







需求:
假设现在需要对数据进行二分类,小于0.5的,打上0的标记,大于0.5的,打上1的标记,怎么做?
分析:
这是一个简单的二分类问题,使用逻辑回归模型。
代码:
# 导入所需的库,如需安装:pip install scikit-learn matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
# 创建一个随机的二分类数据集
np.random.seed(42)
X = np.random.rand(100, 1)
print("X:\n", X)
y = (X > 0.5).astype(int)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("X_train:\n", X_train)
# 创建并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 可视化决策边界
plt.scatter(X, y, color='blue', marker='o', label='Class 0')
plt.scatter(X_test, y_test, color='red', marker='x', label='Test Data')
plt.xlabel('Feature')
plt.ylabel('Class')
plt.legend()
plt.title('Logistic Regression Decision Boundary')
plt.axhline(0.5, color='green', linestyle='--', linewidth=2, label='Decision Boundary')
plt.show()
运行结果:
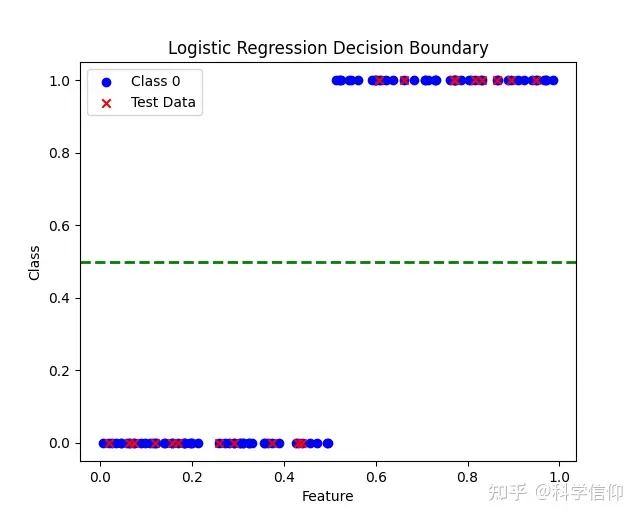
如图可见Test Data的标记都是正确的
执行下来的准确率:
Accuracy: 1.0
结论:模型预测使用测试集 (X_test) 进行预测,得到预测值 y_pred,都满足预期。















 5164
5164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











