






文章目录
- 1.核函数一般是void
- 2.共享内存
- 3.__syncthreads()有什么用
- 4.一些运行代码MPI(MPI_Bcast)
- 5.threadId = blockIdx.x * blockDim.x + threadIdx.x
- 6.OpenMP、CUDA和MPI分别是什么,有什么区别
- 7.mpi的hostfile中一般有什么内容,分别是什么意思
- 8.MPI 的hostfile中,如果每个主机名后还有slots=2,这是什么意思
- 9.MPI_Get_processor_name函数怎么用
- 10.在ubuntu系统中,IP 地址和主机名有什么区别,本机/etc/hostname中的是IP地址还是主机名或者都不是
- 11. 穿行复习
1.核函数一般是void
有__global__关键字一般是核函数(kernel function),且是void函数;如果需要返回值,可以通过传递指向变量的指针,并在核函数内部修改这个指针指向的值来实现(而不是int函数+return)
2.共享内存
在GPU编程中,共享内存是一种特殊的内存类型,它在同一个线程块(block)内的线程之间共享数据。在进行矩阵转置等计算密集型任务时,合理使用共享内存可以显著提高访存效率,从而提高整体性能。下面是使用和不使用共享内存的一些主要区别:
不使用共享内存的情况:
- 全局内存访问: 在没有使用共享内存的情况下,每个线程需要从全局内存中读取数据,这可能导致高延迟的内存访问。
- 冗余数据读取: 如果多个线程需要访问相同的数据,它们会分别从全局内存中读取相同的数据,导致冗余的读取操作。
- 存储器访问冲突: 多个线程同时写入相邻的内存位置可能导致存储器访问冲突,从而降低性能。
使用共享内存的情况:
- 数据共享: 共享内存允许线程块内的线程之间共享数据。这对于存储矩阵等共享数据结构非常有用,避免了冗余的全局内存读取。
- 减少全局内存访问: 可以将一部分数据加载到共享内存中,减少对全局内存的访问次数,从而提高访存效率。
- 减少存储器访问冲突: 由于共享内存只在线程块内部共享,减少了多个线程同时写入相邻内存位置的可能性,减少存储器访问冲突。
- 提高局部性: 使用共享内存可以提高线程块内数据的局部性,从而更有效地利用缓存。
在进行矩阵转置等涉及大规模数据操作的任务时,使用共享内存通常可以显著提高性能。然而,共享内存的使用需要开发人员精心设计和管理,以确保正确性和性能的平衡。
3.__syncthreads()有什么用
__syncthreads() 是 CUDA 编程中的一个同步函数,用于在线程块内部同步线程。在 CUDA 核函数内部,线程块中的各个线程是并行执行的,而 __syncthreads() 的作用是确保在该函数调用点之前的所有线程都完成了其前面的工作,然后再继续执行后面的代码。
具体来说,__syncthreads() 的作用有以下几个方面:
- 线程同步: 在执行到 __syncthreads() 时,所有线程将被阻塞,直到该线程块中的所有线程都达到这个同步点。这确保了在同步点之前的所有工作都已完成。
- 共享内存的一致性: 在线程块中,各个线程可以访问共享内存。使用 __syncthreads() 可以确保一个线程对共享内存的修改对其他线程可见,即保持共享内存的一致性。
需要注意的是,__syncthreads() 只能在线程块内使用,不能在不同线程块之间同步。同时,不同线程块之间的同步需要使用更高级别的同步机制,例如通过全局内存进行通信。
在使用 __syncthreads() 时,需要小心避免死锁和不正确的同步使用。特别是,确保每个线程都能够到达 __syncthreads(),否则可能导致死锁。此外,避免在分支语句中出现不同线程执行路径上的 __syncthreads(),因为这可能导致不同线程之间的同步问题。
4.一些运行代码MPI(MPI_Bcast)
在 MPI 中,集体通信函数(如 MPI_Bcast)是同步的,这意味着调用这些函数的所有进程都必须在通信操作完成之前等待。对于 MPI_Bcast,只有根进程(广播的源头,即 root 参数指定的进程)调用该函数时会发生数据传输。其他非根进程在调用 MPI_Bcast 时只是等待数据的到来。
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm);
其中:
- buffer:指向要广播的数据的指针。
- count:广播的数据元素数量。
- datatype:广播的数据类型。
