






计图期末根据老师ppt整理期末复习笔记。
第二章 图形系统综述
1.视频显示设备
- 刷新式CRT(阴极射线管)
- 光栅扫描显示器
- 随机扫描显示器
- 彩色CRT监视器
- 直视存储管
- 平板显示器
- 三维观察设备
- 立体感和虚拟现实系统
2.输入设备
有多种设备用于图形工作站的数据输入:
- 键盘
- 鼠标
- 跟踪球和空间球
- 操纵杆
- 数据手套
- 数字化仪
- 图像扫描仪
- 触控板
- 光笔
- 声音系统
3.硬拷贝设备
- 35mm幻灯片
- 投影胶片
- 打印机
- 击打式
- 非击打式
- 绘图仪
第三章 输出图元
1. DDA算法
- 数字微分分析仪(DDA)方法是一种线段扫描转换算法
- 如果斜率小于等于1,x逐步加/减1,计算y的值
- 如果斜率大于1,y逐步加/减1,计算x的值
- 点的值必须取整
- 缺点
- 在浮点增量的连续叠加中,取整运算的累积误差使得计算像素的位置偏离实际线段。
- 取整操作和浮点运算仍然十分耗时
2. Bresenham画线算法
- 一种精确而有效的光栅线段生成算法
- 需确定每个取样步长时那个像素位置更接近于线段路径
- |m|<0时从左往右画,|m|>0时从下往上画
当|m|<1时算法如下所示, 当|m|>1时需要将算法中的x与y互换
1.输入线段的两个端点,将左端点存储在(x0,y0)中;
2.画出点(x0,y0);
3.计算常量Δx,Δy,(Δx,Δy均取正值)2Δy,2Δy-2Δx,计算决策参数的第一个值:p0=2Δy-Δx
4.从k=0开始,对于途径的每个点进行检测:
如果p_k < 0
则下一个绘制的点是(x_k+1,y_k)
并且 p_(k+1)=p_k+2Δy
否则
下一个绘制点为(x_k+1,y_k+1)
并且 p_(k+1)=p_k+2Δy-2Δx
5.重复步骤4,共Δx-1次(即运算到另一端点)

3. 圆的生成算法
- 圆定义为所有到中心位置 (xc, yc)距离为给定值r的点集
- 由于圆的对称性只绘制1/8圆的点,即从最上往右下画1/8个圆,其余点通过对称性得到
中点圆算法定义的圆函数:

中点画圆算法的步骤:
1.输入圆的半径r和圆心(xc,yc),得到圆心在原点的圆周上的第一个点:(x0,y0)=(0,r)
2.计算决策参数初始值:p0=5/4-r。如果按整数处理则,p0=1-r
3.对于每个x_k位置,从k=0开始:
如果p_k < 0
圆心在(0,0)的圆的下一个点为(x_k+1,y_k),
并且p_(k+1)=p_k+2x_(k+1)+1;
否则
圆的下一个点是(x_k+1,y_k-1)
并且p_(k+1)=p_k+2*x_(k+1)+1-2*y_(k+1)=p_k+2*(x_(k+1)-y_(k+1))+1
4.确定其他7个8分圆的对称点
5.平移,x=x+xc,y=y+yc;即将圆心在(0,0)的圆平移到圆心在(xc,yc)的路径上
6.重复步骤3~5,直到x >= y
4. 椭圆生成算法
- 椭圆定义为到两个定点(焦点)的距离之和等于常数的点的集合
- 对称性,只需要计算1/4部分椭圆
- 长轴是从椭圆的一侧通过焦点延伸到另一侧的线段
- 短轴是横跨椭圆的较短尺寸,它在两个焦点之间中点位置(椭圆中心)将长轴二等分
一些表示方程:


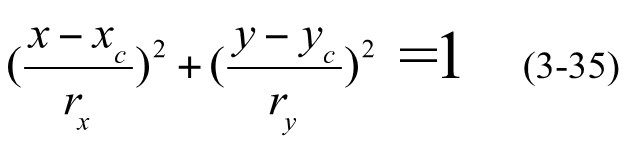
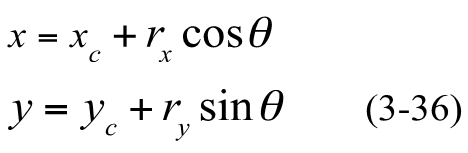
- 中点椭圆算法定义的椭圆函数:

- 区域1与区域2的划分:

- 从对中点椭圆算法定义的椭圆函数可得:

即椭圆的斜率,当斜率绝对值小于1时在区域1中,当斜率绝对值大于1时在区域2中
-
两个区域初始决策参数的计算
区域1

区域2

-
两个区域下个决策参数的计算
区域1

区域2

中点椭圆算法的步骤:

