




 本文深入解析主成分分析(PCA)算法,介绍PCA的数学原理、推导过程及应用,包括特征提取、数据降维和主成分选择等内容。
本文深入解析主成分分析(PCA)算法,介绍PCA的数学原理、推导过程及应用,包括特征提取、数据降维和主成分选择等内容。
主成分分析(Principle Component Analysis, PCA)是一种特征提取的方法,设 { X i } , i = 1 ∼ p \{X_i\},i=1\sim p {Xi},i=1∼p 是一组样本的输入,其中 X i = ( x i 1 , x i 2 , ⋯ , x i n ) T \displaystyle X_i=(x_{i1},x_{i2},\cdots,x_{in})^T Xi=(xi1,xi2,⋯,xin)T,PCA的目的是构造一个线性变换 Y = A X + b Y=AX+b Y=AX+b 把 n n n 维特征 X X X 转成 m m m 维特征 Y Y Y,实现数据的降维( n > m n \gt m n>m),每个量的维度为:
| parameter | shape |
|---|---|
| Y Y Y | ( m , 1 ) (m,1) (m,1) |
| A A A | ( m , n ) (m,n) (m,n) |
| X X X | ( n , 1 ) (n,1) (n,1) |
| b b b | ( m , 1 ) (m,1) (m,1) |
PCA可以看成是只一层的有 m m m个神经元的神经网络:
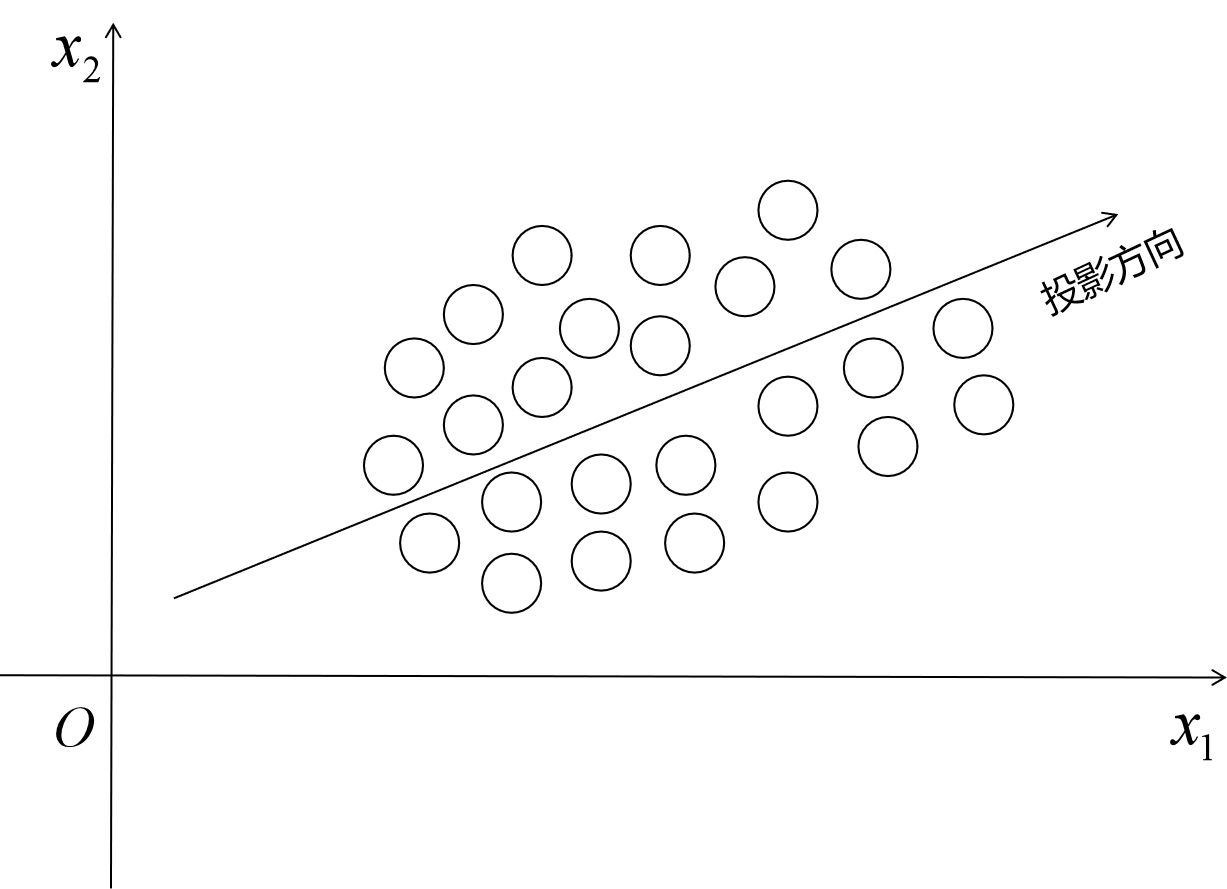
直观来说,PCA的目标是寻找方差最大方向,并在该方向投影,例如取 n = 2 , m = 1 n=2, m=1 n=2,m=1,则每个数据有2个维度的特征 x = ( x 1 , x 2 ) T x = (x_1,x_2)^T x=(x1,x2)T,将其投影到一个维度上,使数据在该维度上方差最大,这个方向就是 y = y 1 y = y_1 y=y1 如下图所示:
下面对PCA进行推导
设数据集为
{
X
i
}
,
i
=
1
∼
p
\{X_i\},i=1\sim p
{Xi},i=1∼p,我们采用如下线性变换来进行PCA:
{
Y
=
A
(
X
−
X
‾
)
X
‾
=
E
(
X
)
=
1
p
∑
i
=
1
p
X
i
\begin{aligned}\begin{cases}Y=A(X-\overline{X}) \\ \\ \overline{X}=E(X)=\displaystyle\frac{1}{p}\sum_{i=1}^{p}X_i \end{cases}\end{aligned}
⎩⎪⎪⎪⎨⎪⎪⎪⎧Y=A(X−X)X=E(X)=p1i=1∑pXi为了方便计算,设
A
=
(
a
1
a
2
⋮
a
m
)
A=\begin{pmatrix}a_{1}\\a_{2}\\ \vdots\\a_{m}\end{pmatrix}
A=⎝⎜⎜⎜⎛a1a2⋮am⎠⎟⎟⎟⎞,其中
a
i
=
(
a
i
1
,
a
i
2
,
⋯
,
a
i
n
)
,