- root:广播的根进程,即从该进程开始广播数据。
- comm:通信器,指定了广播的通信域。
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int data;
if (rank == 0) {
// 根进程设置数据
data = 42;
}
// 广播数据
MPI_Bcast(&data, 1, MPI_INT, 0, MPI_COMM_WORLD);
// 所有进程输出接收到的数据
printf("Process %d received data: %d\n", rank, data);
MPI_Finalize();
return 0;
}
在这个例子中,根进程是 rank 为 0 的进程,它设置了数据并通过 MPI_Bcast 广播给其他进程。其他进程通过 MPI_Bcast 接收数据。虽然通常将根进程的 rank 设置为 0,但你也可以选择其他 rank 作为根进程,只需相应地更新 MPI_Bcast 的 root 参数即可。
MPI_Send
在MPI中,MPI_Send用于将消息发送给指定的接收者。以下是MPI_Send的基本用法:
#include <mpi.h>
int MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
参数说明:
1.buf: 发送缓冲区的起始地址。
2.count: 发送的元素数量。
3.datatype: 发送元素的数据类型。
4.dest: 目标进程的rank。
5.tag: 消息标签,用于区分不同类型的消息。
6.comm: 通信子,通常使用MPI_COMM_WORLD表示全局通信。
以下是一个简单的例子,演示如何使用MPI_Send发送一个整数:
#include <stdio.h>
#include <mpi.h>
int main() {
MPI_Init(NULL, NULL);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int data = 42;
if (rank == 0) {
// 在进程0中发送数据给进程1
MPI_Send(&data, 1, MPI_INT, 1, 0, MPI_COMM_WORLD);
} else if (rank == 1) {
// 在进程1中接收从进程0发送过来的数据
MPI_Recv(&data, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Received data: %d\n", data);
}
MPI_Finalize();
return 0;
}
在这个例子中,进程0发送一个整数42给进程1。请注意,发送和接收的数据类型、数量和标签必须匹配,否则会导致不确定的行为。这个例子中的MPI_Status参数被设为MPI_STATUS_IGNORE,因为我们不关心接收操作的状态。
需要注意的是,MPI_Send是一个阻塞操作,它会等待直到消息被成功发送。在实际应用中,可能需要使用非阻塞的发送操作,如MPI_Isend,以提高程序的性能。
MPI_Recv
5.threadId = blockIdx.x * blockDim.x + threadIdx.x
二维同理有
int i = blockIdx.x * blockDim.x + threadIdx.x
int y = blockIdx.y * blockDim.y + threadIdx.y
而输入<<<gridSize, blockSize>>>时,若是1维,则这两都可以是int型,若是二维则这两个数据类型为dim3
#define BLOCK_SIZE 16
dim3 blockSize(BLOCK_SIZE, BLOCK_SIZE);
dim3 gridSize((cols + blockSize.x - 1) / blockSize.x, (rows + blockSize.y - 1) / blockSize.y);
6.OpenMP、CUDA和MPI分别是什么,有什么区别
OpenMP、CUDA和MPI都是用于并行计算的工具或框架,但它们在设计理念、应用场景和实现方式上有一些显著的区别。
1.OpenMP(Open Multi-Processing):
- 定义: OpenMP 是一种并行编程的标准,旨在简化共享内存多处理器系统上的并行程序设计。它基于指导性编程,通过在现有代码中插入一些编译器指令,使得程序员能够将代码段标记为并行执行的区域。
