






目的:
解决不完全多视图表示学习中的两个问题
1)如何学习统一不同视图的一致表示(Autoencoder网络实现)
2)如何恢复丢失的视图(Prediction网络实现)
具体做法:
两种网络,四个损失函数
网络:
①Autoencoder:编码:将RGB和Depth图片转到相同维度(同一子空间);解码:再还原到原来样子
②Prediction:编码+解码 = forward:将autoencoder中间维度的信息,由RGB转为Depth(或D到R)
损失函数:
①让图片经过Autoencoder网络编码解码后,数据基本不变 -> reconstruction_loss重构损失
②让图片经过Autoencoder网络编码,并由Prediction网络做RGB转Depth或D转R后,数据更相似 -> dualprediction_loss双重预测损失
③让不同类的Z1,Z2差别更大 -> category_contrastive_loss
④让同一类的Z1,Z2更相似 -> instance_contrastive_Loss
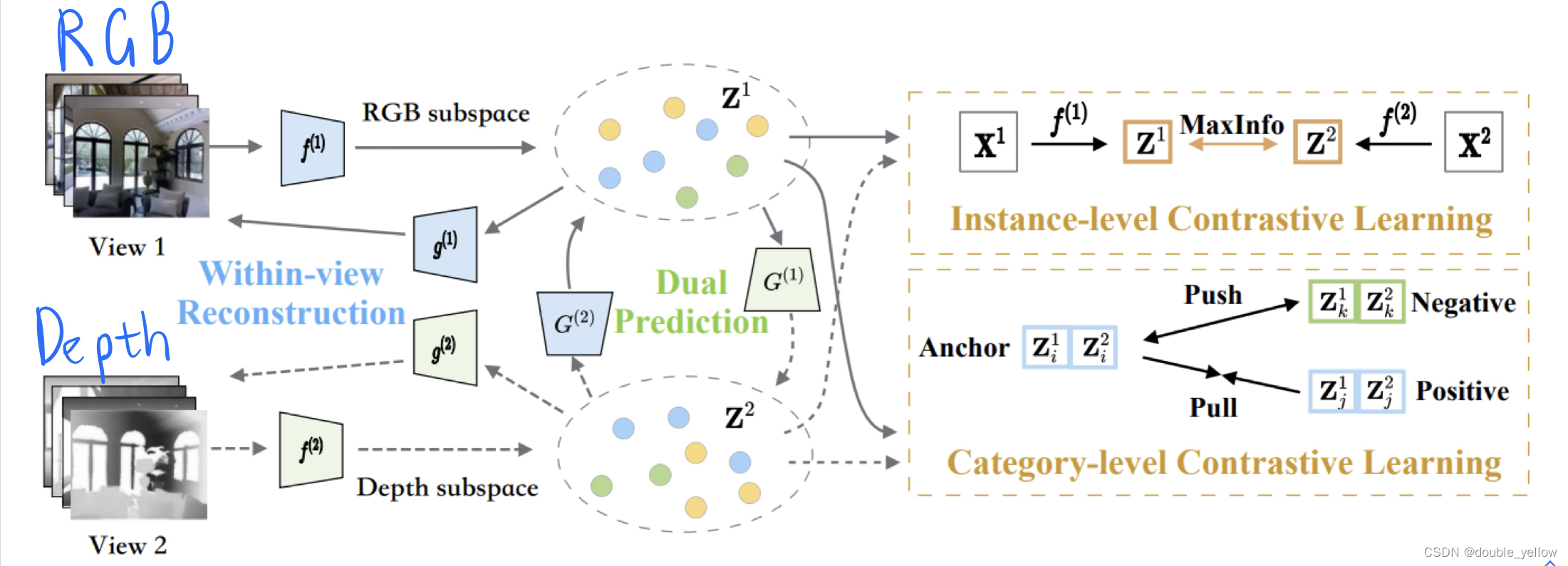
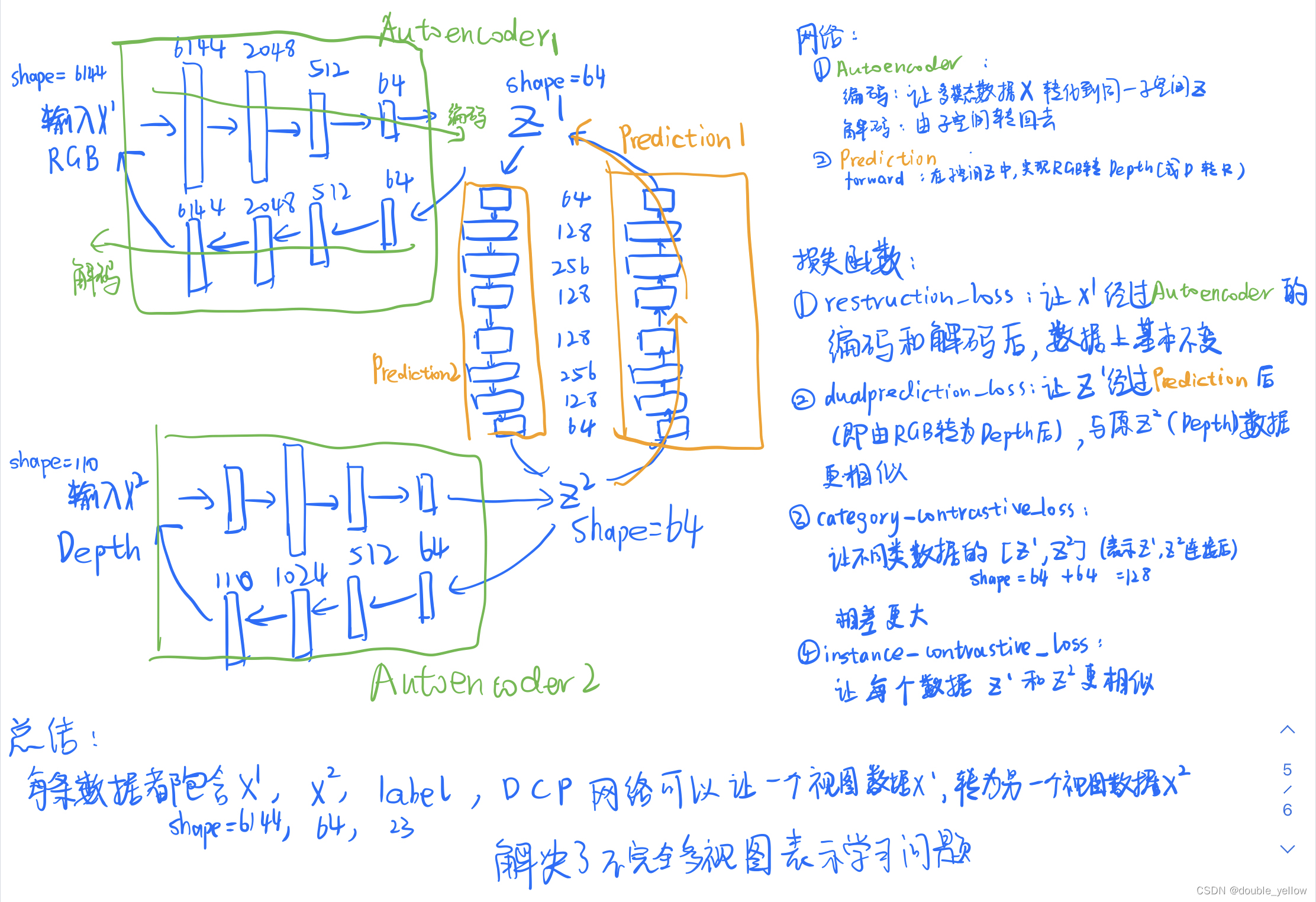
对应损失3和4















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









