







一 概述
关系型数据库(Relation Data Base),建立在关系模型基础上,由多张相互链接的二维表组成的数据库。
特点:
- 使用表存储数据,格式统一,便于维护
- 使用SQL语言,标准统一,使用方便。
二 SQL
Mysql数据库中sql 语句不区分大小写,关键字建议使用大写。
2.1 Sql分类
2.1.1 数据定义语言DDL (Data Definition Language)
数据定义语言,用来定义数据库对象(表,字段)。
注:truncate 属于DDL语言,不会记录事务日志,无法回滚,大批量比Delete快(因为不用记录日志)。
- DDL查询
--查询所有数据库
show databases;
--查询当前数据库
select database();
--查询当前数据库所有表
show tables;
--查询表结构
desc 表名;
--查询指定表的建表语句
show create table 表名;
- 创建
--创建数据库
create database [if not exists] 数据库名称 [default charset 字符集] [collate 排序规则]
--创建表语句
create table 表名(
字段 字段类型
);
- 删除
--删除数据库
drop database [if exists] 数据库名称;
--删除表
drop table table_name;
- 使用
--使用数据库
use 数据库名称
2.1.2 数据操作语言DML (Data Manipulation Language)
对表中的数据进行增删改的操作。insert\update\delete 语句
2.1.3 数据控制语言DCL (Data Control Language)
数据库权限控制语言,控制用户权限以及创建数据库用户。
2.1.4 数据查询语言DQL(Data Query Language)
--数据库查询语言。
select * from table_name where 1 = 1 group by column_name having group_column_condition order by column_name desc;
--分页查询,为数据库方言。
limit 起始索引 ,条数;
--起始索引:页码索引(通过当前页数-1)*条数
--条数: 每一页展示的条数
执行顺序:from -> where -> select -> group by -> having -> order by -> limit
2.2 常见函数
2.2.1 字符串
- concat(s1,s2),拼接两个字符串。
- trim(str) 去掉头部尾部空格
- substring(str,start,len) 截取str字符串,start开始,len为截取长度。
2.2.2 数值
- round(x,y) 对x进行四舍五入,保留y位小数。
- rand() 取0-1随机小数。
- floor(x) x向下取整。
2.2.3 时间
- now() 当前日期和时间。
- curdate() 返回当前日期。
- curtime() 当前时间。
2.2.4 流程控制函数
--condition判断条件,execute_way 满足条件执行的代码,deault_way不满足时执行。
case when condition then execute_way else [default_way] end;
2.3 约束
非空约束、唯一约束、主键约束、默认约束、外键约束。
2.4 多表查询
2.4.1 内连接
- 隐式内连接:where后直接跟关联条件
- 显示内连接:通过inner join [表] on [关联条件]关联
2.4.2 外连接
左外连接(left join [表] on [条件])、右外连接。将主表全部查出,匹配关联表符合条件的行。
2.4.3 子查询
- 标量子查询 :子查询中返回的值为单个值。
- 列子查询:返回多行单列值。
- 行子查询: 返回一行多列的值。
- 表子查询:返回多行多列的值
三 事务*
3.1 简介
事务 是一组操作集合,是一个不可分割的工作单位,事务把所有操作作为一个整体一起提交或撤销操作,即要么同时成功,要么同时失败。
3.1.1 四大特性
- 原子性
事务不可分割,要么全部成功,要么全部失败。 - 隔离性
保证事务不被外部并发操作影响的独立环境下运行。 - 一致性
事务完成时,必须所有数据都保持一致状态。 - 持久性
事务提交或回滚,对数据库中的数据改变是永久的。
3.1.2 查案事务是否自动提交
--查看事务是否自动提交
select @@autocommit;