i
=
1
∼
m
\displaystyle a_i=(a_{i1},a_{i2},\cdots,a_{in}),i=1\sim m
ai=(ai1,ai2,⋯,ain),i=1∼m,代入线性变换可得:
Y
i
=
(
a
1
(
X
i
−
X
‾
)
a
2
(
X
i
−
X
‾
)
⋮
a
m
(
X
i
−
X
‾
)
)
=
(
y
i
1
y
i
2
⋮
y
i
m
)
,
i
=
1
∼
p
(
y
i
j
是
1
×
1
的
矩
阵
也
就
是
数
)
Y_i=\begin{pmatrix}a_{1}(X_i-\overline{X})\\a_{2}(X_i-\overline{X})\\ \vdots\\a_{m}(X_i-\overline{X})\end{pmatrix}=\begin{pmatrix}y_{i1}\\y_{i2}\\ \vdots\\y_{im}\end{pmatrix},\quad i=1\sim p\quad(y_{ij}是1\times1的矩阵也就是数)
Yi=⎝⎜⎜⎜⎛a1(Xi−X)a2(Xi−X)⋮am(Xi−X)⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛yi1yi2⋮yim⎠⎟⎟⎟⎞,i=1∼p(yij是1×1的矩阵也就是数)我们已经说过,PCA是为了找到数据方差最大的
m
m
m个方向进行投影,所以我们的目标函数就是最大化
Y
i
Y_i
Yi 每个维度上数据的方差,即最大化数据序列
{
y
i
j
}
\{y_{ij}\}
{yij}的方差,其中
i
=
1
∼
p
,
j
=
1
∼
m
i=1\sim p,j=1\sim m
i=1∼p,j=1∼m,以
{
y
i
1
}
\{y_{i1}\}
{yi1}为例,最大化的目标函数是:
∑
i
=
1
p
(
y
i
1
−
y
i
1
‾
)
2
=
∑
i
=
1
p
y
i
1
2
=
∑
i
=
1
p
[
a
1
(
X
i
−
X
‾
)
]
2
=
∑
i
=
1
p
a
1
(
X
i
−
X
‾
)
(
X
i
−
X
‾
)
T
a
1
T
=
a
1
[
∑
i
=
1
p
(
X
i
−
X
‾
)
(
X
i
−
X
‾
)
T
]
a
1
T
=
a
i
∑
a
1
T
\begin{aligned} &\sum_{i=1}^{p}(y_{i1}-\displaystyle\overline{y_{i1}})^2\\ =&\displaystyle\sum_{i=1}^{p}y_{i1}^2 \\ =&\sum_{i=1}^{p}[a_1(X_i-\overline{X})]^2 \\ =&\displaystyle\sum_{i=1}^{p}a_1(X_i-\overline{X}) (X_i-\overline{X})^Ta_1^T\\ =&\displaystyle a_1[\sum_{i=1}^{p}(X_i-\overline{X}) (X_i-\overline{X})^T]a_1^T\\ =&a_i\sum a_1^T \end{aligned}
