







注意CUDA环境与TensorRT版本匹配,否则会有问题:
Could not load library cudnn_cnn_infer64_8.dll. Error code 126Please make sure cudnn_cnn_infer64_8.dll is in your library path!交代一下软件相关版本信息,防止翻车!
Win10 x64CUDA11.0.2cuDNN8.2.0TensorRT8.4.0VS2017OpenCV4.5.4GPU3050 ti
VS2017中开发环境配置
配置包含路径
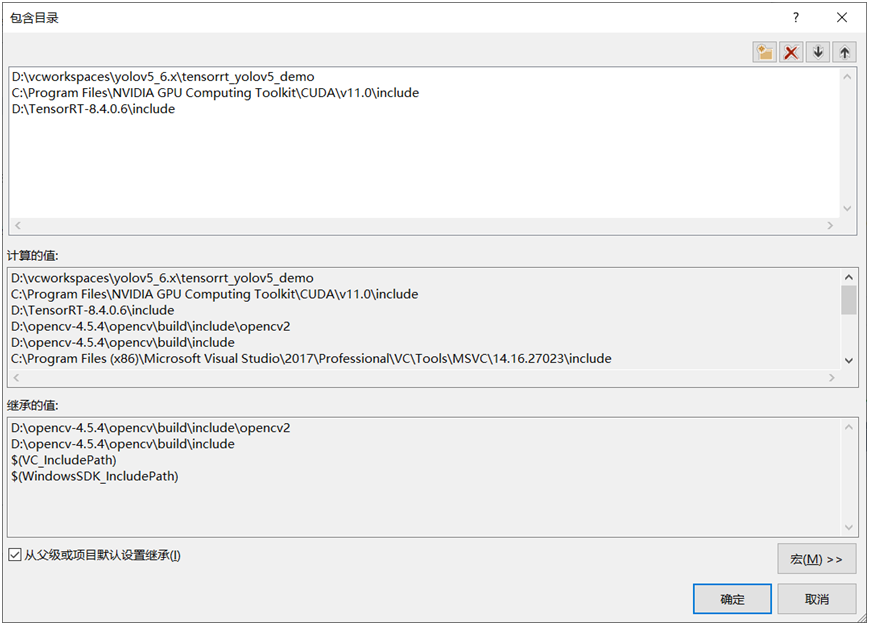
配置库目录路径:
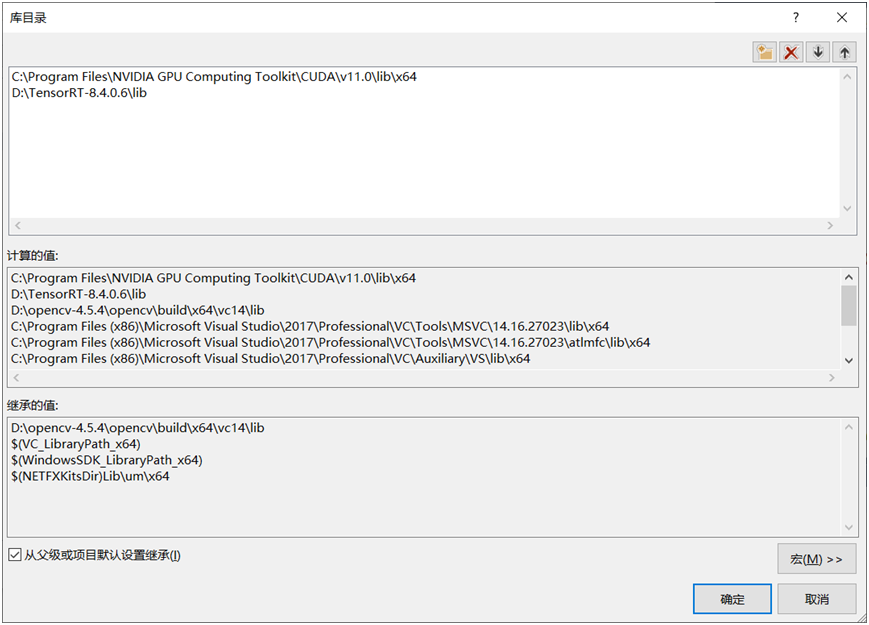
说明一下,我的TensorRT解压缩之后在路径为D:\TensorRT-8.4.0.6
配置连接器相关lib文件如下:
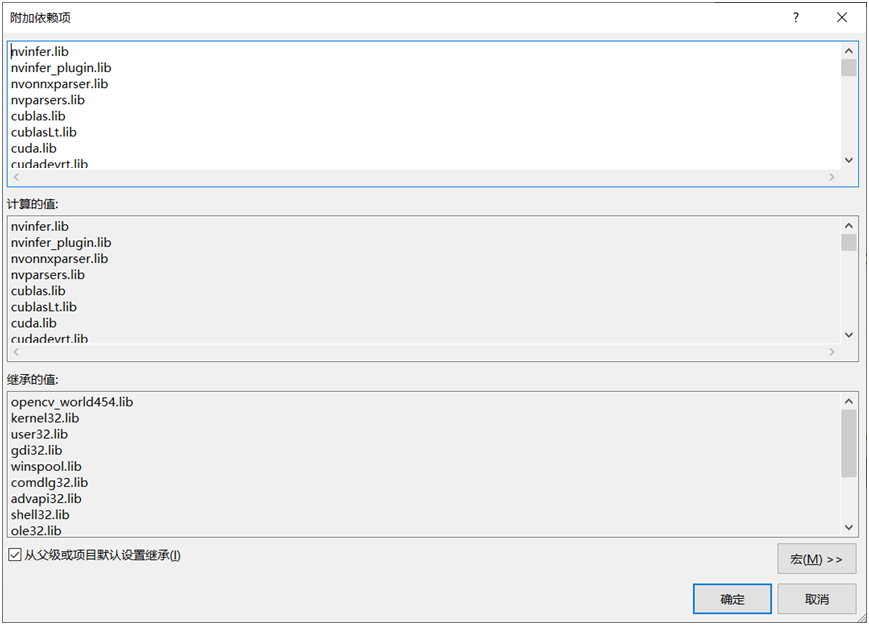
相关lib文件列表如下:(特别注意:版本不同会有差异,请慎重拷贝!)
nvinfer.libnvinfer_plugin.libnvonnxparser.libnvparsers.libcublas.libcublasLt.libcuda.libcudadevrt.libcudart.libcudart_static.libcudnn.libcudnn64_8.libcudnn_adv_infer.libcudnn_adv_infer64_8.libcudnn_adv_train.libcudnn_adv_train64_8.libcudnn_cnn_infer.libcudnn_cnn_infer64_8.libcudnn_cnn_train.libcudnn_cnn_train64_8.libcudnn_ops_infer.libcudnn_ops_infer64_8.libcudnn_ops_train.libcudnn_ops_train64_8.libcufft.libcufftw.libcurand.libcusolver.libcusolverMg.libcusparse.libnppc.libnppial.libnppicc.libnppidei.libnppif.libnppig.libnppim.libnppist.libnppisu.libnppitc.libnpps.libnvblas.libnvjpeg.libnvml.libnvrtc.libOpenCL.lib
YOLOv5模型转换ONNX->engine
直接初始化YOLOv5TRTDetector类,然后调用onnx2engine方法,实现onnx到engine文件转换,相关代码如下:
auto detector = std::make_shared();detector->onnx2engine("D:/python/yolov5-6.1/yolov5s.onnx", "D:/python/yolov5-6.1/yolov5s.engine", 0);
运行结果如下:
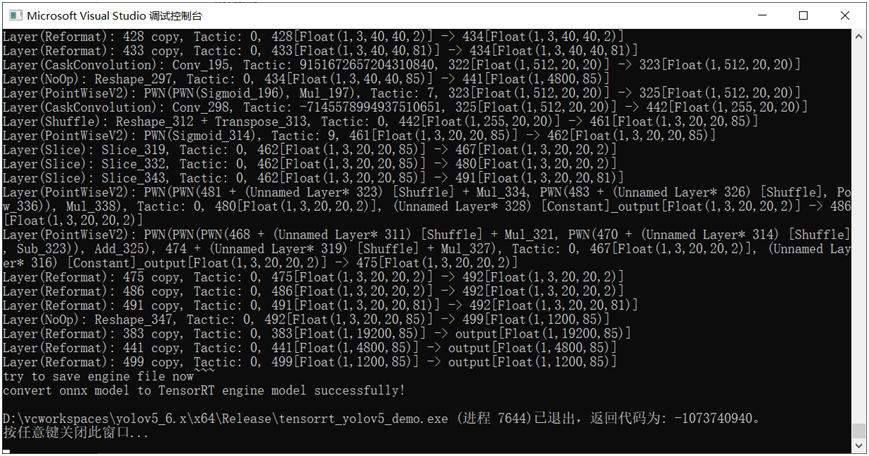
