| Object中的hashCode()和equals()定义 /** <p>
* As much as is reasonably practical, the hashCode method defined by
* class <tt>Object</tt> does return distinct integers for distinct
* objects. (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java<font size="-2"><sup>TM</sup></font> programming language.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.util.Hashtable
*/
public native int hashCode();
大意是:实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧。) /** The <tt>equals</tt> method for class <code>Object</code> implements
* the most discriminating possible equivalence relation on objects;
* that is, for any non-null reference values <code>x</code> and
* <code>y</code>, this method returns <code>true</code> if and only
* if <code>x</code> and <code>y</code> refer to the same object
* (<code>x == y</code> has the value <code>true</code>).
* <p>
* Note that it is generally necessary to override the <tt>hashCode</tt>
* method whenever this method is overridden, so as to maintain the
* general contract for the <tt>hashCode</tt> method, which states
* that equal objects must have equal hash codes.
*
* @param obj the reference object with which to compare.
* @return <code>true</code> if this object is the same as the obj
* argument; <code>false</code> otherwise.
* @see #hashCode()
* @see java.util.Hashtable
*/
public boolean equals(Object obj) {
return (this == obj);
}
大意是:Object 类的 equals 方法实现对象上差别可能性最大的相等关系;即,对于任何非空引用值x 和y,当且仅当x 和y 引用同一个对象时,此方法才返回true(x == y 具有值true)。 注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。 实际开发中,只有当对象需要进行equals比较时,才会对equals(Object obj)进行重写,至于hashCode()是否重写,JAVA倡议开发者最好也进行重写,至于原因,看完本文,相信你自己就明白了。 开发中使用最多的就是String的equals(Object obje)方法,判断两个String对象的内容是相同,但是Object类中的equals(Object obj)是拿两个对象的引用值进行比较,这明显不是我们需要的,所以String对equals(Object obj)进行了重写,同时我们也看到它对hashCode()也进行了重写. 看看String类中的equals(Object obj)的重写,看看它是怎样比较2个String对象的内容是否一致的。 public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = count;
if (n == anotherString.count) {
char v1[] = value;
char v2[] = anotherString.value;
int i = offset;
int j = anotherString.offset;
while (n-- != 0) {
if (v1[i++] != v2[j++])
return false;
}
return true;
}
}
return false;
}
这代码很浅显易懂,如果2个对象的引用值相等,那他们肯定是同一个对象,那么它们的内容肯定相同,返回true。如果2个对象的引用值不相等,说明它们是2个不同对象,并且进行比较的对象也是String类型的,那么就它们的内容的长度,如果长度相等,再把2个对象的内容按顺序一个个抽出来进行比较。 再来看看String中重写的hashCode()方法。 /**
* Returns a hash code for this string. The hash code for a
* <code>String</code> object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using <code>int</code> arithmetic, where <code>s[i]</code> is the
* <i>i</i>th character of the string, <code>n</code> is the length of
* the string, and <code>^</code> indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
int len = count;
if (h == 0 && len > 0) {
int off = offset;
char val[] = value;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}
返回此字符串的哈希码。String 对象的哈希码根据以下公式计算:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
使用 int 算法,这里 s[i] 是字符串的第 i 个字符,n 是字符串的长度,^ 表示求幂。(空字符串的哈希值为 0。)
看到这里,是不是认为我跑题了,呵呵,先别急,继续看下去。 对于Set<E>的实现类,比如HashSet<E>,对于初学者来说,他们只知道HashSet<E>中存储的对象都是唯一的,至于实现原理,他们就不探究了,但是对于有理想、有热血的程序猿来说,就要做到知其然,知其所以然。 看看下面的小例子。 package test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
public class Test2 {
public static void main(String[] args) {
Collection<String> list=new ArrayList<String>();
Collection<String> set=new HashSet<String>();
String s1=new String("abc");
String s2=new String("abc");
list.add(s1);
list.add(s2);
set.add(s1);
set.add(s2);
System.out.println(list);
System.out.println(set);
}
}
运行结果: [abc, abc]
[abc] 我们从源代码中找原因。 ArrayList<E>中的add(E e)方法。 public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
一看就明白,很简单,就是你增加一个对象,它不管你是不是和前面增加进行的有重复,反正就是把新对象放到数组中,所以你放多少个对象,就有多少个。 那么HashSet为什么打印出来的结果只有1个呢?也就是去掉了重复对象(是指equlas相等的对象)?那么代码是如何处理的呢?在看HashSet<E>中的add(E e)代码之前,先来看看这样一个问题。
假如,有10000个数据,我要求你把他们放到数组中并且去掉重复的。你会怎么做? 也许你会说,这还不容易,我每插一个数据到数组中前,都先遍历前面的数据,如果相等的,新数据就不插入了。是的,这是一种解决办法,如果数据量不大,时间消耗还是在可接收范围内的.但是如果数据量很大的话,最坏的情况是你每插入一个数据,都要把前面插入的所有数据拿出来一一和要即将插入的数据进行比较,判断是否可插入,这时的比较次数将会非常大,效率非常低,时间消耗超出可接收范围。
为了提高效率,JAVA采用了哈希原理,具体的可以百度,在这就不具体想说哈希原理了。哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。 回到上面的问题,java的处理,可以这样简单的描述,就是先定义一个数组hashTable,新对象要插入时,先调用对象的hashCode()方法,然后通过取模获得数组下标(为了简单说明,可以认为是这样的hashCode()%hashTable.length),这样就直接定位到hashTable的位置了。但是这样一来,如果多个对象取模后的值相同,就会造成冲突,数组中一个具体的为止只能放一个对象,为了解决冲突,你可以让数组的每个元素指向一个链表LinkedList,把取模后值相同的对象放到同一个linkedList对象中。  回到上面的数据比较问题,当即将要插入数据时,计算出新数据的对应的hashTable位置(e.hashCode()%hashTable.length),则把该为止的linkedlist取出进行遍历和新数据进行equals比较。这样就解决了每次数据插入时,都需要比较全部数据低效率问题了。 好了,有了上面的比较思想后,下面就容易看明白了。
再来看看HashSet<E>中的add(E e)方法.
