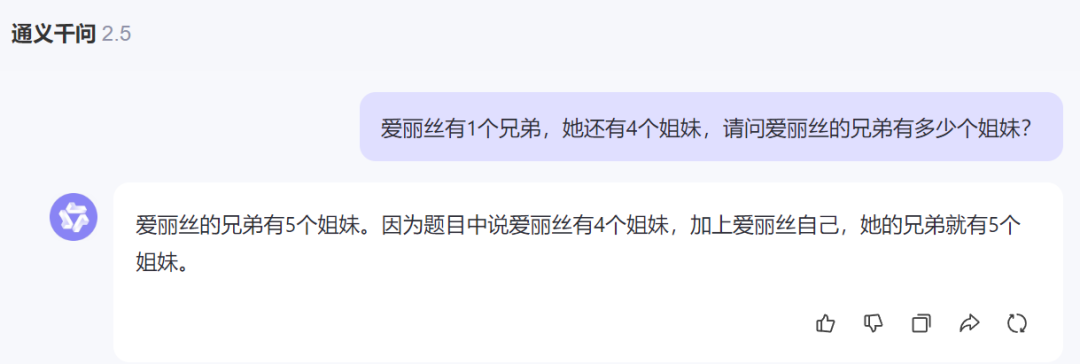
国内最新的大模型也有一半的回答是错误的。
这暴露了目前很多大模型在推理能力上的局限性。
来自知名开源AI研究机构LAION的团队发表了一个事实:即使是当今最先进的AI模型,其推理能力也几乎达不到小学生的水平。
LeCun,那个著名的AI大佬,在评论这一现象时也指出:推理能力和常识不应与存储和检索大量事实的能力混为一谈。
推理能力和搜索引擎不一样,很多大模型表现的好,有时会被认为是因为大模型学习了大量的知识,而这些知识被编码存储在了大模型的权重中。
这也是现在很多人在讨论的一点:大模型到底是自己创建了一个巨大的知识库用来索引,还是它真的学到了一些知识呢?
不知你怎看待这个问题呢?
我的技术专栏已经有几百位朋友加入了。
如果你也希望了解AI技术,学习AI视觉或者大语言模型,戳下面的链接加入吧,这可能是你学习路上非常重要的一次点击呀
最后,送一句话给大家:生活不止眼前,还有诗和远方,共勉~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











