









📣 📣 📣 📢📢📢
☀️☀️你好啊!小伙伴,我是小冷。是一个兴趣驱动自学练习两年半的的Java工程师。
📒 一位十分喜欢将知识分享出来的Java博主⭐️⭐️⭐️,擅长使用Java技术开发web项目和工具
📒 文章内容丰富:覆盖大部分java必学技术栈,前端,计算机基础,容器等方面的文章
📒 如果你也对Java感兴趣,关注小冷吧,一起探索Java技术的生态与进步,一起讨论Java技术的使用与学习
✏️高质量技术专栏专栏链接: 微服务,数据结构,netty,单点登录,SSM ,SpringCloudAlibaba等
😝公众号😝 : 想全栈的小冷,分享一些技术上的文章,以及解决问题的经验
⏩当前专栏:JUC系列
集合类不安全
List不安全
并发 arrayList是不安全的
解决方案:
1. vector 线程安全,因为新增方法前 带了 sync关键字,这个方法并不是最优解
2. 集合工具类 Collections.synchronizedList(new ArrayList<>());
3. JUC包下 CopyOnWriteArrayList<>()
CopyOnWrite 写入时复制,COW 计算机程序设计领域的一种优化策略
如 : 比如多个调用者调用同一个list,读取的时候,固定的,写入(覆盖)
在写入的时候 避免覆盖,造成数据问题; 读写分离
问题: 为什么不用vector 为什么呢?
答 : 因为只要使用 sync关键字,效率都会低一些,而CopyOnWriteArrayList,底层的方法是用的lock锁
//java.util.ConcurrentModificationException 并发修改异常
public class ListTest {
public static void main(String[] args) {
//并发 arrayList是不安全的
/* 解决方案
* 1. vector 线程安全,因为新增方法前 带了 sync关键字,这个方法并不是最优解
* 2. 集合工具类 Collections.synchronizedList(new ArrayList<>());
* 3. JUC包下 CopyOnWriteArrayList<>()
* CopyOnWrite 写入时复制,COW 计算机程序设计领域的一种优化策略
* 如 : 比如多个调用者调用同一个list,读取的时候,固定的,写入(覆盖)
* 在写入的时候 避免覆盖,造成数据问题;
* 读写分离
*
* 问题: 为什么不用vector 为什么呢? 因为只要使用 sync关键字,效率都会低一些,而CopyOnWriteArrayList,底层的方法是用的lock锁
* */
List<String> list = new CopyOnWriteArrayList<>();
for (int i = 1; i <= 600; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 5));
System.out.println(list);
}, String.valueOf(i)).start();
}
}
}
写入时复制的add方法的原理
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); //上锁,只允许一个线程进入
try {
Object[] elements = getArray(); // 获得当前数组对象
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝到一个新的数组中
newElements[len] = e;//插入数据元素
setArray(newElements);//将新的数组对象设置回去
return true;
} finally {
lock.unlock();//释放锁
}
}
Set不安全
解决方案 :
- 首先就是 Collections工具类 Collections.synchronizedSet(new HashSet());
- 就是和集合再同一个解决方案里的 Set set = new CopyOnWriteArraySet();
public class SetTest {
//java.util.ConcurrentModificationException 同理和集合没有什么区别
public static void main(String[] args) {
/* 如何解决hashset 线程不安全?
* 1. 首先就是 Collections工具类 Collections.synchronizedSet(new HashSet());
* 2. 就是和集合再同一个解决方案里的 Set set = new CopyOnWriteArraySet();
* */
Set set = new CopyOnWriteArraySet();
for (int i = 1; i <= 600; i++) {
new Thread(() -> {
set.add(UUID.randomUUID().toString().substring(0, 5));
System.out.println(set);
}, String.valueOf(i)).start();
}
}
}
HashSet的底层 是 hashmap
public HashSet(){
map = new HashMap<>();
}
//add set 的本质就是map key 是无法重复的
public boolean add(E e){
return map.put(e,PRESENT)==null;
}
private static final Object PRESENT = new Object //不变的值
Map类不安全
HashMap原理简单回顾

解决方案:
- Map<String, String> map = new ConcurrentHashMap<>();
public class mapTest {
//java.util.ConcurrentModificationException
public static void main(String[] args) {
// map是这样用的吗 不是 工作中很少使用 Hashmap
// 默认等价于什么 new HashMap<>(16,0.75);
/*解决方案
*
* */
Map<String, String> map = new ConcurrentHashMap<>();
for (int i = 1; i <= 500; i++) {
new Thread(() -> {
map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 5));
System.out.println(map);
}, String.valueOf(i)).start();
}
}
}
ConcurrentHashMap原理
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
ConcurrentHashMap的内部结构
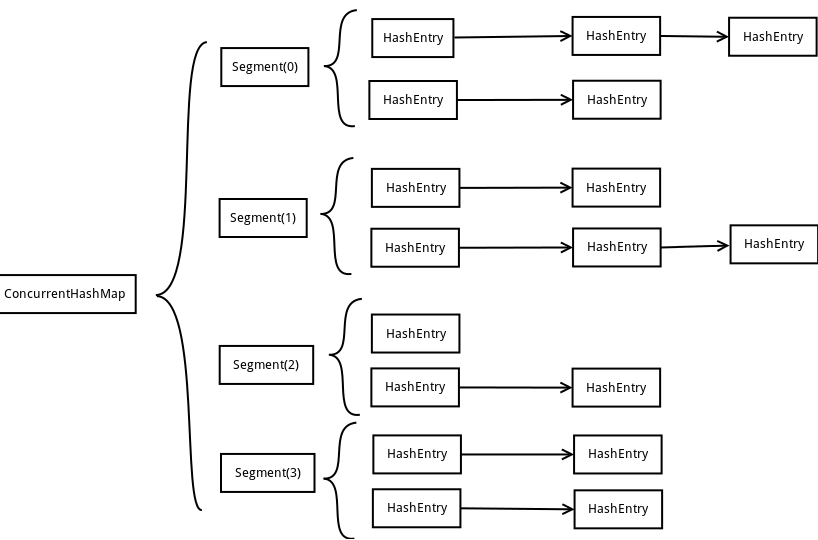
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