5. 填充区域图元
- 光栅系统中两种基本的区域填充方法:
- 通过确定横跨区域的扫描线的覆盖间隔进行填充(应用于多边形、圆等)
- 从给定的位置开始涂描直到指定的边界条件为止
- 扫描线多边形填充算法
从左往右扫描,对端点情况要做特殊处理(不知道要看到什么程度) - 内外测试
- 奇偶规则
从任意位置点P到对象坐标范围以外的远点画一条射线,统计沿改该射线与各边的交点数目。- 如果交点个数为奇数,P是内部点
- 如果交点个数为偶数,P是外部点
- 非零环绕数规则
统计多边形边以逆时针方向环绕某一特定点的次数,这个数称为环绕数。将内部点定义为具有非零值的环绕数
将环绕数初始化为0,并假设从任意位置P画一条射线,所选择的射线不能与多边形的任何顶点相交,当P点沿射线方向移动时,对在每个方向上穿过射线的边计数- 每当多边形从右到左穿过射线时,边数加1;
- 从左到右时,边数减1;
- 奇偶规则
- 曲线边界区域的扫描线填充
- 曲线边界区域的扫描线填充比多边形填充需要更多的处理,因为其交点计数包括非线性边界
- 充分利用对称性减少计算量
- 边界填充算法
- 区域填充的另一种方法是从区域的一个内部点开始,由内向外绘制点直到边界
- 假如边界是以单一颜色指定的,则填充算法可逐个像素地向外处理,直至遇到边界颜色。这种方法称为边界填充算法。
- 边界填充程序接收作为输入的内部点(x,y)的坐标、填充颜色和边界颜色
- 从(x,y)开始,程序检测相邻位置以确定其是否是边界颜色,如果不是,就用填充颜色涂色,并检测其相邻位置
- 这个过程延续到检测完区域边界颜色范围内的所有像素为止
- 4-连通区域
- 8-连通区域
- 泛滥填充法
- 有时,我们要对一个不是用单一颜色边界定义的区域进行填充(或重新涂色),即在多种颜色边界之内定义的区域进行填充;
- 通过替换指定的内部颜色,从而对该区域涂色而不是搜索边界颜色值,这个方法称为泛滥填充算法
- 从指定的内部点(x,y)开始,将期望的填充颜色赋给所有当前设置为给定的内部颜色的像素。假如所要涂色的区域具有多种内部颜色,可以重新设置像素值,从而使所有的内部点具有相同的颜色。然后使用4 —连通或8 —连通方法,逐步连通各像素位置,直到所有内部点都已被涂色
- 自我理解:在某个区域中,不管边界,只管将某种颜色的区域替换成另一种颜色,即完成了填充。
6. 单元阵列
- 单元阵列是一个图元,它允许用户显示用二维网格图案定义的任意形状。该功能将事先定义的颜色矩阵映射到一个指定的长方形坐标区域上
7. 字符生成
- 一种字符的完整设计风格成为字体
- 字体可分成两大类:
- 有衬线(在字符笔画末端有细线或加重)
- 无衬线
- 存储的计算机字体的两种表示方法:
- 点阵字体
- 轮廓字体
第四章 输出图元的属性
1. 反走样
- 由于低频取样(不充分取样)而造成的信息失真称为走样
- 可以使用校正不充分取样过程的反走样方法,来改善所显示的光栅线的外观
- 为了避免从这种周期性对象中丢失信息,则必须把取样频率至少设置为对象中出现的最高频率的两倍,这个频率称为奈奎斯特取样频率 f s = 2 f m a x f_{s}=2f_{max} fs=2fmax
- 取样间隔不应超过循环间隔(奈奎斯特取样间隔)的一半对于 x x x间隔取样,Nyquist取样间隔 Δ x s \Delta x_s Δxs为: Δ x s = Δ x c y c l e 2 \Delta x_s=\frac{\Delta x_{cycle}}{2} Δxs=2Δxcycle
-
- 一种简单、直接的反走样方法,就是把屏幕当做比实际所具有的更细的网格,从而增加取样频率,然后根据这种更细网格,使用取样点来确定每个屏幕像素的合适亮度等级。
- 这种在高分辨率下对对象特性取样并在较低分辨率上显示其结果的技术称为过取样,也称为后过滤
-
- 可以代替过取样的另一种方法是,通过计算待显示的每个像素在对象上的覆盖区域,从而确定像素亮度
- 计算覆盖区域的反走样称为区域取样(也称为前过滤),因为像素亮度是作为一个整体来确定的,所以不用计算子像素亮度
- 可以移动像素区域的显示位置而实现光栅对象的反走样,这种技术称为像素移相
2. 反走样的实现方法(一些具体的算法)
1. 直线段的过取样
直线段的过取样可以使用多种方式而完成。对于直线段的灰度显示,可以把每个像素分成一定数目的子像素,并统计沿线路径的子像素数目,然后将每个像素的亮度等级设置为正比于子像素数目的值。
2. 加权的像素掩模
过取样算法经常在实现时将更大的权值赋给接近于像素区域中心的子像素,因为我们希望这些子像素在确定像素的整体亮度中可以实现更重要的作用。下图示例了3x3像素部分所采用的加权方案

