







努力是为了不平庸~
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰
目录
第1关:“大胃王”比赛数据柱形图绘制——绘制柱形图的基本步骤
第2关:美国国家教育统计中心数据——分别按特征和聚类结果着色
第1关:对全球未成年人生育率数据实现地理数据可视化——对数据进行处理
第2关:对全球未成年人生育率数据实现地理数据可视化——创建Geo对象
第3关:对全球未成年人生育率数据实现地理数据可视化——在地图上展现坐标点
时间趋势可视化-柱形图
第1关:“大胃王”比赛数据柱形图绘制——绘制柱形图的基本步骤
任务描述
本关任务:根据实训提供的“大胃王”比赛数据绘制柱形图,熟悉柱形图绘制的基本步骤。
相关知识
为了完成本关任务,你需要掌握:
- 观察和处理数据;
- 绘制柱形图的基本步骤。
观察和处理数据
先导入
matplotlib和pandas,用pandas中的read_csv()方法读取 csv 格式文件。
import pandas as pd #导入pandas,用于生成满足绘图要求的数据格式from matplotlib import pyplot as plt #导入matplotlib,用于绘制柱形图from matplotlib.backends.backend_pdf import PdfPages #用于将图片保存成pdfhot_dog = pd.read_csv(r"matplotlib_bar/csv/hot-dog-contest-winners.csv") #返回值为二维标记数据结构DataFramehot_dog.head() #返回前五行数据让我们先看看数据文件的前5行内容:
Year Winner Dogs eaten Country New record 1980 Paul Siederman & Joe Baldini 9.1 United States 0 1981 Thomas DeBerry 9.1 United States 0 1982 Steven Abrams 11.0 United States 0 1983 Luis Llamas 19.5 Mexico 0 1984 Birgit Felden 9.5 Germany 0 这个数据展示的是自1980年开始,每年吃热狗大赛的冠军姓名,冠军吃掉热狗的数量,冠军的国籍,以及是否打破纪录(0表示没有破纪录,1表示破纪录)。
绘制柱形图
首先简单介绍一下绘制柱形图的 bar 函数:
matplotlib.pyplot.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)[source]参数:
- x:x 坐标,数据类型
int,float- height:柱形高度,数据类型
int,float- width:柱形宽度,默认
0.8,范围0 - 1之间- bottom:条形的起始位置,也是 y 轴的起始坐标
- align:条形的中心位置,
center,edge边缘- color:条形的颜色,
r,b,g,#123465等,默认b- edgecolor:边框的颜色,同上
- linewidth:边框的宽度,默认无,
int类型- tick_label:下标的标签,可以是元组类型的字符组合
- log:y 轴使用科学计算法表示,
bool类型- orientation:是竖直条还是水平条,竖直:
vertical,水平条:horizontal其中,最基本和最常用的是
x,height,width和color四个参数。 接下来让我们开始画一张不同年份冠军吃掉热狗数量的柱形图。
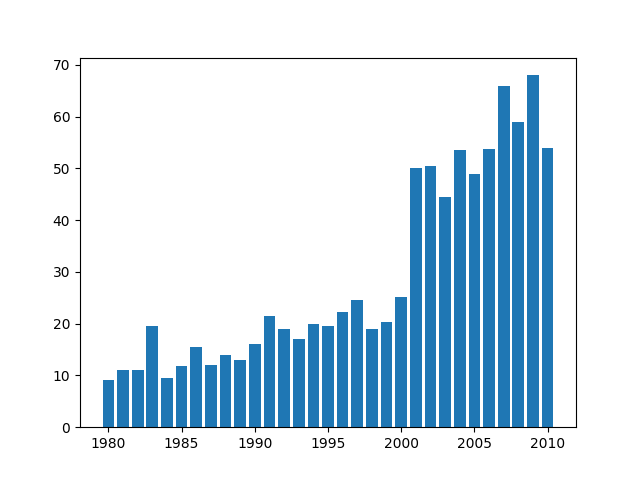
fig, ax = plt.subplots() #subplots返回画布和子图axis.bar(hot_dog["Year"],hot_dog["Dogs eaten"]) #绘制柱形图,第一个参数为x轴变量,第二个参数为y轴变量plt.show() #显示图像此时生成的图像如下图1所示:
图1 默认生成的柱形图
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,绘制一张不同年份冠军吃掉热狗数量的柱形图。