=====i=1∑p(yi1−yi1)2i=1∑pyi12i=1∑p[a1(Xi−X)]2i=1∑pa1(Xi−X)(Xi−X)Ta1Ta1[i=1∑p(Xi−X)(Xi−X)T]a1Tai∑a1T其中
∑
=
∑
i
=
1
p
(
X
i
−
X
‾
)
(
X
i
−
X
‾
)
T
\displaystyle\sum=\displaystyle\sum_{i=1}^{p}(X_i-\overline{X}) (X_i-\overline{X})^T
∑=i=1∑p(Xi−X)(Xi−X)T称为协方差矩阵(covariance matrix),显然
∑
=
∑
T
\displaystyle\sum=\displaystyle{\sum}^T
∑=∑T是对称矩阵,其维度为
n
×
n
n \times n
n×n
为什么 y i 1 ‾ = 0 \displaystyle\overline{y_{i1}}=0 yi1=0?
y i 1 ‾ = 1 p ∑ i = 1 p y i 1 = 1 p ∑ i = 1 p a 1 ( X i − X ‾ ) = a 1 p ∑ i = 1 p ( X i − X ‾ ) = a 1 p ( ∑ i = 1 p X i − ∑ i = 1 p X ‾ ) = a 1 p ( ∑ i = 1 p X i − p X ‾ ) = a 1 p × O = 0 \begin{aligned}\displaystyle\overline{y_{i1}}=& \displaystyle \frac{1}{p}\sum_{i=1}^p y_{i1}= \frac{1}{p}\sum_{i=1}^p a_{1}(X_i-\overline{X}) \\ = &\displaystyle\frac{a_1}{p}\displaystyle\sum_{i=1}^p (X_i-\overline{X})=\frac{a_1}{p}(\sum_{i=1}^p X_i-\sum_{i=1}^p\overline{X}) \\ =& \frac{a_1}{p}(\sum_{i=1}^p X_i-p\overline{X})=\frac{a_1}{p} \times \bold{O} \\ = & 0\end{aligned} yi1====p1i=1∑pyi1=p1i=1∑pa1(Xi−X)pa1i=1∑p(Xi−X)=pa1(i=1∑pXi−i=1∑pX)pa1(i=1∑pXi−pX)=pa1×O0这里要记得 X ‾ = 1 p ∑ i = 1 p X i \displaystyle \overline{X}=\frac{1}{p}\sum_{i=1}^pX_i X=p1i=1∑pXi
此时还有个问题,
a
1
a_1
a1 虽然确定了方向,但是
a
1
a_1
a1 的模的大小未定,如果
∣
∣
a
1
∣
∣
||a_1||
∣∣a1∣∣ 越大,则投影越大,所以要对
∣
∣
a
1
∣
∣
||a_1||
∣∣a1∣∣ 进行限制,至此,我们的问题就变成了这样:
max
a
1
∑
a
1
T
s
.
t
.