指定子像素的相对重要性的数值数组有时称为子像素权值的“掩模”(mask)。也可以为较大的子像素网格建立类似的掩摸。而且,经常扩展这些掩模以包含来自属于相邻像素中子像素的作用,从而对相邻像素进行平均以获得亮度。
3. 直线段的区域取样
通过将每个像素亮度设置为正比于像素与有限宽度直线的重叠区域,可以完成对直线的区域取样。
将直线看成矩形,而将两相邻的垂直(或两相邻的水平)屏幕网格线间的直线区域看做不规则四边形,那么就可以通过确定在垂直列(或水平行)中每个像素被多少四边形区域所覆盖来计算像素的重叠区域。
4. 过滤技术
对直线进行反走样的更精确的方法是采用过滤技术。这种方法类似于应用加权的像素掩模,只是假设一个连续的加权曲面(或过滤函数)覆盖像素。
5. 像素移相
在能够对屏幕网格内的子像素位置进行编址的光栅系统上,可以使用像素移相来反走样对象。通过将电子束移动(微定位)到更接近对象几何形状指定的近似位置,可以平滑沿线路径或物体边界的阶梯状现象。加入这种技术的系统,则设计为使单个像素位置可以根据像素直径的小数部分进行移动。
6. 直线亮度差的校正
为了减轻阶梯状效应,对直线进行反走样也为另一种光栅效果提供了校正
7. 反走样区域边界
-
直线的反走样概念也可以用于区域的边界,从而消除其锯齿形的外观效果。
- 假如系统具有允许像素重定位的功能,那么就可以调整边界像素位置,使其沿着定义区域边界的直线而实现对区域边界的平滑处理
- 其他方法则是根据边界内像素区域的百分比,来调整每个边界位置上的像素亮度。
-
过取样方法是通过分割整体区域并确定区域边界内的子像素数目而应用的,即可以理解成分格子,数格子
-
另一种由Pitteway和Watkinson提出的确定边界内像素区域百分比的方法,是以中点算法为基础的。(具体内容可能不考)
- 这个算法通过测试两像素间的中间位置,确定哪个像素更接近于直线而选择沿扫描线的下一个像素。类似于Bresenham算法,可以建立决策参数p,其符号可以表明下面的两个候选像素中哪一个更接近于直线。通过对p形式的略微修改,就可以得到被对象覆盖的当前像素区域的百分比。
第五章 二维几何变换
1. 基本变换(重点是平移、旋转、缩放的概念)
1.1 平移
- 平移是指将对象沿直线路径从一个坐标位置移到另一个坐标位置的重定位。
- 平移是一种不产生变形而移动对象的刚体变换,即对象上的每个点移动相同数量的坐标。
1.2 旋转
- 二维旋转是将对象沿xy平面内的圆弧路径重定位。
- 为了实现旋转,需要指定旋转角θ和对象旋转的旋转点(或基准点)和位置( x r , y r x_r,y_r xr,yr)
- 旋转角的正值定义为绕基准点逆时针旋转,负值则以顺时针方向旋转对象
- 类似于平移,旋转是一种不变形地移动对象的刚体变换,对象上的所有点旋转相同的角度
- 这种变换也可以描述为通过基准点,围绕垂直于xy平面的旋转轴旋转
- 变换后的坐标表示为:
x ′ = r ∗ c o s ( ϕ + θ ) = r c o s ( ϕ ) c o s ( θ ) − r s i n ( ϕ ) s i n ( θ ) x^{'}=r*cos(\phi+\theta)=rcos(\phi)cos(\theta)-rsin(\phi)sin(\theta) x′=r∗cos(ϕ+θ)=rcos(ϕ)cos(θ)−rsin(ϕ)sin(θ)
y ′ = r ∗ s i n ( ϕ + θ ) = r c o s ( ϕ ) s i n ( θ ) + r s i n ( ϕ ) c o s ( θ ) y^{'}=r*sin(\phi+\theta)=rcos(\phi)sin(\theta)+rsin(\phi)cos(\theta) y′=r∗sin(ϕ+θ)=rcos(ϕ)sin(θ)+rsin(ϕ)cos(θ) - 因为:
x = r c o s ( ϕ ) , y = r s i n ( ϕ ) x=rcos(\phi),y=rsin(\phi) x=rcos(ϕ),y=rsin(ϕ) - 所以
x ′ = x c o s ( θ ) − y s i n ( θ ) x^{'}=xcos(\theta)-ysin(\theta) x′=xcos(θ)−ysin(θ)
y ′ = x s i n ( θ ) + y c o s ( θ ) y^{'}=xsin(\theta)+ycos(\theta) y′=xsin(θ)+ycos(θ) - 使用向量形式
P
′
=
R
⋅
P
P^{'}=R \cdot P
P′=R⋅P,旋转矩阵
R
R
R为
R = [ c o s ( θ ) − s i n ( θ ) s i n ( θ ) c o s ( θ ) ] R=\begin{bmatrix} cos(\theta) & -sin(\theta) \\sin(\theta) & cos(\theta) \end{bmatrix} R=[cos(θ)sin(θ)−sin(θ)cos(θ)] - 旋转点不在原点时,先平移到相对原点位置->旋转->平移回原位置
1.3 缩放
- 缩放变换改变对象的尺寸。对于多边形缩放,则可以通过将每个顶点的坐标值(x,y)乘以缩放系数 s x s_x sx和 s y s_y sy从而产生变换的坐标
- 当赋给 s x s_x sx和 s y s_y sy相同的值时,就会产生保持对象相对比例的一致缩放;
- s x s_x sx和 s y s_y sy值不等时将产生差值缩放。这种缩放常用于设计应用中,因为设计应用中的图形是从一些基本形状构造出来的,这些形状能通过缩放和定位变换而调整
- 固定点坐标(
x
f
,
y
f
x_f,y_f
xf,yf)不在原点时,即平移->缩放-平移
x ′ = x f + ( x − x f ) s x , y ′ = y f + ( y − y f ) s y x^{'}=x_f+(x-x_f)s_x,y^{'}=y_f+(y-y_f)s_y x′=xf+(x−xf)sx,y′=yf+(y−yf)sy
2. 矩阵表示与齐次坐标
-
将二维坐标位置表示 ( x , y ) (x,y) (x,y)扩充到三维表示 ( x h , y h , h ) (x_h,y_h,h) (xh,yh,h),称为齐次坐标,**齐次参数 h h h**是一个非零值, x = x h / h x=x_h/h x=xh/h, y = y h / y y=y_h/y y=yh/y 普通的二维齐次坐标表示写成( h ⋅ x , h ⋅ y , h h \cdot x,h \cdot y,h h⋅x,h⋅y,h),最方便的选择是让h=1
-
相对于原点的平移变换, T T T