- 应用: 主要用于共享内存体系结构,如多核处理器或对称多处理器(SMP)系统。
- 优点: 相对容易使用,适合于共享内存环境下的任务并行。
2.CUDA(Compute Unified Device Architecture):
- 定义: CUDA 是由 NVIDIA 开发的一种通用并行计算架构。它允许开发人员使用类C语言编写程序,利用 NVIDIA GPU 进行通用目的计算。
- 应用: 主要用于图形处理单元(GPU)上的并行计算,适用于数据密集型和并行度高的任务。
- 优点: 非常适合于大规模并行计算,特别是在科学计算、深度学习和图形处理等领域。
3.MPI(Message Passing Interface):
- 定义: MPI 是一种消息传递编程模型,用于实现在不同计算节点上运行的进程之间的通信。它允许在分布式内存系统中实现并行计算。
- 应用: 主要用于集群或分布式计算环境,其中各个计算节点具有独立的内存空间。
- 优点: 适用于解决大规模问题,特别是涉及到多个计算节点之间通信的情况。
区别总结:
1.OpenMP 主要用于共享内存系统,通过指导性编程实现简单的任务并行。
2.CUDA 面向 NVIDIA GPU,用于大规模数据并行计算,特别是适用于科学计算和深度学习。
3.MPI 用于分布式内存系统,允许不同计算节点之间进行消息传递,适用于大规模、高度分布式的并行计算任务。
在一些应用场景中,这三种技术也可以结合使用,例如在一个大规模集群中,使用MPI进行节点之间的通信,而在每个节点上使用OpenMP或CUDA进行节点内的并行计算。
7.mpi的hostfile中一般有什么内容,分别是什么意思
每一行是主机名(hostname,而不是ip)。下图意味着 MPI 程序将在 node1、node2 和 node3 这三个计算节点上执行。
node1
node2
node3
运行例子,即在命令中加入-hostname xx
mpiexec -hostfile hostfile ./mpi_omp_hello
需要注意的是,MPI 的hostfile并不是必需的,如果没有指定hostfile,MPI 通常会在运行时使用系统的资源管理器来确定节点。使用hostfile的一个常见场景是在一些没有集成资源管理器的环境中,手动指定计算节点。
8.MPI 的hostfile中,如果每个主机名后还有slots=2,这是什么意思
例子:(这是hostfile文件里的)
node1 slots=2
node2 slots=4
node3 slots=1
在这个例子中,node1 可以运行两个 MPI 进程,node2 可以运行四个 MPI 进程,而 node3 只能运行一个 MPI 进程。
9.MPI_Get_processor_name函数怎么用
10.在ubuntu系统中,IP 地址和主机名有什么区别,本机/etc/hostname中的是IP地址还是主机名或者都不是
在 Ubuntu 系统中,IP 地址和主机名是两个不同的概念。
-
IP 地址: IP 地址是一个用于在网络中唯一标识主机的数字标识符。它允许计算机在网络上相互通信。IP 地址通常是由 DHCP(Dynamic Host Configuration Protocol)协议分配的,或者是手动配置的。你可以在 Ubuntu 系统中使用命令
ifconfig或ip addr来查看当前主机的 IP 地址。 -
主机名: 主机名是计算机在网络上的人类可读标识符。它通常是一个与 IP 地址相关联的易于记忆的名称。主机名有时可以通过 DNS(Domain Name System)解析为相应的 IP 地址。在 Ubuntu 系统中,你可以通过 /etc/hostname 文件来查看和设置主机名。
/etc/hostname 文件包含当前主机的主机名。你可以使用文本编辑器(如 nano 或 vim)打开这个文件:
sudo nano /etc/hostname
或
sudo vi /etc/hostname
这个文件中应该只包含主机名,而不是 IP 地址。例如:
myhostname
主机名也可以通过 hostname 命令来查看或设置:
查看:
hostname
设置:
sudo hostname your_new_hostname
(注意需要重启/重启网络设置后生效)
11. 穿行复习
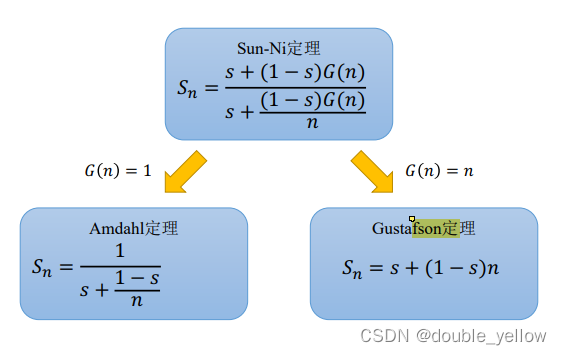
并行计算性能评估
- amdahl定理:S=时间比=串行时间/并行时间=并行工作量/串行工作量,有s的串行比例,T/(sT+(1-s)T/n)=1/(s+(1-s)/n).
