






1、安装相应的库
import matplotlib.pyplot as plt # 用于可视化
from sklearn.cluster import KMeans # 用于聚类
import pandas as pd # 用于读取文件
2、聚类过程
2.1 读取数据并可视化
# 读取本地数据文件
df = pd.read_excel("./data/output3.xls", header=0)
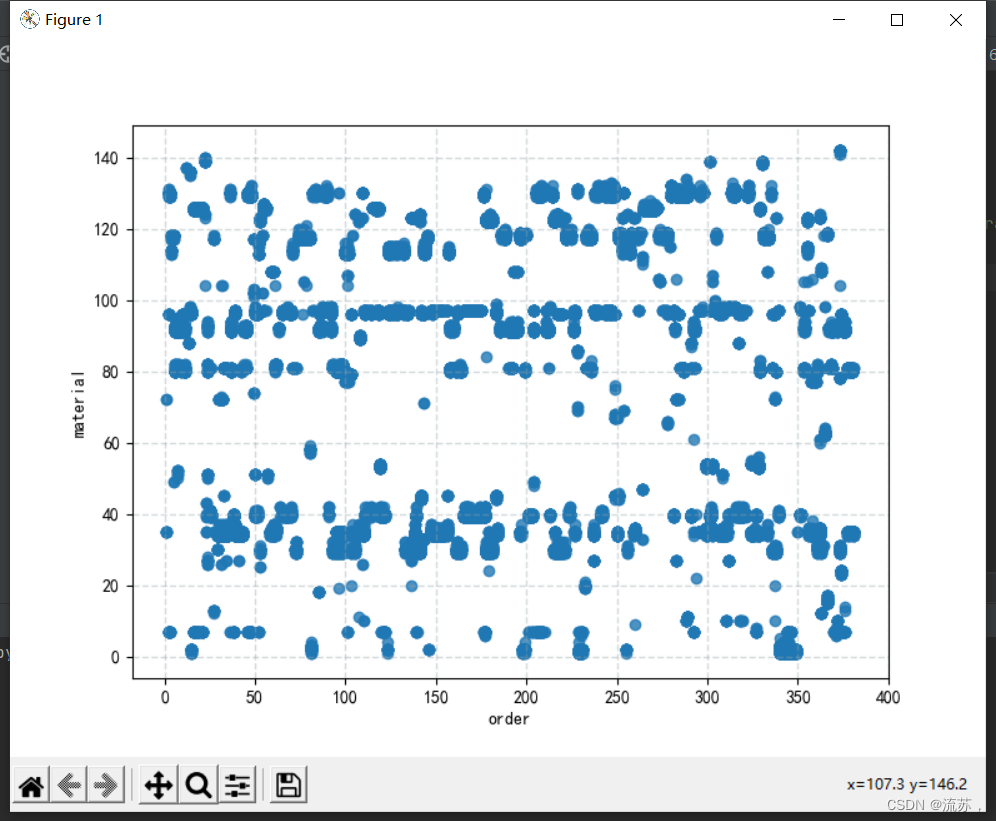
显示数据源的散点图:
plt.scatter(df["order"], df["material"], linewidths=1, alpha=0.8)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签v
plt.xlabel("order")
plt.ylabel("material")
plt.grid(color="#95a5a6", linestyle="--", linewidth=1, alpha=0.4)
plt.show()
以上选择数据源的“order”与“material”做聚类分析,结果如下:
2.2 K-means聚类分析
设置规定要聚的类别个数为5
data = df[["order","material"]] # 从原始数据中选择该两项
estimator = KMeans(n_clusters=5) # 构造聚类器
estimator.fit(data) # 将数据带入聚类模型
获取聚类中心的值和聚类标签
label_pred = estimator.labels_ # 获取聚类标签
centers_ = estimator.cluster_centers_ # 获取聚类中心
将聚类后的 label i的数据进行输出
x0 = data[label_pred == 0]
x1 = data[label_pred == 1]
x2 = data[label_pred == 2]
x3 = data[label_pred == 3]
x4 = data[label_pred == 4]
plt.scatter(x0["order"], x0["material"],c="red",s=10, linewidths=1, alpha=0.8,marker='.')
plt.scatter(x1["order"], x1["material"],c="green",s=10, linewidths=1, alpha=0.8,marker='.')
plt.scatter(x2["order"], x2["material"],c="blue", s=10,linewidths=1, alpha=0.8,marker='.')
plt.scatter(x3["order"], x3["material"],c="black",s=10, linewidths=1, alpha=0.8,marker='.')
plt.scatter(x4["order"], x4["material"],c="yellow", s=10,linewidths=1, alpha=0.8,marker='.')
plt.grid(c="#95a5a6", linestyle="--", linewidth=1, alpha=0.4)
#plt.savefig()
plt.legend()
plt.title("dataB5")#标题
plt.xlabel("order")#x坐标
plt.ylabel("material")#y坐标
plt.show()
















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