-
相对于原点的旋转变换, R R R

-
相对于原地的缩放变换, S S S

3. 复合变换
- 将对应的变换矩阵按照变换顺序左乘起来即可。
例:需要对于位置点P进行两次变换,变换顺序为先 M 1 M_1 M1后 M 2 M_2 M2,则 P ′ = M 2 ⋅ M 1 ⋅ P P^{'}=M_2 \cdot M_1 \cdot P P′=M2⋅M1⋅P,每次变换都是左乘,且按顺序进行 - 对变换矩阵求逆即可得到逆变换,平移是平移负数,旋转是旋转负角度,缩放是除缩放系数
- 两个连续平移是相加的
- 两个连续旋转也是相加的,将旋转角相加 R ( θ 2 ) ⋅ R ( θ 1 ) = R ( θ 1 + θ 2 ) R(\theta_2) \cdot R(\theta_1)=R(\theta_1+\theta_2) R(θ2)⋅R(θ1)=R(θ1+θ2)
- 连续缩放操作是相乘的,缩放系数对应相乘
- 通用基准点旋转
- 平移对象使基准点位置移动到坐标原点;
- 绕坐标原点旋转;
- 平移对象使基准点回到其原始位置。
变换矩阵如下所示:最右边的是最先进行的变换,即先移到原点,然后绕原点旋转,然后再平移回原位置

- 通用固定点缩放
- 平移对象使固定点与坐标原点重合;
- 对于坐标原点缩放;
- 使用步骤1的反向平移将对象返回到原始位置。

- 通用定向缩放
- 完成旋转操作,从而使 s 1 s_1 s1和 s 2 s_2 s2方向分别与x和y轴重合
- 缩放变换
- 反向旋转以回到其原始位置。

4. 其他变换
4.1 反射
-
反射是产生对象的镜像的一种变换。

-
关于y轴反射,x变负,y不变
-
如果不是关于坐标轴反射,需要进行旋转平移等操作,例如下述操作
将1,2,3步骤所对应的变换矩阵乘起来,连乘的变换矩阵中,最右边是最先进行的步骤

[ c o s ( π / 4 ) − s i n ( π / 4 ) 0 s i n ( π / 4 ) c o s ( π / 4 ) 0 0 0 1 ] ⋅ [ − 1 0 0 0 1 0 0 0 1 ] ⋅ [ c o s ( − π / 4 ) − s i n ( − π / 4 ) 0 s i n ( − π / 4 ) c o s ( − π / 4 ) 0 0 0 1 ] \begin{bmatrix} cos(\pi/4) & -sin(\pi/4) & 0 \\ sin(\pi/4) & cos(\pi/4) & 0 \\ 0 & 0 & 1 \end{bmatrix}\cdot \begin{bmatrix} -1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix}\cdot \begin{bmatrix} cos(-\pi/4) & -sin(-\pi/4) & 0 \\ sin(-\pi/4) & cos(-\pi/4) & 0 \\ 0 & 0& 1 \end{bmatrix} ⎣⎡cos(π/4)sin(π/4)0−sin(π/4)cos(π/4)0001⎦⎤⋅⎣⎡−100010001⎦⎤⋅⎣⎡cos(−π/4)sin(−π/4)0−sin(−π/4)cos(−π/4)0001⎦⎤
= [ 0 − 1 0 − 1 0 0 0 0 1 ] =\begin{bmatrix} 0 & -1 & 0 \\ -1 & 0 & 0 \\ 0 &0 & 1 \end{bmatrix} =⎣⎡0−10−100001⎦⎤
- 关于xy平面内的任意直线y=mx+b的反射,可以使用平移-旋转-反射变换的组合完成,一定牢记每次变换都是左乘,且按顺序进行,
- 先平移直线使其经过原点。
- 然后将直线旋转到坐标轴之一,并关于坐标轴反射
- 最后利用逆旋转和平移变换将直线还原到原来位置
4.2 错切
- 错切是一种使对象形状发生变化的变换。经过错切的对象好像是由已经相互滑动的内部夹层组成
- 常用的错切变换有两种:改变x坐标值和改变y坐标值



第六章 二维观察
1. 观察流程
- 世界坐标系中要显示的区域称为窗口
- 窗口映射到显示器上的区域称为视口
- 窗口定义了显示的内容,而视口定义在什么位置进行显示。
- 在计算机图形学术语中,窗口最初是指要观察的图形区域。但是,目前窗口也用于窗口管理系统,指任何可以移动、改变大小、激活和变为无效的屏幕上的矩形区域。
- 二维观察变换流程

2.裁剪操作
- 识别图形在指定区域内或区域外的部分的过程称为剪裁算法,简称剪裁
- 用来裁剪对象的区域称为裁剪窗口
- 裁剪的应用包括:
- 从定义的场景中抽取出用于观察的部分;
- 在三维视图中标识出可见面;
- 防止线段或对象的边界混淆等。
2.1 点的裁剪

