







机器学习的定义
在了解机器学习的定义之前,我们要了解什么是学习。学习是指人通过观察(比如文字、声音、图像等等),经过大脑的内化,最后学到有用的技能(如图一)。类似的,机器学习是指电脑通过对数据的观察,经过电脑的一番处理,最后学到有用的技能(如图二)。【技能(skill):指的是提升某些性能的措施(improve some performance measure),比如英语说得更好了】
图一:学习的过程

图二:机器学习的过程

使用机器学习的原因
让机器自动去构建复杂的系统比人工构建要简单的多(A alternative route to build complicated systems)
机器学习的应用
| data | skill | |
|---|---|---|
| Food | Twitter data(words + location) | 判断某个餐馆的卫生状况 |
| Clothing | sales figures + client survey | 给顾客一些穿衣建议 |
| House | characteristics of buildings and their energy load | 预测其他建筑的能源消耗 |
| Transportation | some traffic sign images and meanings | 准确辨别交通标识 |
| Education | students’ records on quizzes | 判断学生在下次测试题中能否答对 |
| Recommender system | how many users have rates some movies | 预测某个用户对某部电影的评分 |
机器学习的详细过程
图三:机器学习的组成
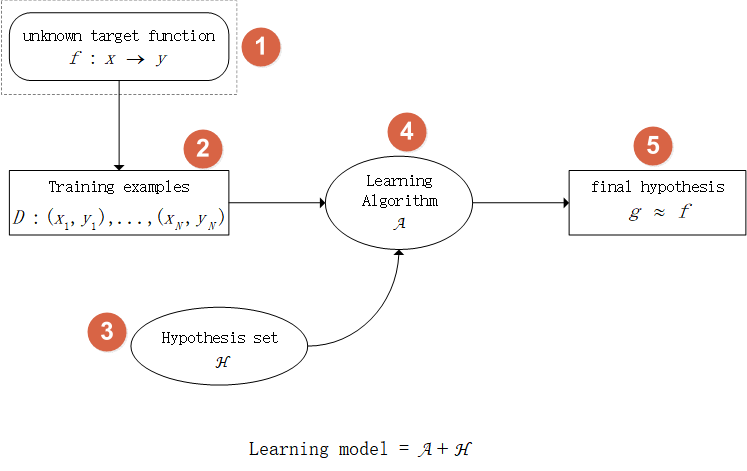
如图三所示,整个机器学习的过程主要分为5个部分:
第一部分:**目标函数。**就是我们想要得到的函数f,函数f刚好能将输入x转化为输出y(但是函数f我们并不知道)。
第二部分:**数据。**通过f所产生的数据,该数据也是我们训练的样本。
第三部分:**假说集。**假说集有很多候选函数,算法A从候选函数中选出一个最好的函数作为函数g。
第四部分:**算法。**通过该算法可以得到函数g,使得函数g与目标函数f越接近越好。
第五部分:**学习得到的函数g。**函数g与f越接近越好。
模型:Learning model = A + H
机器学习的过程:
利用数据,通过计算,从假说集中选取某个函数作为函数g,使得g与目标函数f越接近越好(use data to compute hypothesis g that approximates target f)
机器学习和其他领域的关系
-
机器学习(ML)与数据挖掘(DL)
数据挖掘是指利用数据找到一些有趣的东西(use data to find property that is interesting)。如果这个有趣的东西和机器学习中假说函数g是一样的,那么ML=DL。如果有趣的东西与假说函数g相关,DL可以帮助ML。ML和DL很难区分。 -
机器学习(ML)与人工智能(AL)
人工智能是指计算机能做出一些有聪明表现的东西(compute something that shows intelligent behavior)。机器学习中使函数g接近f就是一种很聪明的表现,从这个角度看,机器学习是实现人工智能的一种方法。 -
机器学习(ML)与统计(Statistics)
统计是指使用数据做一些我们不知道的推论(use data to make inference about unknown process)。机器学习中函数g是统计出来的结果,函数f是我们不知道的推论,因此,我们可以把statistics看做是实现ML的一种工具。















 3421
3421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