a
1
a
1
T
=
∣
∣
a
1
∣
∣
2
=
1
\begin{aligned} &\max \quad a_1 \sum a_1^T \\ &s.t.\quad \quad a_1a_1^T=||a_1||^2=1 \end{aligned}
maxa1∑a1Ts.t.a1a1T=∣∣a1∣∣2=1我们可以用拉格朗日乘数法求解:
目
标
函
数
为
L
(
a
1
,
α
)
=
a
1
∑
a
1
T
−
α
(
a
1
a
1
T
−
1
)
∂
L
∂
a
1
=
2
a
1
∑
−
2
α
a
1
=
0
⟹
∑
T
a
1
T
=
∑
a
1
T
=
α
a
1
T
所
以
α
是
∑
的
特
征
值
,
对
应
特
征
向
量
为
a
1
T
⟹
a
1
∑
a
1
T
=
a
1
α
a
1
T
=
α
由
于
要
最
大
化
方
差
,
所
以
α
应
该
是
∑
的
最
大
的
特
征
值
,
记
为
λ
1
,
则
a
1
T
就
是
对
应
于
λ
1
的
单
位
特
征
向
量
\begin{aligned} 目标函数为\quad&\displaystyle L(a_1, \alpha) = a_1 \sum a_1^T-\alpha(a_1 a_1^T-1) \\\\ &\frac{\partial L}{\partial a_1}=2a_1\sum-2\alpha a_1=0\implies {\sum}^Ta_1^T={\sum}a_1^T=\alpha a_1^T \\ \\所以\quad& \alpha是\sum的特征值,对应特征向量为a_1^T\\ \\ \implies&a_1\sum a_1^T = a_1\alpha a_1^T=\alpha \\ \\由于要&最大化方差,所以\alpha应该是\sum的最大的特征值,记为\lambda_1 , 则a_1^T就是对应于\lambda_1的单位特征向量\end{aligned}
目标函数为所以⟹由于要L(a1,α)=a1∑a1T−α(a1a1T−1)∂a1∂L=2a1∑−2αa1=0⟹∑Ta1T=∑a1T=αa1Tα是∑的特征值,对应特征向量为a1Ta1∑a1T=a1αa1T=α最大化方差,所以α应该是∑的最大的特征值,记为λ1,则a1T就是对应于λ1的单位特征向量
拉格朗日乘数法计算过程
设 a 1 = ( a 11 , a 12 , ⋯ , a 1 n ) a_1=(a_{11},a_{12},\cdots,a_{1n}) a1=(a11,a12,⋯,a1n), a 1 T = ( a 11 a 12 ⋮ a 1 n ) a_1^T=\begin{pmatrix}a_{11}\\ a_{12} \\ \vdots \\ a_{1n}\end{pmatrix} a1T=⎝⎜⎜⎜⎛a11a12⋮a1n⎠⎟⎟⎟⎞, ∑ = ( σ 11 σ 12 ⋯ σ 1 n σ 21 σ 22 ⋯ σ 2 n ⋮ ⋮ ⋮ σ n 1 σ n 2 ⋯ σ n n ) \displaystyle\sum=\begin{pmatrix} \sigma_{11}&\sigma_{12}&\cdots&\sigma_{1n}\\\sigma_{21}&\sigma_{22}&\cdots&\sigma_{2n}\\\vdots&\vdots&&\vdots\\\sigma_{n1}&\sigma_{n2}&\cdots&\sigma_{nn}\end{pmatrix} ∑=⎝⎜⎜⎜⎛σ11σ21⋮σn1σ12σ22⋮σn2⋯⋯⋯σ1nσ2n⋮σnn⎠⎟⎟⎟⎞,则:
{ a 1 ∑ = ( ∑ i = 1 n a 1 i σ i 1 , ∑ i = 1 n a 2 i σ i 2 , ⋯ , ∑ i = 1 n a n i σ i n ) a 1 ∑ a 1 T = a 11 ∑ i = 1 n a 1 i σ i 1 + a 12 ∑ i = 1 n a 2 i σ i 2 + ⋯ + a 1 n ∑ i = 1 n a n i σ i n ⟹ ∂ ( a 1 ∑ a 1 T ) ∂ a 1 k = ∑ i = 1 n a 1 i σ k i + ∑ i = 1 n a 1 i σ i k , 又 ∑ = ∑ T ⟹ σ i j = σ j i ⟹ ∂ ( a 1 ∑ a 1 T ) ∂ a 1 k = 2 ∑ i = 1 n a 1 i σ i k = 2 a 1 ( σ 1 k σ 2 k ⋮ σ n k ) ( k = 1 ∼ n ) ⟹ ∂ ( a 1 ∑ a 1 T ) ∂ a 1 = ( ∂ ( a 1 ∑ a 1 T ) ∂ a 11 , ∂ ( a 1 ∑ a 1 T ) ∂ a 12 , ⋯ , ∂ ( a 1 ∑ a 1 T ) ∂ a 1 n ) = 2 a 1 ∑ a 1 a 1 T = ∑ i = 1 n a 1 i 2 ⟹ ∂ a 1 a 1 T ∂ a 1 k = 2 a 1 k ( k = 1 ∼ n ) ⟹ ∂ a 1 a 1 T ∂ a 1 = 2 a 1 \begin{aligned}&\begin{cases}a_1 \displaystyle\sum =(\displaystyle\sum_{i=1}^{n}a_{1i}\sigma_{i1},\displaystyle\sum_{i=1}^{n}a_{2i}\sigma_{i2},\cdots,\displaystyle\sum_{i=1}^{n}a_{ni}\sigma_{in})\\ a_1\displaystyle\sum a_1^T=a_{11}\displaystyle\sum_{i=1}^{n}a_{1i}\sigma_{i1}+a_{12}\sum_{i=1}^{n}a_{2i}\sigma_{i2}+\cdots+a_{1n}\sum_{i=1}^{n}a_{ni}\sigma_{in}\end{cases}\\ \implies& \displaystyle \frac{\partial (a_1\displaystyle \sum a_1^T)}{\partial a_{1k}}=\sum_{i=1}^{n}a_{1i}\sigma_{ki}+\sum_{i=1}^{n}a_{1i}\sigma_{ik},又\sum={\sum}^T\implies\sigma_{ij}=\sigma{ji}\\ \implies& \frac{\partial (a_1\displaystyle \sum a_1^T)}{\partial a_{1k}}=2\sum_{i=1}^{n}a_{1i}\sigma_{ik}=2a_1\begin{pmatrix}\sigma_{1k}\\ \sigma_{2k}\\ \vdots \\ \sigma_{nk}\end{pmatrix}\quad(k=1 \sim n)\\ \implies & \frac{\partial (a_1\displaystyle \sum a_1^T)}{\partial a_{1}} =\bigg(\frac{\partial (a_1\displaystyle \sum a_1^T)}{\partial a_{11}},\frac{\partial (a_1\displaystyle \sum a_1^T)}{\partial a_{12}},\cdots,\frac{\partial (a_1\displaystyle \sum a_1^T)}{\partial a_{1n}}\bigg)=2a_1\sum \\ \\ &a_1 a_1^T=\sum_{i=1}^{n}a_{1i}^2\\ \implies & \frac{\partial a_1 a_1^T}{\partial a_{1k}}= 2a_{1k}\quad(k=1\sim n) \\ \implies & \frac{\partial a_1 a_1^T}{\partial a_{1}}=2a_1\end{aligned} ⟹⟹⟹⟹⟹⎩⎪⎪⎪⎨⎪⎪⎪⎧a1∑=(i=1∑na1iσi1,i=1∑na2iσi2,⋯,i=1∑naniσin)a1∑a1T=a11i=1∑na1iσi1+a12i=1∑na2iσi2+⋯+a1ni=1∑naniσin∂a1k∂(a1∑a1T)=i=1∑na1iσki+i=1∑na1iσik,又∑=∑T⟹σij=σji∂a1k∂(a1∑a1T)=2i=1∑na1iσik=2a1⎝⎜⎜⎜⎛σ1kσ2k⋮σnk⎠⎟⎟⎟⎞(k=1∼n)∂a1∂(a1∑a1T)=(∂a11∂(a1∑a1T),∂a12∂(a1∑a1T),⋯,∂a1n∂(a1∑a1T))=2a1∑a1a1T=i=1∑na1i2∂a1k∂a1a1T=2a1k(k=1∼n)∂a1∂a1a1T=2a1
下面再来看看如何寻找第二个维度的最大方差,此时要把 { y i 1 } \{y_{i1}\} {yi1}换成 { y i 2 } \{y_{i2}\} {yi2},和上面推导类似,就简化写了:
这里注意,限制条件多了一个正交条件,因为已经确定了最大方差的一个方向,现在要找一个除了它以外最大方差的方向,故要保证正交,找第三、第四等方向类似,都要与已经找到的方向正交.