2.2 线段的裁剪(直线段)
-
线段的裁剪过程包括几个部分:
- 首先测试一个给定的线段,判断它是否完全落在裁剪窗口之内。
- 如果没有完全落在裁剪窗口之内,再判断是否完全落在窗口之外。
- 最后,对于既不能确定完全落在窗口内又不能确定完全落在窗口外的线段,要计算它与一个或多个裁剪边界的交点。我们通过对线段的端点进行“内部-外部”测试来处理线段。
-
Cohen-Sutherland 线段剪裁算法
- 通过初始测试来减少要计算的交点数目,从而加快线段裁剪算法的计算速度
- 每条线段的端点都赋值为四位二进制码,称为区域码,用来标识端点相对裁剪矩形边界的位置,记住(左右下上,从右开始)


- 区域码的确定可以按下列两步进行确定:
- 计算端点坐标和裁剪边界之间的差值
- 用各差值的符号位来设置区域码中相应的位置, 正0负1。位1设为 x − x w m i n x-xw_{min} x−xwmin的符号位;位2设为 x w m a x − x xw_{max}-x xwmax−x的符号位;位3设为 y − y w m i n y-yw_{min} y−ywmin的符号位;位4设为 y w m a x − y yw_{max}-y ywmax−y的符号位。
- 判断是否在内外区域:
- 完全在窗口边界内的线段,其两个端点的区域码均为0000,因此保留这些线段
- 两个端点的区域码中,同样位置都为1的线段则完全落在裁剪矩形之外,因此丢弃这些线段
- 测试线段是否完全被裁剪掉的方法,是对两个端点的区域码进行逻辑与(and)操作。如果结果不为0000,则线段完全位于裁剪区域之外
- 对于不能判断为完全在窗口外或窗口内的线段,则要计算与窗口边界的交点(利用直线方程计算交点)
- 与裁剪边界的交点计算可以使用斜率-截距式的直线方程。对于端点坐标为(
x
1
,
y
1
x_1,y_1
x1,y1)和(
x
2
,
y
2
x_2,y_2
x2,y2)的直线,
- 与垂直边界交点的
y
y
y坐标可以由下列等式计算得到:
y = y 1 + m ( x − x 1 ) y=y_1+m(x-x_1) y=y1+m(x−x1) - 与水平边界相交的交点
x
x
x坐标,可以按下列等式进行计算:
x = x 1 + ( y − y 1 ) / m x=x_1+(y-y_1)/m x=x1+(y−y1)/m
- 与垂直边界交点的
y
y
y坐标可以由下列等式计算得到:
-
梁友栋-Barsky 线段裁剪算法
-
对端点为( x 1 , y 1 x_1,y_1 x1,y1)和( x 2 , y 2 x_{2},y_{2} x2,y2)的直线段进行参数形式描述,下面应注意 u u u的取值为0到1

-
按参数形式写出剪裁条件:

-
上述四个不等式可以表示为: u p k ≤ q k , k = 1 , 2 , 3 , 4 up_k\le q_k,k=1,2,3,4 upk≤qk,k=1,2,3,4
-
参数 p , q p,q p,q定义如下:

-
当 p k p_k pk等于0时,直线平行于裁剪边界之一,其中k对应于该裁剪边界(k=1,2,3,4对应于左、右、下、上边界)
- 如果还满足 q k < 0 q_k<0 qk<0,则线段完全在边界以外,舍去该线段。如果 q k ≥ 0 q_k\ge 0 qk≥0,则线段平行于裁剪边界且位于窗口内
-
当 p k < 0 p_k<0 pk<0时,线段从裁剪边界延长线的外部延伸到内部,当 p k > 0 p_k>0 pk>0时 ,线段从裁剪边界延长线的内部延伸到外部。理解为从端点x1到端点x2的路径上,对应穿过裁剪窗口的边界时,是由外向内或由内向外
-
当 p k p_k pk不等于0时,可以计算出线段与边界k的延长线的交点 u u u值: u = q k / p k u=q_k/p_k u=qk/pk
-
对应每条直线,可以计算出参数 u 1 u_1 u1和 u 2 u_2 u2,他们定义了裁剪矩形内的线段部分。
- u 1 u_1 u1: p k < 0 p_k<0 pk<0时(从外到内), r k = q k / p k r_k=q_k/p_k rk=qk/pk, u 1 u_1 u1取0和 r k r_k rk中的最大值;
- u 2 u_2 u2: p k > 0 p_k>0 pk>0时(从内到外), r k = q k / p k r_k=q_k/p_k rk=qk/pk, u 1 u_1 u1取1和 r k r_k rk中的最小值;
-
k=1,2,3,4对应于左、右、下、上边界
-
如果 u 1 > u 2 u_1>u_2 u1>u2,则线段完全落在裁剪窗口外,否则根据参数 u u u的两个值计算出裁剪后的线段端点;
-
-
Nicholl-Lee-Nicholl 线段裁剪算法
- 与梁友栋-Barsky和 Cohen-Sutherland 算法相比,NLN 算法的比较次数和除法次数减少
- 但是NLN算法仅仅用于二维裁剪,而梁友栋-Barsky和 Cohen-Sutherland 算法可以很方便地扩展为三维裁剪算法。

