







python的mark
1.pandas批量修改某些行的一些列
test = [[1,2,3],[1,2,1],[11,2,3]]
df = pd.DataFrame(test)
print(df)
df.iloc[[1,2], 2] = np.nan
print(df)
结果:
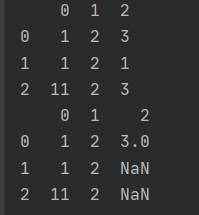
注意:df.iloc[[1,2], 2] = np.nan中[1,2]是列表
2.pandas写入数据库不支持NaN(生气!!!找了半天问题)
如果你是生成缺失值的数据集的话,绕开
df_temp.to_csv(path, header=False, index=False)
可以采用我之前的博文中提到的
def write_csv(path, data):
csvFile = open(path, 'w',newline='')
writer = csv.writer(csvFile)
m = len(data)
for i in range(m):
writer.writerow(data[i])
csvFile.close()
注意:这里data需要是列表类型
python pandas 一次修改指定列的多行的数据,(刚开始用的iloc一直替换不成功)
df_missing.loc[alopecia_missing_index, 'Alopecia'] = np.nan
这样就可以了,采用loc去定位,alopecia_missing_index是列表,'Alopecia’是列名















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









