







前言
DeepLab-V3+ 是一个很好的 segmentation 架构。→ arXiv 论文链接在此
可以用 Inception-ResNet V2 作为脊柱 backbone,搭建一个 DeepLab-V3+ 模型,在 Cityscapes 数据集上做 segmentation 任务,效果如下。
- 在训练集上的效果:
说明:每一行 3 张图片,其中左图为数据集的原图,最右图为模型预测的结果,即 segmentation mask,中间的图片是把原图和 mask 重叠的结果,以方便检查 segmentation mask 的准确度。


- 在验证集上的效果:


- 在测试集上的效果:

下面用 Keras/TensorFlow 2.8 来搭建这个 DeepLab-V3+ 模型。
1. DeepLab-V3+ 的主体架构。
DeepLab-V3+ 的结构图如下。
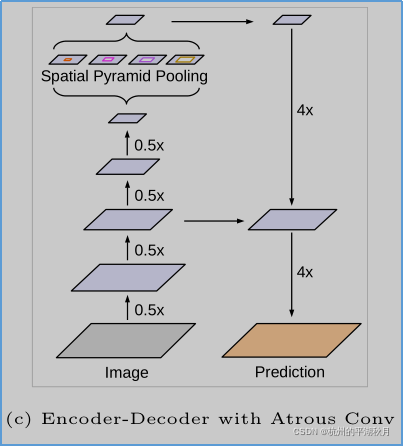
DeepLab-V3+ 的主体架构有 3 个关键点:
- 模型分为前后 2 个部分。前半部分用于对图片进行理解(即上面结构图的左半部分),后半部分则用于给图片各个区域进行分类(上面结构图的右半部分),生成 mask。前半部分也叫做编码器 encoder,而后半部分也叫做解码器 decoder。
- 编码器顶部,使用了 ASPP 模块(Atrous Spatial Pyramid Pooling)。ASPP 的主要作用是,借助 atrous convolution(也叫 dilation convolution)使得模型有 5 种不同大小的感受域(3 个空洞卷积,1 个普通卷积,再加 1 个平均池化),将小的特征信息和大的特征信息进行混合,从而获得更好的场景信息 semantic information。 ASPP 的另一个名字是 DSPP(Dilated Spatial Pyramid Pooling)。
- 在解码器 decoder 部分,从 encoder 获得了一个底层特征 low-level features,作为输入注入到解码器中(即上面结构图中,左右两部分中间位置,进行横向连接的那个箭头)。这个底层特征的作用,是使得模型预测结果 mask 中,各个类别的轮廓更加准确。(BTW,顺着这个思路,我对 DeepLab-V3+ 模型做了一点修改,增加了一个底层特征注入到解码器中,以使得各个类别的轮廓更清晰,似乎有一点作用。用 keras.utils.plot_model 查看模型结构时,可以看到我增加的这个连接。)
2. 使用 Cityscapes 数据集。
- Cityscapes 数据集的内容很多。在这个模型中,只需要用到数据集的 2 个文件夹, “leftImg8bit_foggy ” 和 “gtFine”。
- 需要制作 colormap 文件。colormap 中保存的是颜色映射关系,即 Cityscapes 的 34 个类别和 34 种颜色的一一对应关系。我已经根据 Cityscapes 官方的颜色对应关系制作好了这个 colormap_cityscapes.json 文件,可以直接使用。如果是应用到其它数据集,需要自行制作其它数据集的 colormap 文件。
3. 环境配置和使用方法。
为了方便训练模型和调试,需要使用 Jupyter Lab,在 cityscapes_deeplab_v3plus.ipynb 文件中进行模型训练。
而其它函数,则集中放在 Python 文件 deeplab_v3_plus.py 中。
TensorFlow: 2.8
使用时,只需要在 Jupyter Lab 中打开 cityscapes_deeplab_v3plus.ipynb 文件操作即可。下面为 Jupyter Lab 中训练模型部分的图示。
如果显存不够大,可以设置如下 2 项:
- 设置图片大小。在 deeplab_v3_plus.py 中,设置 MODEL_IMAGE_SIZE(实际设置 model_image_height 即可,会自动计算 MODEL_IMAGE_SIZE)。MODEL_IMAGE_SIZE 是输入给模型的图片大小。
- 设置批次大小。在 cityscapes_deeplab_v3plus.ipynb 文件中,设置 BATCH_SIZE 。
如果是单张 RTX 3090 显卡,可以使用模型默认的设置,MODEL_IMAGE_SIZE = 512 x 1024 , BATCH_SIZE = 8。如果显存不够,可以降低图片大小为 320 x 640,或降低批次大小。
4. 参考代码。
我的模型参考了 Keras 官方代码。→ 官方代码链接在此 官方代码使用的是一个不同的 backbone 和一个不同的数据集,有兴趣的同学可以学习一下。
需要注意的是,官方代码中有一点不足,即在对标签 mask 进行图片缩放操作时,使用了 bilinear 插值方法。但实际上,应该使用最邻近点插值方法(在 TensorFlow 中为 tf.image.ResizeMethod.NEAREST_NEIGHBOR。这个问题属于吴恩达在深度学习课程中所说的 subtlety,即容易被忽视的要点)。经验证后发现,使用官方代码的插值方法,会使得准确度下降 2%。
举例说明为什么只能用最邻近点插值方法。假设 mask 图片中有一个桌子,桌子上面放着一个杯子。桌子的类别为 0,而杯子的类别为 2。当使用 bilinear 或 bicubic 插值方法时,可能会插入一个值 1,但是类别 1 有可能是代表了一辆火车。这时 mask 中就会出现一个错误的情形,即一辆火车被夹在一个桌子和一个杯子中间,从而导致模型学习到一些错误的信息。反之,如果使用最邻近点插值方法,就不会出现这种问题。
5. github 下载链接。
下面是创建 DeepLab-V3+ 模型的主函数,其它完整数据,可以在 github 下载。→ 下载链接在此
def inceptionresnetv2_deeplabv3plus(model_image_size, num_classes,
rate_dropout=0.1):
"""使用 Inception-ResNet V2 作为 backbone,创建一个 DeepLab-V3+ 模型。
Arguments:
model_image_size: 一个整数型元祖,表示输入给模型的图片大小,格式为
(height, width, depth)。注意对于 Inception-ResNet V2,要求输入图片的像
素值必须转换到 [-1, 1] 之间。
为了便于说明数组形状,这里假设模型输入图片的大小为 (512, 1024, 3)。
num_classes: 一个整数,是模型中需要区分类别的数量。
rate_dropout: 一个浮点数,范围是 [0, 1],表示 SpatialDropout2D 层的比例。
Returns:
model: 一个以 Inception-ResNet V2 为脊柱的 DeepLab-V3+ 模型。
"""