(1) 首先根据 P1的位置在平面上创立新的区域,边界是以P1为起点的射线,穿过窗口的角。如果 P1 在裁剪窗口之内,P2 在窗口外, 我们就设置四个区域

连接P1和裁剪区域的四个角点的直线都将裁剪区域划分成四个区域。按直线通过的角点在裁剪区域中的方位将这四条直线分别记为LT、RT、LB和RB,表示它们所经过的角点分别处于裁剪区域的左上、右上、左下和右下方位。通过比较直线 P 1 P 2 P_1P_2 P1P2和这四条直线的斜率,可以确定直线的可见性、直线和裁剪区域边界的交点的个数以及交点所在的边界。
(2) 如果 P1 位于窗口的左边区域,则设定四个区域: L, LT, LR,LB。

也是比较斜率
-
划分凹多边形
-
通过绕多边形的周长计算相邻边向量的叉乘,可以识别出凹多边形
-
如果一些叉积结果的 z 分量为正,而另一些 z 分量为负,则该多边形为凹多边形。否则为凸多边形
-
必须假定没有三个相邻的顶点是共线的,因为三点共线的情况下,这两个相邻的边向量的叉积结果为零

-
可以使用旋转法分割凹多边形
- 绕多边形逆时针前进,将多边形顶点Vk平移到坐标原点。
- 然后顺时针旋转,使下一个顶点Vk+1在x轴上。
- 如果下一个顶点Vk+2在x轴下方,则多边形为凹多边形,沿x轴将多边形分割为两个新的多边形,对这两个新的多边形重复进行凹多边形测试。否则继续旋转x轴上的顶点,并测试顶点的y值是否为负。
-
2.3 多边形的裁剪
- 多边形裁剪后的输出应该是定义裁剪后的多边形的顶点序列。
- 两种多边形裁减算法
- Sutherland-Hodgeman 多边形裁剪
-
沿着多边形依次处理顶点会遇到四种情况
-
在将相邻的一对多边形顶点传到窗口的边界裁剪程序时,进行下列测试:
- 如果第一点在窗口边界外而第二点在窗口边界内,则将多边形的这条边与窗口边界的交点和第二点加到输出顶点表中;
- 如果两个顶点都在窗口边界内,则只有第二点加到输出顶点表中;
- 如果第一点在窗口边界内而第二点在窗口外,则只有与窗口边界的交点加到输出顶点表中;
- 如果两个点都在窗口边界外,那么输出顶点表中不增加任何点。

-
Sutherland-Hodgeman算法只生成一个输出顶点序列,所以会导致上图中两块区域中间的线,为了正确地裁剪凹多边形,我们可以从几个方面入手
- 一种方法是将凹多边形分割成两个或者更多的凸多边形,然后分别处理各个凸多边形。
- 另一种方法是修改Sutherland-Hodgeman算法,沿着任何一个裁剪窗口边界检查顶点表,从而正确地连接顶点对
- 还有一种方法是可以使用更一般的多边形裁剪算法,例如下面介绍的 Weiler-Atherton算法或Weiler算法
-
- Weiler-Atherton 算法
- 算法的基本思想是:有时沿着多边形某一边的方向来处理顶点,有时沿着窗口的边界方向进行处理
- 采用哪一条路径,要根据多边形处理方向(顺时针或逆时针),以及当前处理的多边形顶点对是由外到内还是由内到外。如果顺时针处理顶点,则采用下列规则:
- 对由外到内的顶点对,沿着多边形边界的方向。
- 对由内到外的顶点对,按顺时针沿着窗口边界的方向。
- Sutherland-Hodgeman 多边形裁剪