相关方法实现代码如下:
void YOLOv5TRTDetector::onnx2engine(std::string onnxfilePath, std::string enginefilePath, int type) {
IBuilder* builder = createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
auto parser = nvonnxparser::createParser(*network, gLogger);
parser->parseFromFile(onnxfilePath.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i)
{
std::cout << "load error: "<< parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建推理引擎
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(16*(1 << 20));
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
auto myengine = builder->buildEngineWithConfig(*network, *config);
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream p(enginefilePath, std::ios::binary);
if (!p) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
IHostMemory* modelStream = myengine->serialize();
p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
modelStream->destroy();
myengine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}常见错误:
Error Code 1: Cuda Runtime (driver shutting down)Unexpected Internal Error: [virtualMemoryBuffer.cpp::~StdVirtualMemoryBufferImpl::121] Error Code 1: Cuda Runtime (driver shutting down)Unexpected Internal Error: [virtualMemoryBuffer.cpp::nvinfer1::StdVirtualMemoryBufferImpl::~StdVirtualMemoryBufferImpl::121] Error Code 1: Cuda Runtime (driver shutting down)
要释放,不然就是上面的错误
context->destroy();
engine->destroy();
network->destroy();
parser->destroy();这样就好啦
YOLOv5 engine模型加载与推理
分别转换为32FP与16FP的engine文件之后,执行推理代码与运行结果如下:
std::string label_map = "D:/python/yolov5-6.1/classes.txt";
int main(int argc, char** argv) {
std::vectorclassNames;
std::ifstream fp(label_map);
std::string name;
while (!fp.eof()) {
getline(fp, name);
if (name.length()) {
classNames.push_back(name);
}
}
fp.close();
auto detector = std::make_shared();
detector->initConfig("D:/python/yolov5-6.1/yolov5s.engine", 0.4, 0.25);
std::vectorresults;
cv::VideoCapture capture("D:/images/video/sample.mp4");
cv::Mat frame;
while (true) {
bool ret = capture.read(frame);
detector->detect(frame, results);
for (DetectResult dr : results) {
cv::Rect box = dr.box;
cv::putText(frame, classNames[dr.classId], cv::Point(box.tl().x, box.tl().y - 10), cv::FONT_HERSHEY_SIMPLEX, .5, cv::Scalar(0, 0, 0));
}
cv::imshow("YOLOv5-6.1 + TensorRT8.4 - by gloomyfish", frame);
char c = cv::waitKey(1);
if (c == 27) { // ESC 退出
break;
}
// reset for next frame
results.clear();
}
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}运行结果:
FP32上推理,速度在80+FPS左右
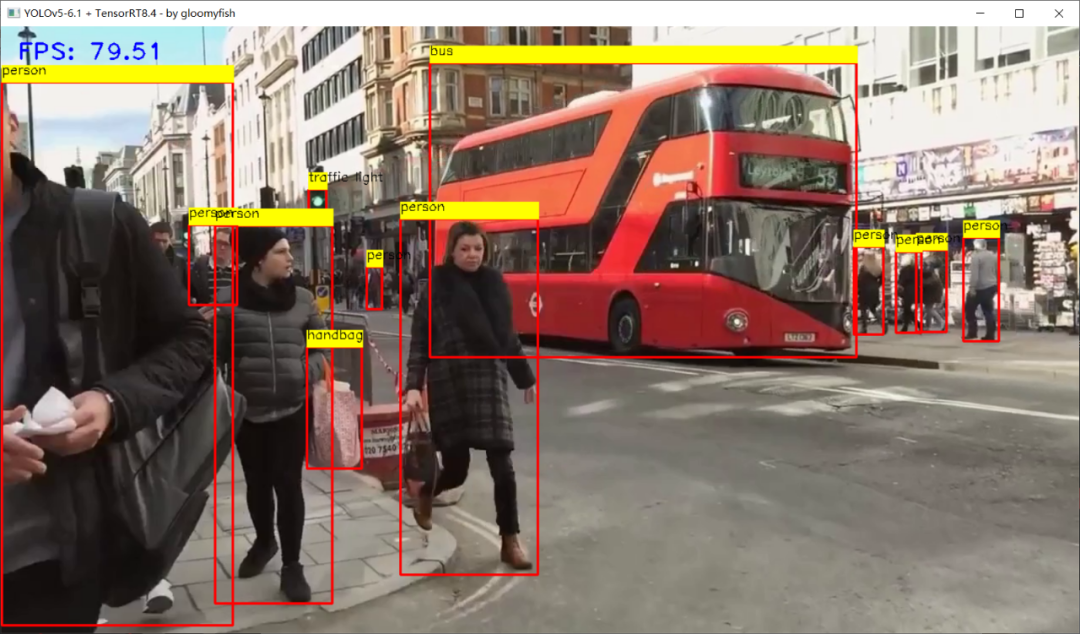
FP16上推理,速度达到100+FPS左右,TensorRT8.4.0

总结
TensorRT推理一定要及时释放资源,YOLOv5 第六版实际输出的四个输出层。只解析output层输出即可。先把模型导出onnx格式然后再通过tensorRT导出为engine文件,简单快捷!网上有很多文章都是以前写的,不太可信,建议少参考!直接加载engine文件推理,速度在我的笔记本3050ti上可达100FPS左右!















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