gustanfson定理:S=

OpenMP
基于OpenMP的并行编程
} OpenMP简介
} 创建并行区域
} 并行循环
#include <omp.h>
# pragma omp parallel num_threads(threads_conut)
int rank = omp_get_thread_num();
int thread_conut = omp_get_num_threads();
xxx
#pragma omp critical
} 同步
} 数据共
循环折叠

OpenMP 3.0 任务(Task)
判断属性

一般是parallel/ single/ task同时存在(还有taskwait)

CUDA
- Warp是32个线程的线程束, 在一个Warp中的32个线程会同时执行相同的指令,这就是所谓的SIMT(Single Instruction, Multiple Threads)执行模型(SIMT(Single Instruction, Multiple Threads)GPU中的SIMT(Single Instruction, Multiple Threads)架构允许warp中的线程执行相同的指令,但可以有不同的数据。这种执行模型非常适合处理大量数据并行的任务,如图形处理、科学计算等)。线程以线程块(Block)大小为粒度被分配给SM,SM以Warp为单位启动一组线程(二级并行),就绪的线程以Warp为单位被SM调度和执行。
通常在一个block内有多个warp(所以一般线程数是32的倍数),如果线程块block内线程数不是32的倍数,那么多出来的几个也是一个没被填满的warp,会导致“occupancy degradation”,这可能导致一些线程在执行时被掩蔽(masked),从而浪费了一些计算资源。

- 基于图形处理器(Graphics Processing Unit, GPU)的计算简介
处理器发展历史
!架构
– GPU架构的两个主要组成部分:
- 全局存储(Global memory)
!类似于CPU服务器中的主存
!GPU 和 CPU 均可访问 - 流式多处理器[Streaming Multiprocessors, SMs]
!执行计算
!SM拥有:
F 控制单元
F 寄存器
F 执行流水线
F 缓存
– GPU 内存层次结构: 寄存器,L1缓存/共享内存,L2缓存,全局内存(分别是什么)
共享内存(Shared Memory):
特点: 共享内存是**每个线程块(block)**共享的存储区域,可用于线程块内的数据共享和快速交换。
– warp是什么,SM和GPU的关系,Warp是 SM 中的调度单位
- 统一计算架构编程模型(Compute Unified Device Architecture, CUDA)基础
!工作流
– CUDA是一种面向异构计算的通用编程模型,用户可通过它在 GPU 上生成大量线程
– 在 CUDA 中,主机(即 CPU)和设备(即 GPU)各自拥有独立的内存空间
!基本接口
– CUDA 内核函数,线程块内的线程通过共享内存、原子操作和同步屏障进行合作,不同线程块中的线程无法合作
预定义内置变量
!dim3 gridDim:网格大小
!dim3 blockDim: 线程块大小
!dim3 blockIdx:线程块的三维索引
!dim3 threadIdx:线程的三维索引
__global __ 用于定义内核函数,只能是void
在 CUDA 中,调用内核默认是异步操作,当 CPU 遇到同步 CUDA 应用程序接口(如 cudaMemcpy())时,它会等待前一个内核函数执行完毕。同步 CUDA 应用程序接口 cudaDeviceSynchronize() 可用于阻塞 CPU,直到 GPU 完成之前请求的所有任务
– CUDA 内核函数有以下限制:只能访问设备内存,返回值必须为void,不支持可变数量的参数,不支持静态变量,不支持函数指针(后三个意思是函数是固定的)
cuda分配和释放(cuda即使是对指针malloc,也要取地址)
TILE_WIDTH = 64;
float* M_d;
int size = TILE_WIDTH * TILE_WIDTH * sizeof(float);
//我们可以看到,即使是对指针malloc,也要取地址
//free时不用取地址
cudaMalloc((void**)&M_d, size);
cudaFree(M_d);
//对CPU的话就不用再取一遍地址
int*d_a= 0, *h_a= 0; // device and host pointers
h_a= (int*)malloc(num_bytes);
cudaMalloc((void**)&d_a, num_bytes);
cuda赋值
int *M_d, *M, *d_a;
//从后到前传
cudaMemcpy(M_d, M, size, cudaMemcpyHostToDevice);
//置0的
cudaMemset(d_a, 0, num_bytes);
内核函数
__global__ void vecAdd( float *A, float *B, float *C, int n)
{
// locate the memory
int i = threadIdx.x + blockDim.x * blockIdx.x;
// perform the addition
if(i < n) C[i] = A[i] + B[i];
}
//调用
vecAdd<<< ceil(n/256.0), 256 >>>(d_A, d_B, d_C, n)
示例
```c
#include <cuda.h>
#include <stdio.h>
int main() {
int dimx= 16;
int num_bytes= dimx* sizeof(int);
int*d_a= 0, *h_a= 0; // device and host pointers
h_a= (int*)malloc(num_bytes);
cudaMalloc((void**)&d_a, num_bytes);
if (0 == h_a|| 0 == d_a) {
printf("couldn't allocate memory\n");
return 1;
}
