







今天在知乎上看到一个问题:人脑有海量的神经元(参数),为什么没有过拟合?
面对各个网友的回答,突然发现自己对于过拟合的概念似乎理解的不是很透彻,或者说之前就没有完全理解透。
其中有个人这么说“样本少feature多才overfitting”

也有人提到

看红框标注部分,也就是说样本多就不会发生过拟合么。
先不管知乎这个问题了,为了搞清过拟合的概念,再次跑到wikipedia去搜寻答案。
下面是wikipedia对于overfitting的解释
Overfitting
在统计学和机器学习中,overfitting一般在描述统计学模型随机误差或噪音时用到。它通常发生在模型过于复杂的情况下,如参数过多等。overfitting会使得模型的预测性能变弱,并且增加数据的波动性。
发生overfitting是因为评判训练模型的标准不适用于作为评判该模型好坏的标准,模型通常会增强模型在训练模型的预测性能。但是模型的性能并不是由模型在训练集的表现好坏而决定,它是由模型在未知数据集上的表现确定的。当模型开始“memorize”训练数据而不是从训练数据中“learning”时,overfitting就出现了。比如,如果模型的parameters大于或等于观测值的个数,这种模型会显得过于简单,虽然模型在训练时的效果可以表现的很完美,基本上记住了数据的全部特点,但这种模型在未知数据的表现能力会大减折扣,因为简单的模型泛化能力通常都是很弱的。
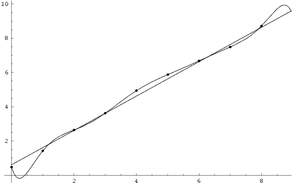
上面这个图,是通过线性函数和多项式函数来拟合这些数据点,显然多项式函数拟合效果很完美,包含了所有的点,而线性函数丢失了大部分点。但实际上,线性函数有一个很好的泛化能力,如果用这些点来做一个回归线,多项式函数过拟合的情况更糟糕。
过拟合不仅和参数的个数以及数据有关,也和数据形状模型结构的一致性有关。
为了避免过拟合,有必要使用一些额外的技术(如交叉验证、正则化、early stopping、贝斯信息量准则、赤池信息量准则或model comparison),以指出何时会有更多训练而没有导致更好的一般化。
Overfitting的概念在机器学习中很重要。通常一个学习算法是借由训练样本来训练的,在训练时会伴随着训练误差。当把该模型用到未知数据的测试时,就会相应的带来一个validation error。下面通过训练误差和验证误差来详细分析一下overfitting。如下图:
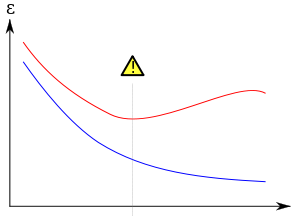
在上图总,蓝色表示训练误差training error,红色表示validation error。当训练误差达到中间的那条垂直线的点时,模型应该是最优的,如果继续减少模型的训练误差,这时就会发生过拟合。
其实你可以这样来理解overfitting:数据集中信息分为两部分,一部分是和预测未来数据有关的数据,另一部分是无关的,两者地位是平等的。用来作为预测的评判标准越不精确,表明噪声数据就越多,需要忽略掉的数据也就越多,而关键就是究竟那一部分应该忽略掉。所以我们把一个学习算法对噪声的削减能力就叫做它的鲁棒性。我们需要的就是鲁棒性很强的学习算法
举一个简单的例子,一个零售购物的数据库包括购买项、购买人、日期、和购买时间。根据这个数据可以很容易的建立一个模型,并且在训练集上的拟合效果也会很好,通过使用日期、购买时间来预测其它属性列的值,但是这个模型对于新数据的泛化能力很弱,因为这些过去的数据不会再次发生。
这样分析之后,可以看出,之前在知乎看到的“数据少特征多就发生过拟合”似乎有点道理。
相对于过拟合是指,使用过多参数,以致太适应当前数据而非一般情况,另一种常见的现象是使用太少参数,以致于不适应当前的训练数据,这则称为欠拟合(英语:underfitting,或称:拟合不足)现象。
References
1.wikipedia 的overfitting解释:https://en.wikipedia.org/wiki/Overfitting
2.http://blog.minitab.com/blog/adventures-in-statistics/the-danger-of-overfitting-regression-models















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