--设置事务是否自动提交0否
set @@autocommit 0;
3.2 并发事务问题*
事务的隔离级别不同,造成不同的事务问题。
3.2.1 事务隔离级别
- 脏读 : A事务中可以读取到B事务中未提交的更新操作
- 不可重复读: A事务中两次执行同一条查询sql 结果不同,由于B事务提交更新操作提交导致。
- 幻读:A事务中查询一条数据不存在,但是插入操作时报错已经存在,再次查询还是不存在。B事务中已经插入相同数据,但是A不可见
(1)读未提交(Read uncommited)
会出现脏读、不可重复读、幻读。该事务状态下。
(2)读已提交(Read conmmited)
会出现不可重复读、幻读
(3) 可重复读(Repeatable Read - Mysql默认)
会出现幻读。。
- 后续描述在该事务机制下也可以解决 不可重复读问题操作(MVCC)
- 后续描述在该事务机制下也可以解决幻读操作(间隙锁、临键锁)
(4) 串行化 (Serializable)
解决以上问题,但消耗性能。
(5)查询当前事务隔离界别
随着事务的隔离级别约安全,性能消耗越高。
--查询事务隔离级别
select @@Transaction_isolation;
--设置事务隔离级别
set [session会话级别|global系统级] transaction isolation level[Read uncommited | Read conmmited | Repeatable Read | Serializable]
四 存储引擎*
4.1 Mysql结构体系
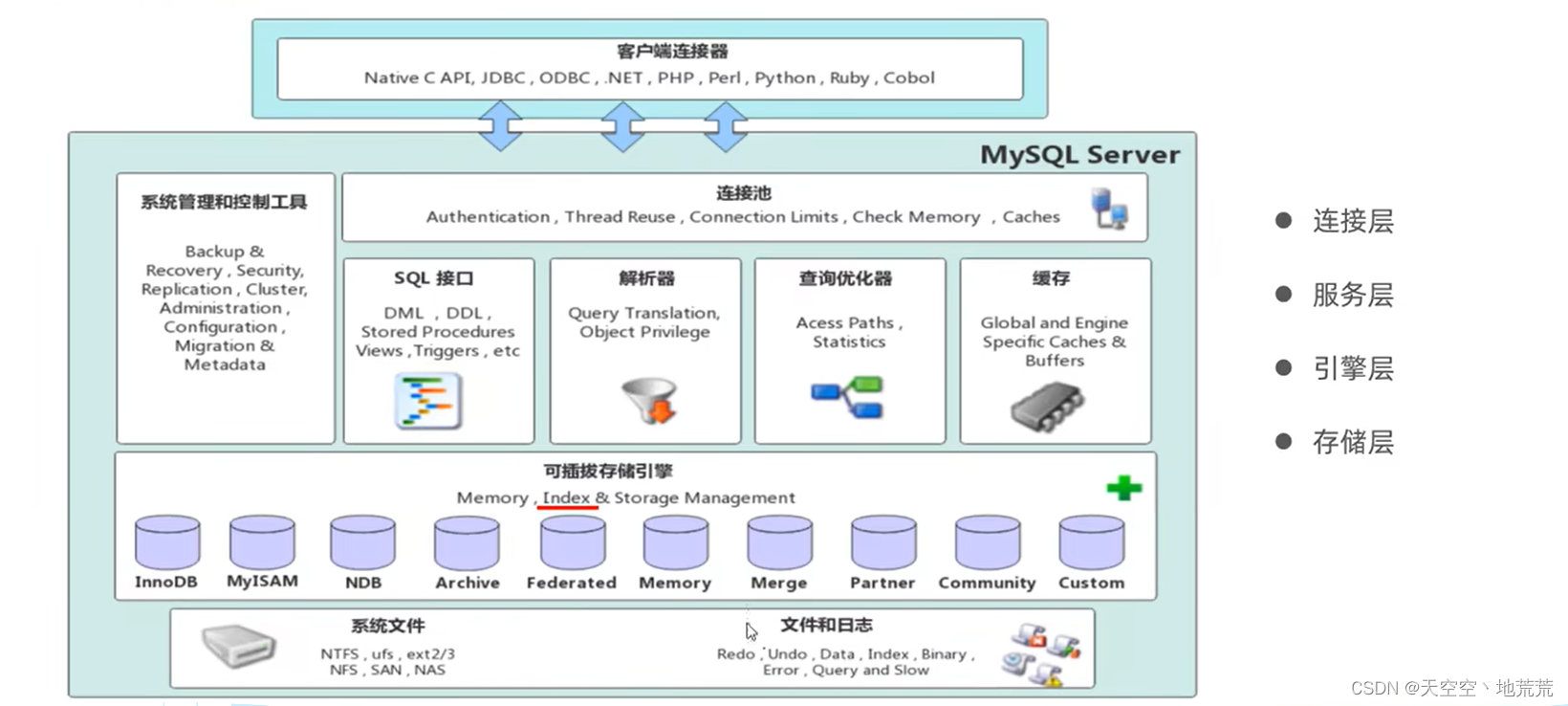
- 连接层
最上层是一些客户端和链接服务,主要链接处理、授权认证、及相关安全方案。 - 服务层
Sql分析与优化,缓存查询、内置函数执行,可跨引擎操作。 - 引擎层
负责Mysql数据存储和获取,服务层通过API和存储引擎进行通讯。 - 存储层
将数据存储在文件系统之上,并与存储引擎交互。硬盘。
4.2 存储引擎
存储引擎是基于表的,一个数据库中多个表,可以采用不同的存储引擎。默认innoDB。
--创建表时指定存储引擎
create table 表名{
字段 字段类型 ;
} engine = innodb comment "注释";
--查询当前数据库的引擎
show engines;
4.2.1 InnoDb
(1)特点
- InnoDB 是一种可靠和高性能的通用存储引擎,Mysql 5.5之后为Mysql默认存储引擎。
- 支持DML操作遵循ACID模型,支持事务。
- 行级锁,提高并发访问性能。
- 支持外键约束 forreign key。
(2)文件
xxx.idb:Innodb引擎每张表都会对应一个表空间文件,存储表结构(8.0之前存储结构 frm,sdi),数据和索引。
--通过以下配置,判断是否一张表一个表空间文件,
show variables like 'innodb_file_per_table';
-- 可查询表结构
idb2sdi xxx.idb
(3)存储结构*
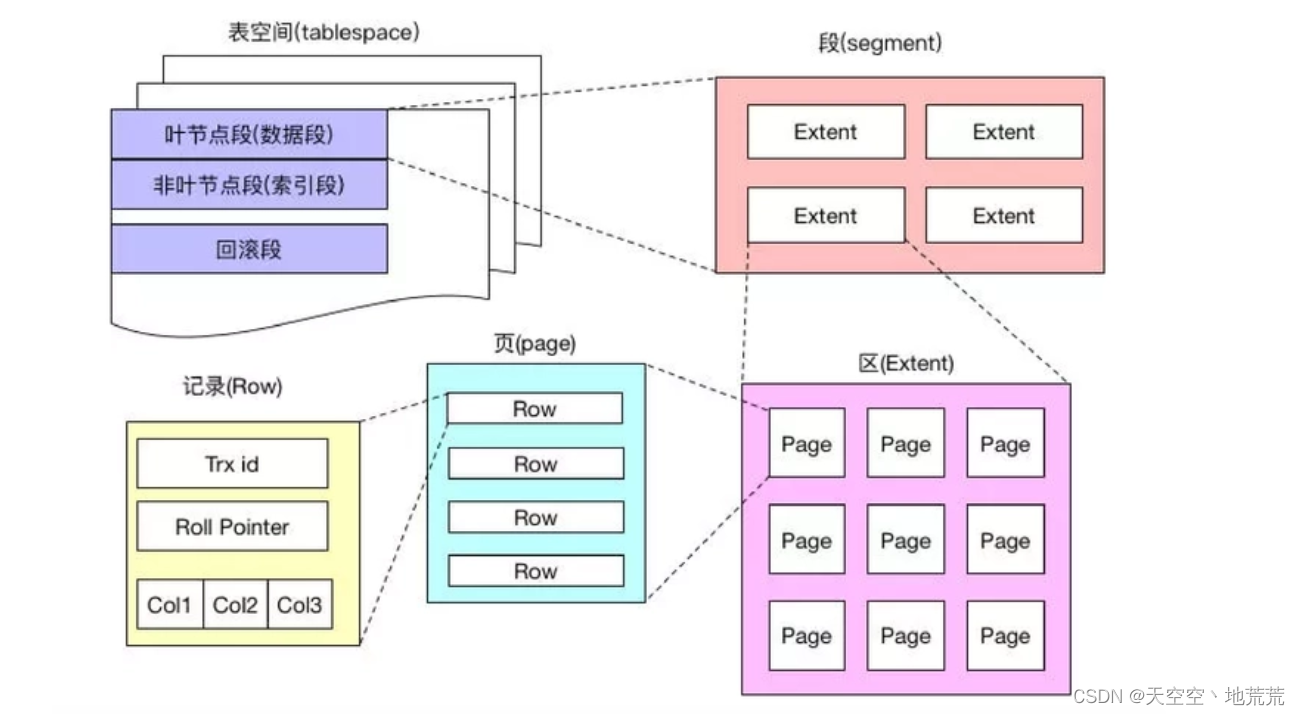
- Tablespace 表空间 存储多个段,如索引段、数据段、回滚段。一个Mysql实例可以对应多个表空间,用于存储记录、索引等数据。
- Segment 段,分为数据段、索引段、回滚段。InnoDB是索引组织表,数据段就是B+树的叶子节点,索引段为B+树的非叶子节点,段用来管理区。
- Extent 区,表空间的单元结构,每个区大小为1M,默认情况下Innodb存储引擎页大小为16K,即一个区中一共64个连续的页,Mysql申请空间以区为单位,为了保持连续性一次申请4-5个区。
- Page 页 ,页为存储结构的最小单元。大小固定16KB,所以一个区最多放入64个页。存储多个行。
- Row 行,存放trx_id(事务id ,undo_log |read_view时使用),roll pointer ,columns(行数据信息)。
4.2.3 MyISAM\MEMORY
(1) MyISAM
- 早期默认引擎。
- 不支持事务。
- 不支持行锁,支持表锁。
- 访问速度快。
- xxx.sdi(存储表结构信息),xxx.MYD(存储数据),xxx.MYI(存储索引信息)
(2)Memory
- 存储在内存中,不做持久化,运用于临时表。
- 支持hash索引。
- xxx.sdi(只存放表结构信息)
五 索引
索引是一种高效获取数据的数据结构(有序)。
优势:①提高查询效率,降低数据库IO成本。②通过索引对数据进行排序,降低数据排序成本,降低cpu的消耗。
