







从主观的理解上,主成分分析到底是什么?它其实是对数据在高维空间下的一个投影转换,通过一定的投影规则将原来从一个角度看到的多个维度映射成较少的维度。到底什么是映射,下面的图就可以很好地解释这个问题——正常角度看是两个半椭圆形分布的数据集,但经过旋转(映射)之后是两条线性分布数据集。
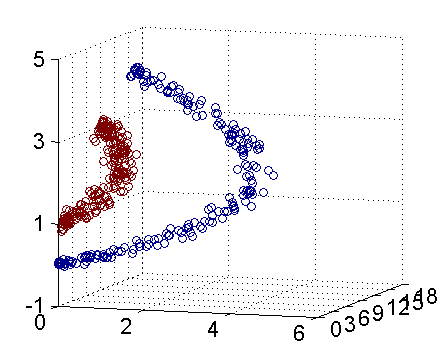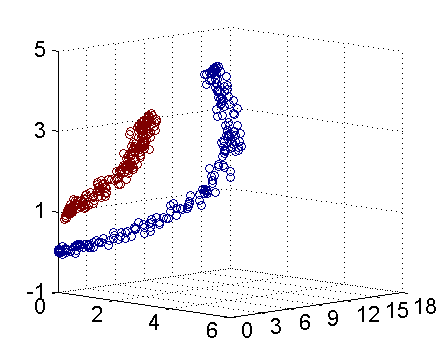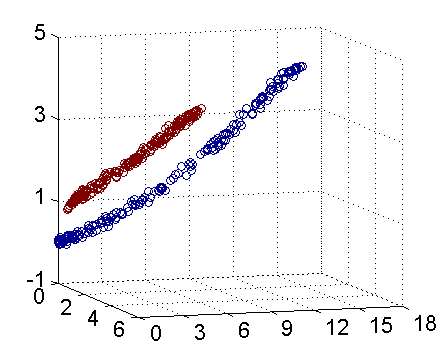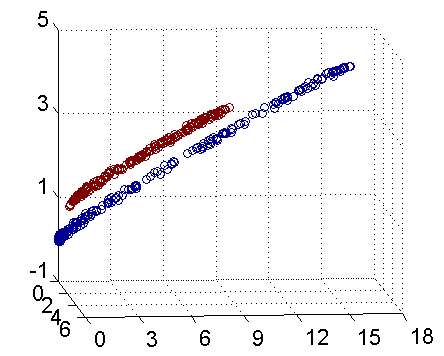
LDA与PCA都是常用的降维方法,二者的区别在于:
- 出发思想不同。PCA主要是从特征的协方差角度,去找到比较好的投影方式,即选择样本点投影具有最大方差的方向( 在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。);而LDA则更多的是考虑了分类标签信息,寻求投影后不同类别之间数据点距离更大化以及同一类别数据点距离最小化,即选择分类性能最好的方向。
- 学习模式不同。PCA属于无监督式学习,因此大多场景下只作为数据处理过程的一部分,需要与其他算法结合使用,例如将PCA与聚类、判别分析、回归分析等组合使用;LDA是一种监督式学习方法,本身除了可以降维外,还可以进行预测应用,因此既可以组合其他模型一起使用,也可以独立使用。
- 降维后可用维度数量不同。LDA降维后最多可生成C-1维子空间(分类标签数-1),因此LDA与原始维度N数量无关,只有数据标签分类数量有关;而PCA最多有n维度可用,即最大可以选择全部可用维度。
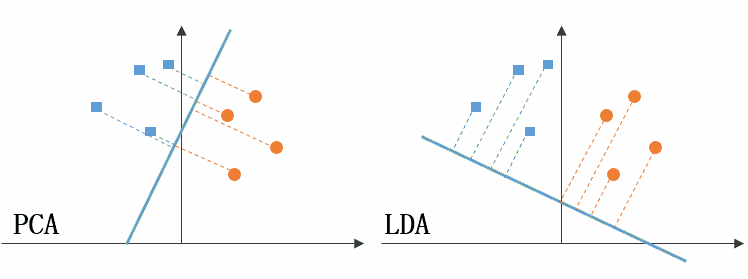
上图左侧是PCA的降维思想,它所作的只是将整组数据整体映射到最方便表示这组数据的坐标轴上,映射时没有利用任何数据内部的分类信息。因此,虽然PCA后的数据在表示上更加方便(降低了维数并能最大限度的保持原有信息),但在分类上也许会变得更加困难;上图右侧是LDA的降维思想,可以看到LDA充分利用了数据的分类信息,将两组数据映射到了另外一个坐标轴上,使得数据更易区分了(在低维上就可以区分,减少了运算量)。
线性判别分析LDA算法由于其简单有效性在多个领域都得到了广泛地应用,是目前机器学习、数据挖掘领域经典且热门的一个算法;但是算法本身仍然存在一些局限性:
- 当样本数量远小于样本的特征维数,样本与样本之间的距离变大使得距离度量失效,使LDA算法中的类内、类间离散度矩阵奇异,不能得到最优的投影方向,在人脸识别领域中表现得尤为突出
- LDA不适合对非高斯分布的样本进行降维
- LDA在样本分类信息依赖方差而不是均值时,效果不好
- LDA可能过度拟合数据

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









