






这一章介绍如何读写CSV文件。首先介绍在不使用Python内置的csv模块情况下“手动”解析CSV格式的输入文件的一个列子。随后说明这种解析方法的潜在问题。
一、读写CSV文件

二、筛选特定的行
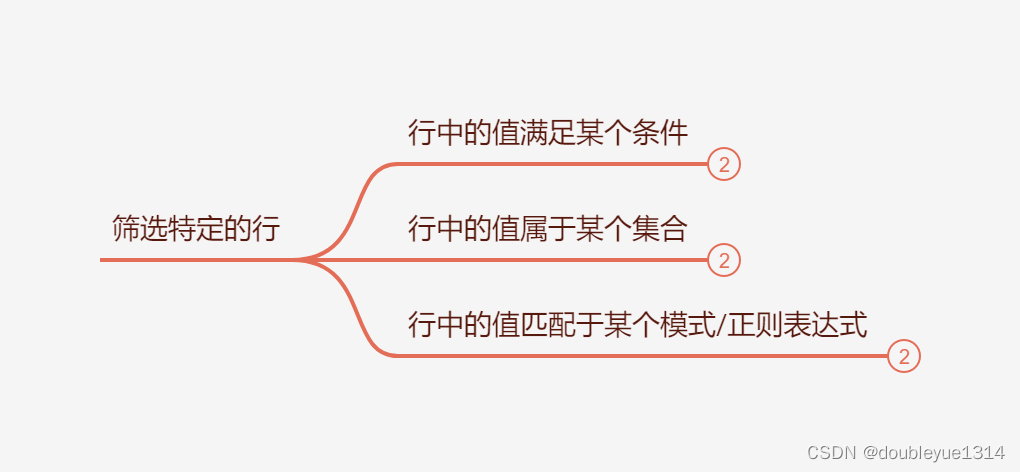
行中的值满足某个条件,两种方法:
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
supplier = str(row_list[0]).strip()
cost = str(row_list[3]).strip('$').replace(',','')
if supplier == 'Supplier Z' or float(cost) > 600.00:
filewriter.writerow(row_list)import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame['Cost'] = data_frame['Cost'].str.strip('$').astype(float)
data_frame_value_meets_conditon = data_frame.loc[(data_frame['Supplier Name'].str.contains('Z')) | (data_frame['Cost'] > 600.0),:]
data_frame_value_meets_conditon.to_csv(output_file,index=False)行中的值属于某个集合,两种方法:
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
important_dates = ['1/20/14','1/30/14']
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
a_date = row_list[4]
if a_date in important_dates:
filewriter.writerow(row_list)import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
important_dates = ['1/20/14','1/30/14']
data_frame_value_in_set = data_frame.loc[data_frame['Purchase Date'].isin(important_dates),:]
data_frame_value_in_set.to_csv(output_file,index=False)行中的值匹配于某个模式/正则表达式,两种方法:
import csv
import re
import sys
input_file = sys.argv[1]
output_file =sys.argv[2]
pattern = re.compile(r'(?P<my_pattern_group>^001-.*)',re.I)
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
invoice_number = row_list[1]
if pattern.search(invoice_number):
filewriter.writerow(row_list)import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_value_matches_pattern = data_frame.loc[data_frame['Invoice Number'].str.startswith("001-"),:]
data_frame_value_matches_pattern.to_csv(output_file,index=False)三、选取特定的列
列索引值,两种方法:
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
my_columns = [0,3]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row_list in filereader:
row_list_output = [ ]
for index_value in my_columns:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_column_by_index = data_frame.iloc[:,[0,3]]
data_frame_column_by_index.to_csv(output_file,index=False)四、选取连续的行
import csv
import sys
input_file = sys.argv[1]
output_file =sys.argv[2]
row_counter = 0
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row in filereader:
if row_counter >= 3 and row_counter <= 15:
filewriter.writerow([value.strip() for value in row])
row_counter += 1import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file,header=None)
data_frame = data_frame.drop([0,1,2,16,17,18])
data_frame.columns = data_frame.iloc[0]
data_frame = data_frame.reindex(data_frame.index.drop(3))
data_frame.to_csv(output_file,index=False)五、添加标题行
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header_list = ['Supplier name','Invoice Number','Part Number','Cost','Purchase Date']
filewriter.writerow(header_list)
for row in filereader:
filewriter.writerow(row)import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
header_list = ['Supplier Name','Invoice Number','Part Number','Cost','Purchase Date']
data_frame = pd.read_csv(input_file,header=None,names=header_list)
data_frame.to_csv(output_file,index=False)六、读取多个CSV文件
文件计数与文件中的行列计数:
import csv
import glob
import os
import sys
input_path = sys.argv[1]
file_counter = 0
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
row_counter = 1
with open(input_file,'r',newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
header = next(filereader, None)
for row in filereader:
row_counter += 1
print('{0!s}: \t{1:d} rows \t{2:d} columns'.format(os.path.basename(input_file),row_counter,len(header)))
file_counter += 1
print('Number of files: {0:d}'.format(file_counter))七、从多个文件中连接数据
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
first_file = True
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
print(os.path.basename(input_file))
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'a',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader,None)
for row in filereader:
filewriter.writerow(row)import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path,'sales_*'))
all_data_frames = []
for file in all_files:
data_frame = pd.read_csv(file,index_col = None)
all_data_frames.append(data_frame)
data_frame_concat = pd.concat(all_data_frames,axis=0,ignore_index=True)
data_frame_concat.to_csv(output_file,index=False)八、计算每个文件中值的总和与平均值
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
output_header_list = ['file_name','total_sales','average_sales']
csv_out_file = open(output_file,'a',newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
with open(input_file,'r',newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
output_list = [ ]
output_list.append(os.path.basename(input_file))
header = next(filereader)
total_sales = 0.0
number_of_sales = 0.0
for row in filereader:
sale_amount = row[3]
total_sales += float(str(sale_amount).strip('$').replace(',', ''))
number_of_sales += 1
average_sales = '{0:.2f}'.format(total_sales / number_of_sales)
output_list.append(total_sales)
output_list.append(average_sales)
filewriter.writerow(output_list)
csv_out_file.close()import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path,'sales_*'))
all_data_frames = []
for input_file in all_files:
data_frame = pd.read_csv(input_file, index_col=None)
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',', '')) \
for value in data_frame.loc[:, 'Sale Amount']]).sum()
average_sales = pd.DataFrame([float(str(value).strip('$').replace(',', '')) \
for value in data_frame.loc[:, 'Sale Amount']]).mean()
data = {'file_name': os.path.basename(input_file),
'total_sales': total_sales,
'average_sales':average_sales}
all_data_frames.append(pd.DataFrame(data, \
columns = ['file_name', 'total_sales', 'average_sales']))
data_frames_concat = pd.concat(all_data_frames,axis=0,ignore_index=True)
data_frames_concat.to_csv(output_file,index=False)注:本章代码均需在终端cmd模式下运行















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