劣势:①索引需要占用空间。②索引提高查询效率,同时也降低了更新表的速度(更新时需要维护索引)。
5.1 索引结构
5.1.1 B-Tree索引
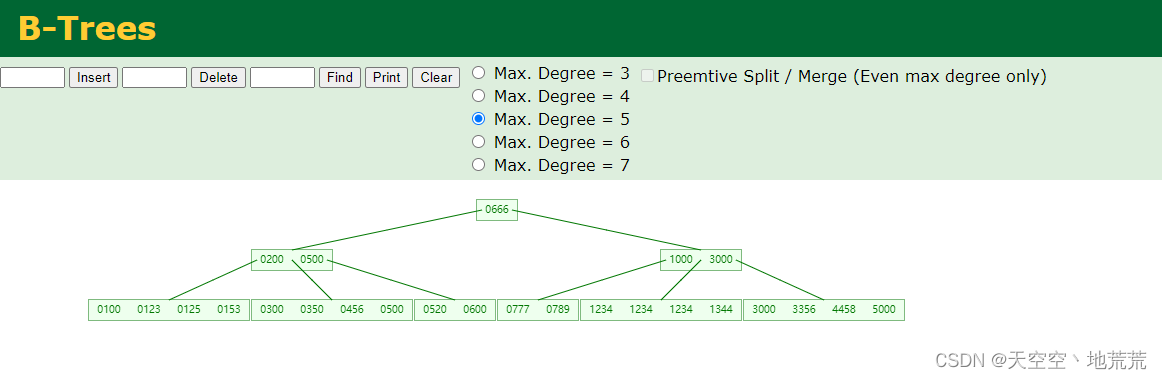
- 以一颗最大度(max-degree)数为n的B 树举例(每个节点最多存储n-1个索引值key ,指针有n)。
- 中间元素向上分裂。
- 自下而上。
- 每个节点都存储数据。
5.1.2 B+Tree索引
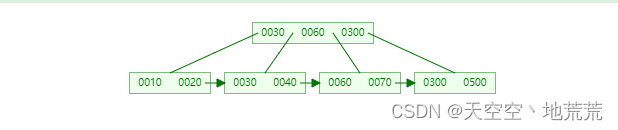
- 以一颗最大度(max-degree)数为n的B 树举例(每个节点最多存储n-1个key ,指针有n)。
- 中间元素向上列表,叶子节点形成链表。
- 自下而上。
- 叶子节点存储数据。
- 叶子节点为单向链表的结构(Mysql实现B+Tree索引增强为双向链表)。
5.1.3 Mysql为什么选择B+Tree*
(1)不采用二叉树的原因:
- 极限情况下,为链表结构,查询较慢。
- 树的查询效率取决于树的高度,二叉树大数量,层级较深。
- 以上两种情况 孕育除B树结构(多路平衡查找树)
(2)不采用Hash索引:
- B+Tree叶子节点存储数据,并且有双向指针,支持范围匹配与排序操作。
(3)不采用B树原因:
- B+Tree范围匹配以及排序更优
- 对于B树不论是叶子节点还是非叶子节点,都会保存数据,这样导致页中能够存储的键值减少,指针也会同样减少。相反B+Tree等只存储索引key,可以在一页中存储更多的key,可以使树的高度更矮,查询效率更好。(一个树节点必须占一页,一个节点可以存放多个索引key。一页大小固定16KB)
例题
题目假设*:
一个数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节空间,主键为bigInt占用8个字节。高度为2的B+Tree能存多少数据量:
--其中一页大小固定16KB,即大小为16*1024字节
--主键索引值key大小为8字节,指向子节点指针长度为6字节,假设最大能存n个索引值key则计算如下
n*8 + (n+1)*6 = 16*1024 算出一页索引值key数量为1170左右。
--两层时,第二层为叶子节点,第一层最多有n+1个指针,对应n+1个页,每一页16行的话,则为(n+1)*16
对应每个叶子节点能存16行,则总数据量为: 1171 * 16 = 18736
5.2 索引分类
主键索引、唯一索引、常规索引、全文索引。
5.2.1 索引存储形式
(1)聚集索引(Clustered Index)
- 将数据存储与索引放在一块,索引结构的叶子节点保存行数据。必须有且只有一个。默认主键索引
- 如果不存在主键,则将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果以上都不存在,则自动生成一个rowid作为隐藏的聚集索引。
(2) 非聚集索引(二级索引)
数据与索引分开存储。非聚集索引,在查询中存在索引之外的字段时,需要通过聚集索引进行需要回表。
5.3 索引总结
5.3.1 索引命令
--创建索引
create[unique | fullTest] index index_name on table_name(index_col_name,...);
--查看索引
show index from table_name;
--删除索引
drop index index_name on table_name;
- 添加索引是否会锁表
alter table 添加索引会锁表,使用了concurrent insert 的方式。
create index 不会锁表。Mysql 8.0 后增加Invisible Indexes、Instant DDL技术
5.3.2 索引设计原则
- 数据量较大
- 常用查询条件,排序条件,分组条件字段索引简历
- 尽量不重复的字段。
- 长字符串,建议使用前缀索引
- 尽量使用联合索引,减少单列索引。
- 控制索引数量,会影响增删改效率。
- 如果索引列不存储null值,创建表时用非空约束 not null。
六 SQL性能优化
6.1 索引优化
--查看执行频次,可查看是查询多还是更新多
show [session | global] status like 'Com_______';
(1)慢查询日志
慢查询记录了所有执行时间超过指定参数(long_query_time,单位:秒。默认10秒)的所有sql语句日志。
默认关闭,需要在Mysql的配置文件中(/etc/my.cnf)中配置:
# 开启Mysql慢查询日志记录开关
slow_query_log=1
# 设置慢日志的时间为2秒,sql语句执行超过2秒,则视为慢查询,记录慢查询日志。
long_query_time=2
# 日志生成在/var/lib/mysql/localhost_slow.log中。
(2) 执行计划Explain*
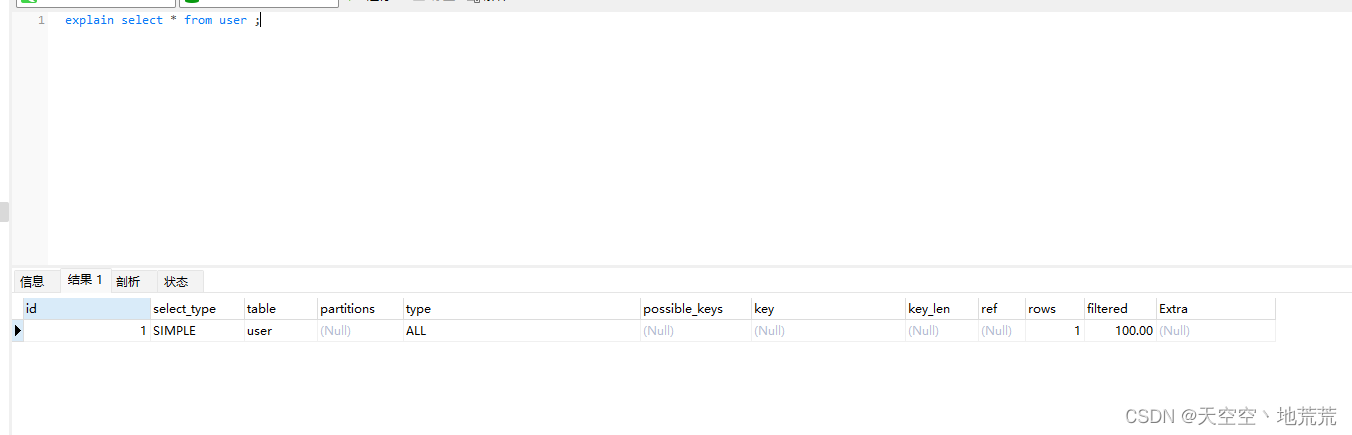
--在任意select 语句前加上explain 可以查看索引使用情况
explain select * from talbe_name ;
* ID 代表着表的执行顺序,值越大越先执行(子查询ID不同),相同时从上到下执行(关联查询,id相同)。
* select_type 标识select类型。
①常见simple(不存在表关联、子查询)
②primary(主查询)
③subquerty(子查询)
* possible_keys 可能用到的索引
* key 实际用到的索引
* key_len 使用到的索引的字节数
* rows 执行查询的行数,预估值
* filtered 查询扫描的行数,与实际返回的数据量比,越大越好。
* type 性能由好到差的链接类型 NULL(不访问表时出现)\ system\const\eq_ref\ref\range\index\all
①NULL(不访问表时出现)
②system(访问系统表时出现)
③const(查询唯一索引、主键索引时)
④ref(非唯一性索引,非聚集索引时)
⑤range(范围查找)
⑥index(使用了索引、全量索引树扫描)
(3)最左前缀法则,联合索引,从左向右检索。如果跳过中间某一个,则索引会部分失效。
(4)范围查询,如(<,>)联合联合索引中,如果使用范围查询,则右边的列会索引失效。可以使用>= 或<= 。
(5)索引不能计算,索引会失效。
(6)字符串不加引号,则索引会失效。
(7)模糊匹配,尾部%匹配索引生效;头部%号,则索引失效。
(8)Or链接条件。or前后的条件必须都符合索引才会走索引,否则索引失效。
(9)数据分布影响(数据量预估)
- 当扫描数量大于一半时,并且效率大于走索引时,则索引会失效。
- IS null \ is not null 会根据数据分布情况判定是否走索引,但是走索引的情况通常二者都是相反的。
6.2 Insert优化
(1)大批量Insert 时,手动提交事务可提高效率。
(2) 使用load指令进行插入,配置一定规则,并打开开关。
--客户端链接服务端时,加上参数--local-infile(允许访问客户段本地文件)。
mysql -local-infile -uroot -p
6.3 主键优化
6.3.1 数据组织方式
Innodb存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式称为索引组织表。
(1)页分裂(消耗性能,增加磁盘IO)
主键的乱序插入,如果对应页存储已满,会导致页分裂,50%移至新页。
(2)页合并
- 删除数据时,会判断删除数据页的相邻上下的页,判断是否能够合并,如果可以合并则进行合并。
- MERGE_THRESHOLD合并阈值,可手动设置,默认50%。
(3)主键设计原则
- 尽量较低索引主键长度,因为主键索引会被其他索引引用。
- 插入时,尽量选择顺序插入,选择使用auto_increment自增主键。
- 尽量不要使用UUID做主键或者其他自然主键,每次插入都是乱序的,会导致页分裂。
- 尽量避免修改主键。
6.4 update 优化
更新数据时根据索引更新时,为行锁。如果where条件为非索引,为普通条件时则会升级为表锁。
七 锁*
7.1 概述
锁是计算机协调多个进程或线程并发访问某一资源的机制。锁保证了数据库并发访问下的一致性、有效性。
7.1.1 分类
- 全局锁:锁定数据库中所有表,锁数据库实例。
- 表级锁: 每次操作锁住整张表
- 行级锁: 锁住操作涉及的所有行。
7.1.2 全局锁
全局锁针对于整个数据库实例,加锁后整个实例处于只读状态,后续DML,DDL将被阻塞。
主库加锁时,业务都会停摆。从库进行同步时,备份期间不能同步主库的二进制日志。
- 全库逻辑备份时,对所有表进行锁定,保证数据的完整性。
--全局锁枷锁
flush tables with read lock;
--解锁
unlock tables;
--备份数据库到本地文件,需要枷锁
mysqldump -h IP -uroot -pxxxx - db_name > local/dir/xxx.sql
--备份数据库到本地文件,--single-transaction不加锁完成一致性数据备份。