m a x ∑ i = 1 p ( y i 2 − y i 2 ‾ ) 2 = a 2 ∑ a 2 T s . t . a 2 a 2 T = ∣ ∣ a 2 ∣ ∣ 2 = 1 a 1 a 2 T = a 2 a 1 T = 0 目 标 函 数 L ( a 2 , α , β ) = a 2 ∑ a 2 T − α ( a 2 a 2 T − 1 ) − β a 1 a 2 T ∂ L ∂ a 2 = 2 a 2 ∑ − 2 α a 2 − β a 1 = 0 ⟹ 2 a 2 ∑ a 1 T − 2 α a 2 a 1 T − β a 1 a 1 T = 0 ⟹ 2 a 2 λ 1 a 1 T − β = 0 ⟹ β = 0 ⟹ ∂ L ∂ a 2 = 2 a 2 ∑ − 2 α a 2 = 0 ⟹ ∑ a 2 T = α a 2 T 所 以 α 应 该 是 ∑ 的 除 λ 1 以 外 最 大 的 特 征 值 , 记 为 λ 2 , 则 a 2 T 就 是 对 应 于 λ 2 的 单 位 特 征 向 量 \begin{aligned} max\quad&\sum_{i=1}^{p}(y_{i2}-\displaystyle\overline{y_{i2}})^2=a_2 \sum a_2^T \\\\ s.t. \quad\displaystyle&a_2 a_2^T=||a_2||^2=1 \\ \\\displaystyle&a_1a_2^T=a_2a_1^T=0 \\ \\目标函数\quad&L(a_2,\alpha,\beta)=a_2\sum a_2^T-\alpha(a_2a_2^T-1)-\beta a_1 a_2^T \\\\ &\frac{\partial L}{\partial a_2}=2a_2\sum-2\alpha a_2-\beta a_1=0 \\ \\ \implies&2a_2\sum a_1^T-2\alpha a_2 a_1^T-\beta a_1 a_1^T=0 \\\\ \implies &2a_2\lambda_1a_1^T-\beta=0\\\\ \implies&\beta=0 \\\\ \implies&\frac{\partial L}{\partial a_2}=2a_2\sum-2\alpha a_2=0\\\\ \implies&\sum a_2^T=\alpha a_2^T \\ \\ 所以\alpha应该&是\sum的除\lambda_1以外最大的特征值,记为\lambda_2 ,则a_2^T就是对应于\lambda_2的单位特征向量 \end{aligned} maxs.t.目标函数⟹⟹⟹⟹⟹所以α应该i=1∑p(yi2−yi2)2=a2∑a2Ta2a2T=∣∣a2∣∣2=1a1a2T=a2a1T=0L(a2,α,β)=a2∑a2T−α(a2a2T−1)−βa1a2T∂a2∂L=2a2∑−2αa2−βa1=02a2∑a1T−2αa2a1T−βa1a1T=02a2λ1a1T−β=0β=0∂a2∂L=2a2∑−2αa2=0∑a2T=αa2T是∑的除λ1以外最大的特征值,记为λ2,则a2T就是对应于λ2的单位特征向量
PCA算法
- 求 ∑ = ∑ i = 1 p ( X i − X ‾ ) ( X i − X ‾ ) T \displaystyle\sum=\displaystyle\sum_{i=1}^{p}(X_i-\overline{X}) (X_i-\overline{X})^T ∑=i=1∑p(Xi−X)(Xi−X)T
- 求 ∑ \displaystyle\sum ∑的特征值 λ i \lambda_i λi 及其对应的单位特征向量 a i T a_i^T aiT ,其中 λ i − 1 ≥ λ i \lambda_{i-1}\ge\lambda_i λi−1≥λi
- 写出矩阵 A = ( a 1 a 2 ⋮ a m ) A=\begin{pmatrix}a_{1}\\a_{2}\\ \vdots\\a_{m}\end{pmatrix} A=⎝⎜⎜⎜⎛a1a2⋮am⎠⎟⎟⎟⎞
- 降维: Y i = A ( X i − X ‾ ) , i = 1 ∼ p Y_i=A(X_i-\overline{X}),\quad i=1\sim p Yi=A(Xi−X),i=1∼p
【注】
实际使用中,由于 X X X的每个维度数据的量纲可能不同,直接拿来用PCA可能会导致结果错误,故最好先Normalization,使均值为 0 0 0,方差为 1 1 1
如何选择 k k k 个主成分
第
k
k
k 个主成分
y
k
y_k
yk 的方差贡献率定义为
y
k
y_k
yk 的方差与所有方差之和的比,记作
η
k
\eta_k
ηk:
η
k
=
λ
k
∑
i
=
1
m
λ
i
\eta_k=\displaystyle\frac{\lambda_k}{\displaystyle\sum_{i=1}^{m}\lambda_i}
ηk=i=1∑mλiλk
k
k
k个主成分
y
1
,
y
2
,
⋯
,
y
k
y_1,y_2,\cdots,y_k
y1,y2,⋯,yk的累计方差贡献率定义为
k
k
k 个方差之和与所有方差之和的比:
∑
i
=
1
k
η
i
=
∑
i
=
1
k
λ
i
∑
i
=
1
m
λ
i
\sum_{i=1}^{k}\eta_i=\frac{\displaystyle\sum_{i=1}^{k}\lambda_i}{\displaystyle\sum_{i=1}^{m}\lambda_i}
i=1∑kηi=i=1∑mλii=1∑kλi
通常取
k
k
k 使得累计方差贡献率达到规定的百分比以上,例如达到
90
%
90\%
90% 以上。

















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