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
代码中的map是HashMap对象,PRESENT是一个Object对象,那么跟踪进HashMap中的put(K key, V value) 方法来看看.
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
看第4行代码中有key.hashCode(),根据我们传进来的参数知道,这里的key是String类型的,所以key.hashCode()调用的是String中的HashCode();hash(key.hashCode())得到一个新的hash值。上面的例子中s1,s2的内容是一样的,根据String中的hashCode()方法计算得知s1.hashCode==s2.hashCode.在这一步得到的hash值也是一样的。所以它们都位于table中的同一个区域,接下来比较s1和s2的内容是否相同,如果相同,新对象就不插入了. 简单例子 有一个Personlei类,如果多个Person对象的name和age相同,就认为是同一个,用HashSet保存.
package com.fei;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
public class HashCodeTest {
public static void main(String[] args) {
Collection<Person> list=new ArrayList<Person>();
Collection<Person> set=new HashSet<Person>();
Person p1=new Person("张三",20);
Person p2=new Person("张三",20);
System.out.println("p1.hashCode="+p1.hashCode());
System.out.println("p2.hashCode="+p2.hashCode());
System.out.println("p1.equals(p2)=="+p1.equals(p2));
list.add(p1);
list.add(p2);
set.add(p1);
set.add(p2);
System.out.println(list.toString()+" list.size="+list.size());
System.out.println(set.toString()+" set.size="+set.size());
}
}
Person.java类,暂不重写hashCode().
package com.fei;
public class Person{
//为了减少代码,属性设问public
public String name;
public int age;
public Person(String name,int age){
this.name=name;
this.age=age;
}
@Override
public boolean equals(Object obj){
if(this==obj) return true;
if(obj instanceof Person){
Person anotherPerson=(Person)obj;
if(this.name.equals(anotherPerson.name) && this.age==anotherPerson.age)
return true;
}
return false;
}
@Override
public String toString(){
return "["+name+" "+age+" ]";
}
}
运行结果: p1.hashCode=4107599
p2.hashCode=4107601
p1.equals(p2)==true
[[张三 20 ], [张三 20 ]] list.size=2
[[张三 20 ], [张三 20 ]] set.size=2
运行结果显示,虽然p1.equals(p2)==true了,但是set中仍然没有去掉重复。通过上面学习,我们知道这是因为他们的hashCode不相等,虽然它们不处于同一个区域(hashTable中同一个链表),所以插入p2时,set误认为没重复的。要想达到去掉重复,这就需要重写hashCode()方法了。
package com.fei;
public class Person{
//为了减少代码,属性设问public
public String name;
public int age;
public Person(String name,int age){
this.name=name;
this.age=age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString(){
return "["+name+" "+age+" ]";
}
}
运行结果: p1.hashCode=776470
p2.hashCode=776470
p1.equals(p2)==true
[[张三 20 ], [张三 20 ]] list.size=2
[[张三 20 ]] set.size=1
现在set中去掉重复的了。如果你细心点,会发现怎么equals(Object obj)中的代码也变了呢?呵呵,这是因为我在eclipse下,使用了自动生成hashCode及equals的重写。 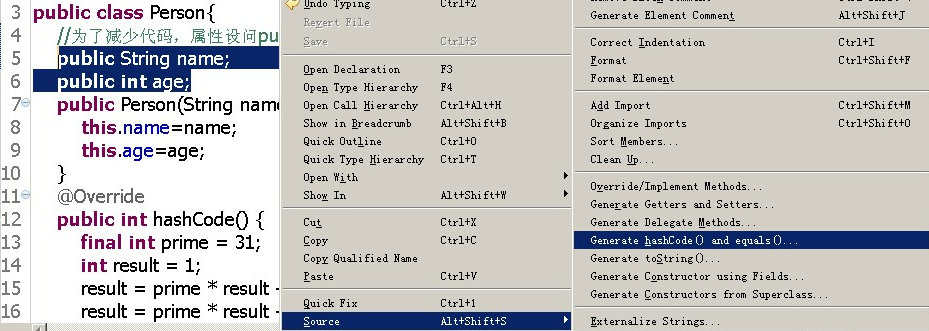
所以,可以这么说,你重写equals时,随便重写hashCode(),这是为了使用Set<E>的实现类HashMap,HashTable之类的类,准确的实现你的需求.
| 






















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