mysqldump --single-transaction -h IP -uroot -pxxxx - db_name > local/dir/xxx.sql
7.1.3 表级锁
每次操作锁住整张表,锁冲突概率最高。
-- 加锁
lock tables 表名... read/write
-- 释放锁
unlock tables / 客户断开链接
(1) 表共享读锁(read lock)
- 添加读锁时,当前客户端、其他客户端都无法对表进行写操作。
- 当前客户端、其他客户端 都可以进行读操作
(2) 表独占写锁(write lock)
- 当前客户端 可读、可写。
- 其他客户端 不可读、不可写。
(3) 意向锁
存在行级锁之后,在进行表锁时,需要去检查每一行数据是否加锁。意向锁解决该问题。在加行级锁时,会自动伴随生成一个意向锁,再次加入表锁时,会直接判断意向锁类型(IS\IX,与表锁类型相同的话直接加入),是否可以直接加入,不在寻找行级锁。
- 意向共享锁(IS):由语句select … lock in share mode添加。
- 意向排他锁(IX):由insert 、update、delete、 select … for update 添加。
--查询意向锁情况。
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema_.data_lock;
(4)元数据锁(Meta Data Lock,MDL)
MDL加锁过程是系统自动控制,无需显示使用。当表中存在未提交的事务,则不能修改表结构。为了规避DML与DDL冲突,保证读写正确性。
对表数据进行增删改查时,加MDL读锁(共享),当对表结构操作时加写锁(排他)。
7.1.4 行级锁
每次锁住对应操作的行数据,发生锁冲突概率小,应用于innodb引擎中。
InnoDB的数据是基于索引组织的,行锁是通过索引上的索引项加锁来实现的,不是对记录加锁(锁索引值 ,即key)。
(1)行锁
锁定单个行记录的锁,防止其他事务对此行进行更新操作。RC\RR隔离级别下支持。
- 共享锁(S),与其他共享锁(即读锁)之间是兼容的,阻塞组织其他事务相同数据集的排他锁。
--共享锁(S)
select ... lock in share mode;
- 排他锁(X),允许当前获取锁的事务更新数据,阻塞组织其他事务相同数据集的共享锁和排他锁。
insert\update\delete\select… for update都是排他锁
(2)间隙锁、临键锁*
- 间隙锁:
 索引叶子节点索引值key之间的间隙,不包含记录,保证索引记录的间隙不变,防止insert,可以防止幻读。RR隔离级别下使用。 - 临键锁:
 行锁和间隙锁的组合,同时锁住数据,在RR隔离级别下支持。 - InnoDB在Repeatable Read事务隔离级别运行,使用next-key锁进行搜索和索引扫描,防止幻读。
①索引上的等职查询(唯一索引),给不存在的记录加锁,优化为间隙锁
②索引上的等值查询(普通索引),向后遍历最后一个值不满足查询需求时,next-key lock 退化为间隙锁。
③ 索引上的方位查询(唯一索引),会访问到不满足条件的第一个值为止,除了当前值,其余范围值都需要加临建锁。
④间隙锁是可以共存在同一间隙上的。
八 InnoDB架构
MySql5.5后,默认使用InnoDB,擅长处理事务,具有崩溃回复的特性。
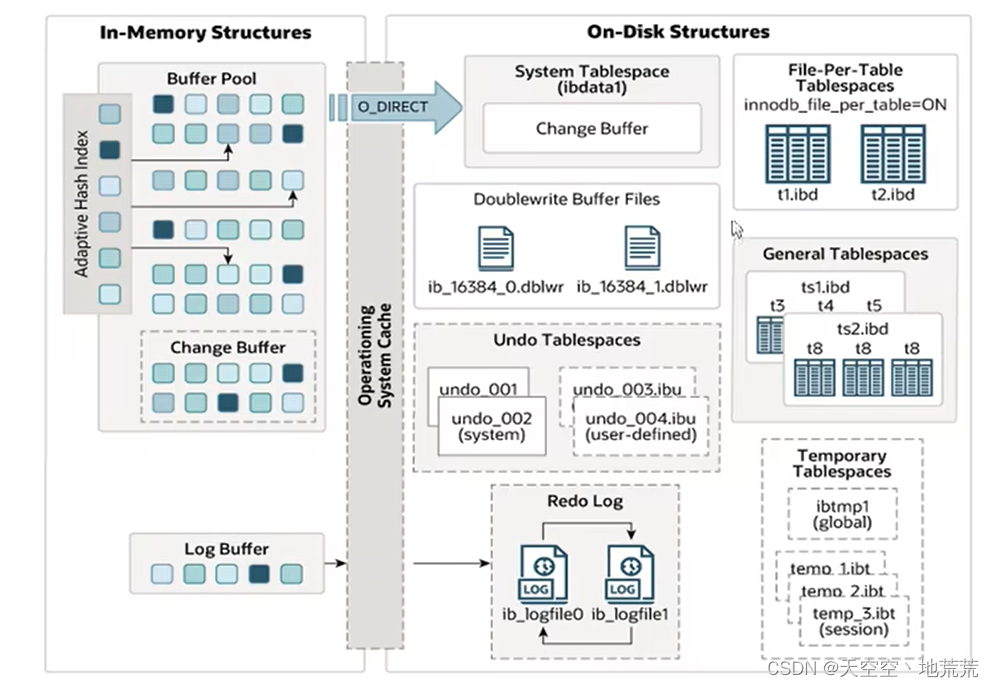
8.1 内存架构
专业的数据库服务器,缓冲区赋值会很大80%,提高效率
8.1.1 Buffer Pool
缓冲池是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(如果缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而较少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三类:
- free page:空闲的page,未被使用
- clean page: 被使用page,数据没有被修改过。
- dirty page: 脏页,被使用page,数据被修改过,页中数据与磁盘数据不一致。
8.1.2 Change Buffer(Mysqk8.0之后,5.0后为insert buffer)
更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在Change Buffer中,在未来数据被读取时,再将数据合并到恢复Buffer Pool,再将合并后的数据刷新到磁盘。