# 新建模型之前,先用 clear_session 把状态清零。
keras.backend.clear_session()
model_input = keras.Input(shape=(*model_image_size, 3))
conv_base = keras.applications.InceptionResNetV2(
include_top=False,
input_tensor=model_input)
# low_level_feature_backbone 形状为 (None, 124, 252, 192)。
low_level_feature_backbone = conv_base.get_layer(
'activation_4').output
# 因为需要 low_level_feature_backbone的特征图为 128, 256, 所以要用 2次
# Conv2DTranspose。
for _ in range(2):
low_level_feature_backbone = convolution_block(
low_level_feature_backbone)
low_level_feature_backbone = keras.layers.Conv2DTranspose(
filters=256, kernel_size=3,
kernel_initializer=keras.initializers.HeNormal())(
low_level_feature_backbone)
# low_level_feature_backbone 形状为 (None, 128, 256, 256)。
low_level_feature_backbone = convolution_block(
low_level_feature_backbone, num_filters=256, kernel_size=1)
if rate_dropout != 0:
low_level_feature_backbone = keras.layers.SpatialDropout2D(
rate=rate_dropout)(low_level_feature_backbone)
# encoder_backbone 形状为 (None, 30, 62, 1088)。
encoder_backbone = conv_base.get_layer('block17_10_ac').output
# 在特征图被放大之前,都算作 encoder 部分,因为这部分内容都是在图片进行理解,所以 DSPP
# 也算作 encoder 部分。下面进行 DSPP 操作。
# encoder_backbone 形状为 (None, 30, 62, 256)。
encoder_backbone = dilated_spatial_pyramid_pooling(encoder_backbone)
# 下面进入解码器 decoder 部分,开始放大特征图。
# encoder_backbone 形状为 (None, 32, 64, 256)。
decoder_backbone = keras.layers.Conv2DTranspose(
256, kernel_size=3, kernel_initializer=keras.initializers.HeNormal())(
encoder_backbone)
# encoder_backbone 形状为 (None, 128, 256, 256)。
decoder_backbone = keras.layers.UpSampling2D(
size=(4, 4), interpolation='bilinear')(decoder_backbone)
if rate_dropout != 0:
decoder_backbone = keras.layers.SpatialDropout2D(rate=rate_dropout)(
decoder_backbone)
# x 形状为 (None, 128, 256, 512)。
x = keras.layers.Concatenate()(
[decoder_backbone, low_level_feature_backbone])
# 下面进行2次卷积,将前面 2 个合并的分支信息进行处理,特征通道数量将变为 256。
for _ in range(2):
x = convolution_block(x)
if rate_dropout != 0:
x = keras.layers.SpatialDropout2D(rate=rate_dropout)(x)
# x 形状为 (None, 512, 1024, 256)。
x = keras.layers.UpSampling2D(size=(4, 4), interpolation='bilinear')(x)
if rate_dropout != 0:
x = keras.layers.SpatialDropout2D(rate=rate_dropout)(x)
# 尝试增加一个分支 down_sampling_1,特征图大小和输入图片大小一样。目的是使得在预测结果
# mask 中,物体的轮廓更准确。
down_sampling_1 = model_input
down_sampling_1 = convolution_block(down_sampling_1, num_filters=8,
separableconv=False)
for _ in range(2):
down_sampling_1 = convolution_block(down_sampling_1, num_filters=8)
if rate_dropout != 0:
down_sampling_1 = keras.layers.SpatialDropout2D(rate=rate_dropout)(
down_sampling_1)
# x 形状为 (None, 512, 1024, 264)。
x = keras.layers.Concatenate()([down_sampling_1, x])
for _ in range(2):
x = convolution_block(x, num_filters=64)
# model_output 形状为 (None, 512, 1024, 34)。
model_output = keras.layers.Conv2D(
num_classes, kernel_size=(1, 1), padding='same')(x)
model = keras.Model(inputs=model_input, outputs=model_output)
return model















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