2.4 曲线的裁剪
曲线边界的区域可以使用类似上一节的方法进行裁剪。曲线的裁剪过程涉及非线性方程,与线性边界的区域处理相比,需要更多的处理。
2.5 文字的裁剪
- 使用窗口边界处理字符串的最简单的方法,是全部保留或全部舍弃字符串的裁剪策略。如果字符串中的所有字符都在裁剪窗口内,那么就全部保留这些内容,否则舍弃整个字符串。(字符串在裁剪边界时全部丢弃)
- 对于裁减与窗口边界相重叠的字符串的另一种方法是,可以使用全部保留或全部舍弃一个字符的裁剪策略。对于没有完全落在窗口内的字符应该舍弃。(字符串在裁剪边界时丢弃没有完全在窗口内的字符)
- 最后一种处理方法是对各个字符本身进行裁剪,使用线段裁剪的方法对字符进行裁剪。如果一个字符与裁剪窗口边界有重叠,则裁剪掉位于窗口之外的字符部分。(完全,严格的裁剪,对字符本身进行裁剪)
2.6 外部裁剪
- 在某种情况下,我们需要进行相反的处理,即裁剪指定区域外的图形部分,即外部裁剪
- 主要应用
- 多窗口系统
- 有覆盖图形的情况
第八章 图形用户界面和交互输入方法
1. 用户对话
- 对于某种特定的应用,用户模型是设计对话的基础
- 构造用户对话时,一般应注意的情况:
- 窗口和图符
- 适应多种熟练程度的用户
- 一致性
- 减少记忆量
- 回退和出错处理
- 反馈
2. 图形数据的输入
- 如果按照输入的数据类型将输入功能分类,则用来输入某种特定数据的设备就称为这种数据类型的逻辑输入设备
- 按照设备输入的数据类型而进行的逻辑输入设备分类
- 标准的逻辑输入数据设备分为以下六类:
- LOCATOR-指定坐标位置(x, y)的设备(定位设备)
- STROKE-指定一组坐标位置的设备(笔划设备)
- STRING-指定文字输入的设备(字符串设备)
- VALUATOR-指定标量值的设备(定值设备)
- CHOICE-选择菜单项的设备(选择设备)
- PICK-选择图形的组成部分的设备(拾取设备)
3. 输入功能
- 通过设定输入功能。用户可指定以下选项
- 使用哪一种物理设备为特定逻辑分类提供输入。
- 图形程序和设备如何进行交互 。
- 何时输入数据,使用哪一种设备在输入时将特定数据类型传递到指定的数据变量中。
- 提供输入的函数可以按多种输入模式进行组织。每种模式分别指明程序如何与输入设备交互
- 程序启动输入,或程序和输入设备可以同时工作,或设备可以启动数据输入。这三种输入模式分别称为请求模式、取样模式和事件模式
- 请求模式:由应用程序启动数据输入。程序和输入设备交替工作,设备处于等待状态直到提出输入请求,然后程序处于等待状态直到收到数据
- 取样模式:应用程序和输入设备各自独立地操作。当程序需要一个新数据时,就从输入设备取得当前值(一直不停的采集数据,用的时候取当前值,之前采的数据就丢掉了)
- 事件模式:输入设备启动数据输入并交给应用程序。所有输入数据均存储起来。当程序需要一个新数据时,就从输入队列中取得(产生的数据存起来)
- 在取样模式和事件模式下,任意数目的设备可以同时工作。但是在请求模式下,一个时间片内只能有一个设备可以提供输入。
4. 交互式构图技术
- 图形软件包中的一些技术可以帮助进行交互式构图
- 基本的定位方法
- 约束
- 网格
- 引力场
- 橡皮条方法
- 拖曳
- 着色和绘图
第九章 三维概念
1. 三维显示方法
- 平行投影
- 产生实体视图的一种方法是:将物体表面上的点沿平行线投影到显示平面上
- 在平行投影中,三维场景中的平行线在投影到二维显示平面中后仍然是平行线 。
- 透视投影
- 另一个产生三维场景视图的方法是:沿会聚路径将点投影到显示平面上。
- 在透视投影中,场景中的平行线投影后不再平行而是成了会聚线。
- 使用透视投影来显示场景会更真实,因为这是眼球和相机镜头成像的方式。
- 深度提示
- 深度信息是十分重要的。因此对于某一特别的观察方向,我们能容易地识别哪一部分是显示的物体的前面,哪一部分是后面
- 没有深度信息会导致线框物体显示的二义性
- 在实体的二维显示中,有几种能包含深度信息的方式
- 线框显示中指明深度的一种简单方法是:根据它们离观察位置的距离来改变物体的亮度
- 离观察位置最近的线以最高亮度显示,而较远的线则以递减的亮度显示
- 深度提示的一个应用是:模拟物体可视亮度的大气效果
- 一些大气作用能改变物体的可视颜色,我们可以使用深度提示来模拟这些效果
- 可见线面的标识
- 通过某一方式标识可见线,也能说明线框显示中的深度关系。
- 最简单的方法是突出可见线或者以不同的颜色来显示它们。
- 通常用于工程制图的另一种技术是,使用虚线来显示不可见线。
- 还有一种途径是简单地去除不可见线,但去掉隐线也就去掉了物体背面形状的信息。
- 通过某一方式标识可见线,也能说明线框显示中的深度关系。
- 表面绘制
- 根据场景中的光线条件及根据指定表面的特性来建立物体表面的亮度,可以获得额外的显示真实性。
- 可以使用程序来产生场景的正确照明和阴影区域
- 分解图和剖面图
-
很多图形软件包允许把物体看成多层结构,因此可以存储其内部细节。
-
物体的分解图和剖面图可以用来显示其内部结构以及物体各组件的关系。
-
- 三维和立体视图
- 增加计算机生成场景的真实感的另一种方法是:使用三维的或者使用立体的视图来显示物体。
第十二章 三维观察
1. 观察流水线
下图表明了对建模以及将场景的世界坐标描述变换到设备坐标的一般步骤

2. 投影
- 平行投影,坐标位置沿平行线变换到观察平面上。
- 透视投影,物体位置沿收敛于某一点的直线变换到观察平面上,该点称为投影参考点
- 平行投影保持物体的有关比例不变,这是三维物体绘图中产生成比例图画的方法
- 透视投影生成真实感视图,但不保持相关比例
- 当投影垂直于观察平面时,得到正平行投影。否则,得到斜平行投影
- 正投影多数用于产生物体的前视图、侧视图和顶视图
- 能形成显示物体多个侧面的正投影,也称为轴测正投影。最常用的轴测投影是等轴测投影。
- 一组平行线投影后收敛于一点,此点称为灭点(透视投影产生)
- 物体中平行于某一坐标轴的平行线的灭点称为主灭点。可以利用投影平面的方向控制主灭点数目,投影中主灭点数目由与观察平面相交的主轴数目确定
3. 观察体和一般投影变换
- 观察窗口的边平行于坐标轴,观察边界位置由观察坐标给出。
- 观察体的大小依赖于窗口的大小,而观察体的形状依赖于生成显示结果的投影类型
- 正平行投影不受观察平面位置的影响
- 斜投影可能受观察平面位置的影响,这取决于如何给其指定投影方向。
- 透视效果取决于投影参考点与观察平面的位置 。
第十三章 可见面判别算法
1. 可见面判别算法的分类
- 可见面判别算法的分类,通常是根据其处理场景时是直接对物体定义进行处理还是处理它们的投影图像。这两种类型分别称为物空间算法和像空间算法。
- 物空间算法:将场景中的各物体和物体的各个组成部分相互进行比较,从而最终判别出哪些面是可见的;
- 像空间算法 :在投影平面上逐点判断各像素所对应的可见面。
2. 后向面判别
- 假设有一点(x,y,z)和一个平面参数为A、B、C、D的多边形面,如果: Ax+By+Cz+d<0
- 则该点在多边形的“内”侧。若一内点位于视点到一多边形面之间的直线上,则该多边形必为后向面(我们位于该面的内侧,从观察位置无法看到其正面)
- 是一个物空间算法
3. 深度缓冲器算法(重点)
- 深度缓冲器算法是一个比较常用的判定物体表面可见性的像空间算法。其基本思想是,对投影平面上每个像素所对应的表面深度进行比较
- 由于通常沿着观察系统的z轴来计算各物体距观察平面的深度,因此上述算法也称为z缓冲器算法