- Change Buffer的作用
原因:与聚集索引不同,二级索引通常是非唯一的,并且是无须的,可能存在乱序插入、删除,页分裂、也合并导致磁盘的大量IO。
Change Buffer,可以在缓冲池中进行合并处理,减少磁盘IO。
8.1.3 Adaptive Hash Index
自适应hash索引,用于对Buffer Pool数据查询,InnoDB会监控对表上各索引页的查询。
开关: show variable like ‘%hash_index%’
8.1.4 Log Buffer*
日志缓冲区,用于保存要写入磁盘中的log日志数据(redo log,undo log),默认大小16MB,日志缓冲区的日志定期会刷新到磁盘中。如果需要更新、插入、删除多行事务,增加日志缓冲区的大小可以节省磁盘IO。
--show variable like ''
--缓冲区的大小
show variable like ‘innodb_log_buffer_size’
--日志刷新到磁盘的时机 0-每秒写入磁盘一次;1-代表每次事务提交时,提交磁盘;2-每次事务提交,提交到磁盘并每秒写入一次。
show variable like ‘innodb_flush_log_at_trx_commit’
8.2 磁盘结构
8.2.1 System TableSpace*
系统表空间 是Change Buffer更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在Mysql5.x版本后,还包含InnoDB数据字典,undolog等)
--系统表空间参数,ibdata1
show variable like 'innodb_data_file_path'
8.2.2 File-Per-Table Tablespaces *
文件 (独立表空间),每个表的文件表空间包含单个InnoDB表的数据和索引,并存储在文件系统的单个数据文件中。默认开启。
--是否一个表一个单独的文件idb ,默认开启。
show variable like 'innodb_file_per_table'
8.2.3 General Tablespaces *
通用表空间,需要通过Create TableSpace语法进行创建,在创建表时,可以指定表空间
--创建表空间
Create TableSpace 名称 ADD default 'file_name关联文件' engine = engine_name引擎;
--创建表时指定表空间
create table table_name ( 字段 字段类型 )engine = innodb tablespace 表空间名称
8.2.4 Undo Tablespaces
撤销表空间,Mysql实例在初始化时会自动创建两个undo_001,undo_002表空间文件(初始大小16M),用于存储undo log日志。
8.2.5 Temporary Tablespaces
临时表空间,InnoDB使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
8.2.6 Doublewrite Buffer Files
双写缓冲区,InnoDB引擎将数据页,从Buffer pool刷新到磁盘前,先将数据页写入双鞋缓冲区,便于系统异常时恢复数据。
两个xxx.dblwr文件
8.2.7 Redo LOG
重做日志,用于实现事务的持久性,该日志文件由两部分组成;重做日志缓冲(redo log buffer) 以及重做日志文件(redo log),前者是在内存中,后者在磁盘中,当事务提交之后会把所有修改信息都存在日志中,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
两个ib_logfile0\ib_logfile1文件。
8.3 后台线程
8.3.1 Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
8.3.2 IO Thread
在InnoDB 存储引擎中大量使用AIO处理IO请求,这样可以极大的提高数据库性能,而IO Thread主要负责这些IO请求的回调
- Read Thread 默认线程个数4 ,负责读操作。
- Write thread 默认线程个数4 ,负责写操作。
- Log Thread 默认线程个数1,负责将日志缓冲区刷新到磁盘
- Insert Buffer thread 默认线程个数1,负责将写缓冲区刷新到磁盘。
--查看innodb引擎状态