cudaMemset(d_a, 0, num_bytes);
cudaMemcpy(h_a, d_a, num_bytes, cudaMemcpyDeviceToHost);
for (int i= 0; i< dimx; i++)
printf("%d\n", h_a[i]);
free(h_a);
cudaFree(d_a);
return 0;
}
MPI
- MPI面向分布式内存系统,是编写消息传递程序的标准,多进程消息传递
- 通信域(Communicator):进程组,所有进程叫MPI_COMM_WORLD;序号(Rank):
- 六个MPI核心函数
函数名 描述
- MPI_Init 初始化MPI
示例:MPI_Init(&argc, &argv); - MPI_Comm_size 返回进程总数
int MPI_Comm_size(MPI_Comm comm, int* comm_sz_p) :获取组内进程的数量(通信域)
实例:int size; MPI_Comm_size(MPI_COMM_WORLD, &size); - MPI_Comm_rank 返回当前进程的rank
int MPI_Comm_rank(MPI_Comm comm, int* my_rank_p) :获取当前进程的rank
实例:int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank);
注意:rank和size传的是地址 - MPI_Send 发送一个消息
int MPI_Send( void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
示例:
– MPI_Send(A+isrown, srow * n, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
– MPI_Send(y, srow, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD)
注意:buf传的是地址 - MPI_Recv 接收一个消息
int MPI_Recv(void* buf, int maxsize, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status* status_p);
示例:
//可以看到是没有前后
MPI_Recv(A, srow * n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(y+i*srow, srow, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Status包含:
1.消息中的数据量是多少?
2.谁是发送方?(如果使用 MPI_ANY_SOURCE)
3.消息的tag是什么(如果使用 MPI_ANY_TAG)
- MPI_Finalize 终止MPI
示例: MPI_Finaliz();
还有
- int MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int root,MPI_Comm comm);示例:MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
- int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm);示例:MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD)
- double MPI_Wtime()
返回从过去任意时间开始的时间(以秒为单位)
在程序段开始和结束时调用它然后相减
- 输入与输出:所有进程都可以输出,只有MPI_COMM_WORLD 中的进程 0 才允许访问 stdin,即输入
- 阻塞与非阻塞通信
} 阻塞消息传递: 一个阻塞消息传递的操作不会返回,直到这个操作完成(MPI_Send 与 MPI_Recv 都是阻塞操作)
} 阻塞问题:空转开销(一方等一方),死锁
} 非阻塞:避免死锁,效率高,复杂的程序设计
} 可以一个进程用非阻塞发送,一个进程用阻塞接收。(但是没有例子所以不会,难道不用request吗)
} 非阻塞操作:
-
int MPI_Isend( void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request request / out */);
request 是一个指向请求对象的指针,它被 MPI_Test 和 MPI_Wait 函数用于识别哪些是我们想要
查询或等待其结束的操作 -
int MPI_Irecv(void* buf, int maxsize, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request* request);
-
int MPI_Test(MPI_Request *request, int *flag,
MPI_Status *status);
用request测试非阻塞发送或接收是否完成
} request 用于识别非阻塞操作,如果操作已经完成,请求对象将被释放
} flag 将被置为 true (non-zero in C/C++) 如果非阻塞操作已经完成,否则被置为false (0 in C/C++)
} status 将被设置为包含有关该操作的信息如果非阻塞操作已经完成 -
int MPI_Wait( MPI_Request *request, MPI_Status *status);
MPI_Wait会阻塞,直到非阻塞操作(由参数标识)完成为止
-
MPI 派生数据类型
-
} 集合通信
} 基础集合通信
reduce不太懂
数据都有3个信息
要看不同命令数据传递方式(比如前到后)
scatter和gather操作的本质(数据分和合吗)
reduce(某操作结果的合)
reduce的四种方法
} 高级集合通信 -
} 示例学习














 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