3. A缓冲器算法
- A 缓冲器算法是深度缓冲器算法的延伸。此处,A 表示反走样、区域平均和累计缓冲器
- 深度缓冲器算法的一个缺点是:它在每个像素点只能找到一个可见面。即它只能处理非透明表面,而无法处理多个表面的累计强度值,对于图13 . 8 所示的透明表面,这种处理又是必需的。
- A 缓冲器中每个单元均包含两个域:
- 深度域― 存储一个正的或负的实数;
- 强度域― 存储表面的强度信息或指针值。
4. 扫描线算法
- 是像空间的隐面消除算法,是多边形区域填充中扫描线算法的延伸。此处,处理的是多个表面,而非填充单个多边形面。
- 逐条处理各条扫描线时,首先要判别与其相交的所有表面的可见性,然后计算各重叠表面的深度值以找到离观察平面最近的表面。一旦确定了某像素点所对应的可见面,可以得到该点的强度值,并将其置入刷新缓冲器
5. 深度排序算法
- 深度排序算法同时运用物空间与像空间操作,以实现以下基本功能:
- 表面按深度递减方向排序;
- 由深度最大的表面开始,逐个对表面进行扫描转换。
- 排序操作同时在像空间和物空间完成,而多边形面的扫描转换仅在像空间完成。
- 这种隐藏面消除算法通常称为画家算法
6. BSP树算法
- BSP树算法是一种判别物体可见性的有效算法。该算法类似于画家算法,将表面由后往前地在屏幕上绘出,该算法特别适用于场景中物体位置固定不变、仅视点移动的情况。
- 利用BSP 树来判别表面的可见性,其主要操作是在每次分割空间时,判别该表面相对于视点与分割平面的位置关系,即位于其内侧还是外侧,图13 . 19 表示了该算法的基本思想。

7. 区域细分算法
- 区域细分算法虽然本质上是一种像空间算法,但使用了一些物空间操作来完成表面的深度排序。
- 该算法充分利用场景中区域的连贯性,将视野集中于包含表面的区域;并将整个观察范围细分为越来越小的矩形单元,直至每个单元仅包含单个可见表面的投影或不含任何表面。
8. 八叉树算法
- 当按照八叉树表示来描述观察体时,通常按由前往后的顺序将八叉树节点映射到观察表面,从而消除隐藏面
9. 光线投射算法
10. 曲面
- 对于曲面物体,最有效的可见性判别算法为光线投射算法和八叉树算法。
11. 线框算法
- 确定物体边框可见性的过程通常称为线框可见性算法,也称为可见线判别算法或隐线判别算法
13. 可见性判别函数
第十五章 颜色模型和颜色应用
-
RGB颜色模型
- 使用三种颜色基色:红、绿和蓝在视频监视器上显示彩色的基础,称为RGB颜色模型。
- 一种颜色 C λ C_{\lambda} Cλ在RGB中表示为: C λ C_{\lambda} Cλ=RR+GG+BB
- 可以使用由R、G和B坐标轴定义的单位立方体描述这个模型,坐标原点代表黑色,而其对角坐标(1,1,1)代表白色,在三个坐标轴上的顶点代表三个基色,而余下的顶点则代表每一个基色的补色。
-
YIQ颜色模型
- YIQ颜色模型是形成组合视频信号的NTSC颜色模型
- 使用某个变换矩阵可以将RGB值转换到YIQ值,上述矩阵的逆可以将YIQ变化成RGB
-
CMY颜色模型
- 使用基色的青色、品红和黄色定义的颜色模型(CMY),用来描述向硬拷贝设备上输出的颜色。

- 使用基色的青色、品红和黄色定义的颜色模型(CMY),用来描述向硬拷贝设备上输出的颜色。
-
HSV颜色模型
- HSV 模型使用对用户更直观的颜色描述方法。为了给出一种颜色描述,用户需要选择一种光谱色并加入一定量白色和黑色来获得不同的明暗、色泽和色调。这个模型中的颜色参数是色彩(H),色饱和度(S),明度值(V)
-
HLS颜色模型
-
另一个基于直观颜色参数的模型是 Tektronix 公司使用的 HLS 系统。
-
该模型表示为图15.18中的双棱锥体。

-
该模型中的三个参数称为色彩(H),亮度(L) 和饱和度(S)。
-















 5474
5474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