show engine innodb status;
8.3.3 Purge Thread
主要用于回收事务已经提交的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
8.3.4 Page Cleaner Thread
协助Master Thread 刷新脏页到磁盘的线程,它可以减轻Mater Thread 的压力,减少阻塞。
九 事务原理
9.1 持久性原理 (redo log)
重做日志,记录事务提交时数据页的事务修改,保证事务的持久性。
记录日志文件由两部分组成,重做日志(redo log buffer -> log buffer中) 以及重做日志文件(redo log file),前者内存中,后者磁盘中。当事务提交之后会把所有的修改信息都存到改日志文件中,用于在刷新脏页到磁盘发生错误时,进行数据恢复使用。
个人理解举例: 一个事务中,数据可能存在多次修改,并未刷新到磁盘文件,在Buffer Pool内存中只有最后一次的修改的当前值,但是redo log buffer 中存在修改记录值,并且采用append 顺序追加的方式记录,在commit之后,redo log buffer 刷新到redo log file 中,后续如果脏页数据刷新到磁盘失败,可以直接从redo log中获取。
9.2 原子性原理 (undo log)
回滚日志,用于记录数据修改前的信息,作用包含:提供回滚和MVCC(多版本并发控制,RR隔离级别时,联合readView 进行使用,解决不可重复读问题)
undo log 和redo log 记录屋里日志不一样,他是逻辑日志。可以认为delete 一条记录时,undo log 会记录一条对应的insert 记录,反之亦然,当update 一条数据时,它记录一条对应相反的update。当执行rollback 时,就可以从undo log中的逻辑记录恢复数据。
- undo log 销毁:undo log在事务执行时产生,事务提交时,并不会立即删除,因为这些日志可能还用于MVCC。
- Undo log :undo log 采用段的方式进行管理和记录,存放在前面介绍的roll segment回滚段中,内部包含1024个undo log segment。
9.3 隔离性(原理)
9.3.1 锁(间隙锁、临键锁)解决幻读问题。
RR事务隔离级别下,通过间隙锁、临键锁可以解决幻读问题。
个人理解举例:A事务中,通过索引条件查询一个不存在的值,则此时,会找到大于该索引值的一个索引几点,并锁住该节点以及该节点的前一个间隙。这样保证B事务在插入,与A事务查询索引值相同值时,无法直接插入。避免出现幻读的情况
注:RC级别下,只提供了间隙锁,可解决插入幻读,无法避免修改幻读。
9.3.2 MVCC(解决不可重复读问题)
(1)当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取记录进行加锁。对于我们日常操作,如:select… lock in share mode(共享锁),sekect … for update (排他锁),都是一种当前读锁。
个人理解举例:在RR隔离级别下,如果在A事务第一查询 a1数据之后,B事务修改并提交了a1数据,A事务再次查询,查询结果与第一次查询结果相同(已经实现可重复读),为快照读;如果采用select … lock in share mode进行查询,则查询到的时 B事务修改过的数据,为当前表中存放的数据。
(2)快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
- Read Commited :每次select ,都生成一个快照读。(每次创建 readview)
- Repeatable Read : 开启事务后第一个select 才是快照读的地方(只创建 一次readview)。
- Serializable : 快照读会退化为当前读。
(3)原理(MVCC如何实现非阻塞可重复读)
全程为 Multi-Version Concurrency Control 多版本并发控制。指一个数据的多个版本,使的读写操作没有冲突,快照读为Mysql实现MVCC提供了一个非阻塞读功能。
MVCC的具体实现,还需要依赖与数据库记录中的三个隐式字段( db_trx_id,db_roll_ptr,db_row_id)、undo log日志、read view。
-
三个隐式字段
① db_trx_id: 事务id,最近修改事务ID,记录插入这条记录或最后一次修改该事务的事务ID。
② db_roll_ptr: 回滚指针,指向上一个版本,用于配合undo log,指向上一个版本拿到修改前的数据。
③db_row_id: 隐藏主键,如果表结构 没有指定主键,将会生成该隐藏字段。
注:隐藏字段可通过ibd2sdi xxx.ibd对应表空间文件 查看。 -
undo log版本链
回滚日志,在insert、update、delete的时候产生,便于数据回滚的日志。
insert 时候,产生undo log 日志只在回滚的时候需要,会立即删除。
update、delete产生undo log日志,可能在MVCC中被需要,不会立即删除。 -
readview(以下源码仅保留部分)
class ReadView {
public:
ReadView();
~ReadView();
/**
1. 如果 row 的 trx_id ( trx_id<min_id ),表示这个版本是已提交的事务生成的,这个数据是可见的;
2. 如果 row 的 trx_id ( trx_id>max_id ),表示这个版本是由将来启动的事务生成的,是不可见的
3. 若row 的 trx_id 就是当前自己的事务 ( trx_id==creator_trx_id),是可见的;
4. 如果 row 的 trx_id (min_id <=trx_id<= max_id),那就包括两种情况
a. 若 row 的 trx_id 在活动事务数组(m_ids)中,表示这个版本是由还没提交的事务生成的,不可见(若 row 的 trx_id 就是当前自
己的事务是可见的);
b. 若 row 的 trx_id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
*/
bool changes_visible(trx_id_t id, const table_name_t &name) const
MY_ATTRIBUTE((warn_unused_result)) {
ut_ad(id > 0);
if (id < m_up_limit_id || id == m_creator_trx_id) {
return (true);
}
check_trx_id_sanity(id, name);
if (id >= m_low_limit_id) {
return (false);
} else if (m_ids.empty()) {
return (true);
}
const ids_t::value_type *p = m_ids.data();
return (!std::binary_search(p, p + m_ids.size(), id));
}
/**根据事务ID,判断事务是否可见 -api */
bool sees(trx_id_t id) const { return (id < m_up_limit_id); }
#ifdef UNIV_DEBUG
/**
@return the view low limit number */
trx_id_t view_low_limit_no() const { return (m_view_low_limit_no); }
/**
@param rhs view to compare with
@return truen if this view is less than or equal rhs */
bool le(const ReadView *rhs) const {
return (m_low_limit_no <= rhs->m_low_limit_no);
}
private:
// Disable copying
ReadView(const ReadView &);
ReadView &operator=(const ReadView &);
private:
/** T左边边界(下限) */
trx_id_t m_low_limit_id;
/** 右边边界(上限)*/
trx_id_t m_up_limit_id;
/** 当前执行Select 的事务ID,注:RR、RC级别存在差异。 */
trx_id_t m_creator_trx_id;
/** 活动事务的集合 */
ids_t m_ids;
/** 标识undo log是否可以回收。配合Purge Thread进行回收使用 。
记录未提交的活动线程中最小的线程,小于则可进行回收删除。*/
trx_id_t m_low_limit_no;
。。。。待续















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