测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。
# -*- coding: utf-8 -*-
import pandas as pd
from matplotlib import pyplot as plt
hot_dog = pd.read_csv(r"matplotlib_bar/csv/hot-dog-contest-winners.csv")
def plot():
# ********* Begin *********#
fig, ax = plt.subplots() #subplots返回画布和子图
ax.bar(hot_dog["Year"],hot_dog["Dogs eaten"]) #绘制柱形图,第一个参数为x轴变量,第二个参数为y轴变量
plt.show() #显示图像
# ********* End *********#
plt.savefig('matplotlib_bar/studentfile/studentanswer/level_1/US.png')
plt.close()
第2关:“大胃王”比赛数据柱形图绘制——柱形图展示优化
任务描述
本关任务:根据实训提供的“大胃王”比赛数据绘制柱形图,并存为 PDF 或 png 文件。
相关知识
为了完成本关任务,你需要掌握:
- 对柱形图进行美化;
- 将柱形图保存为 PDF 文件或 png 文件。
对柱形图进行美化
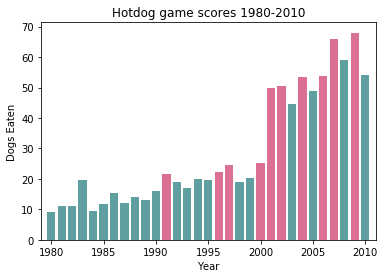
关卡1中的柱形图看起来平平无奇,打破记录的年份这一信息也没有体现,如果我们需要突出打破记录的年份呢?如何用不同的颜色进行表示?此外,系统默认的颜色饱和度很高,能选择更赏心悦目的颜色吗?当然可以!
突出破纪录的年份 在关卡1的基础上,这一步我们可以写一个函数,根据年份是否打破纪录,赋予不同的颜色,然后把各个年份应显示的颜色放入一个列表中。
def newRecordColor():"打破记录的年份显示为粉红色,其余年份为灰绿色"list=[]for i in hot_dog["New record"]:if i==1:list.append("#DB7093") #打破记录的年份显示为粉红色else:list.append("#5F9F9F") #其余年份显示为灰绿色return list别忘了将代码
axis.bar(hot_dog["Year"],hot_dog["Dogs eaten"])修改为
ax.bar(hot_dog["Year"],hot_dog["Dogs eaten"],color=newRecordColor()) #添加指定的颜色光秃秃的柱形图并不能让别人快速理解数据的含义,因此,我们应当为柱形图添加必要的文字说明:
ax.set_xlabel("Year") #设置x轴标签ax.set_ylabel("Dogs Eaten") #设置y轴标签ax.set_title("Hotdog game scores 1980-2010") #设置标题ax.set_xlim(1979,2011) #设置x轴数据限值此时生成的图像如下图1所示:
图1 突出打破纪录年份后的柱形图
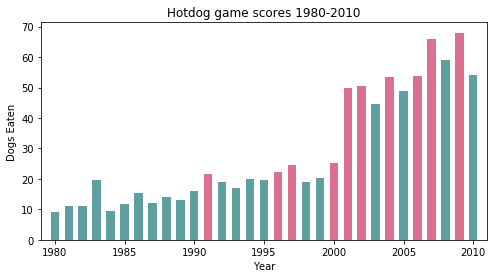
调整柱子的间距 图1看起来还不错,只是柱子之间太拥挤了,可以修改宽度,将代码:
ax.bar(hot_dog["Year"],hot_dog["Dogs eaten"],color=newRecordColor())修改为
ax.bar(hot_dog["Year"],hot_dog["Dogs eaten"],width=[0.6],color=newRecordColor()) #添加指定的宽度然后修改画布的尺寸,添加代码:
plt.rcParams['figure.figsize'] = (8.0, 4.0) #设置figure_size尺寸此时生成的图像如下图2如所示:
图2 美化后的柱形图
将柱形图保存为 PDF 文件或 png 文件
如果后续想要用 Illustrator 对图片进行美化,可以将图片保存为 PDF 格式,添加代码:
pdf =PdfPages('matplotlib_bar/studentfile/studentanswer/level_2/hotdog.pdf') #设置pdf保存的路径和文件名pdf.savefig(fig) #将画布内容保存为PDFplt.close() #关闭画布窗口pdf.close() #关闭PDF文件如果想将图片保存为 png 格式文件,则添加代码:
plt.savefig('matplotlib_bar/studentfile/studentanswer/level_2/hotdog.png') #保存png文件plt.close() #关闭画布窗口编程要求
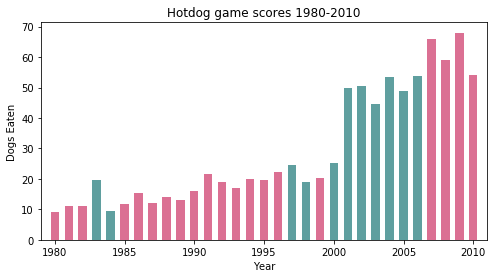
根据提示,在右侧编辑器 Begin-End 区间补充代码,绘制柱形图,并突出美国人获胜的年份。其中美国人获胜的年份显示为粉红色(
#DB7093),其余年份显示为灰绿色(#5F9F9F),画布大小等设置与上文保持一致。测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。 图片预期输出示例:
开始你的任务吧,祝你成功!
# -*- coding: utf-8 -*-
import pandas as pd
from matplotlib import pyplot as plt
hot_dog = pd.read_csv(r"matplotlib_bar/csv/hot-dog-contest-winners.csv")
def plot():
# ********* Begin *********#
fig, ax = plt.subplots() #subplots返回画布和子图
ax.bar(hot_dog["Year"],hot_dog["Dogs eaten"],width=[0.6],color=unitedStatesColor()) #添加指定的宽度
ax.set_xlabel("Year") #设置x轴标签
ax.set_ylabel("Dogs Eaten") #设置y轴标签
ax.set_title("Hotdog game scores 1980-2010") #设置标题
ax.set_xlim(1979,2011) #设置x轴数据限值
plt.rcParams['figure.figsize'] = (8.0, 4.0) #设置figure_size尺寸
# ********* End *********#
plt.savefig('matplotlib_bar/studentfile/studentanswer/level_2/US.png')
plt.close()
def unitedStatesColor():
# ********* Begin *********#
list=[]
for i in hot_dog["Country"]:
if i=='United States':
list.append("#DB7093") #打破记录的年份显示为粉红色
else:
list.append("#5F9F9F") #其余年份显示为灰绿色
return list
# ********* End *********#关系可视化-散点图
第1关:美国犯罪率数据散点图绘制——散点图的基本绘制步骤
任务描述
本关任务:根据实训提供的2005年美国各州的犯罪率绘制散点图,并存为 PDF 或 png 文件。
相关知识
为了完成本关任务,你需要掌握:
- 散点图绘制的基本步骤;
- 散点图展示优化。
散点图绘制的基本步骤
首先要载入待使用的包,还有数据。
import pandas as pd #用于生成满足绘图要求的数据格式from matplotlib import pyplot as plt #用于绘制散点图import statsmodels.api as sm #用于局部加权回归from matplotlib.backends.backend_pdf import PdfPages #用于将图片保存成pdfcrime=pd.read_csv(r"matplotlib_scatter/csv/crimeRatesByState2005.csv") #返回值为二维标记数据结构 DataFrame现在检查一下头几行数据,输入变量
crime,之后设置你希望看到的行数。
print(crime[0:3]) #查看crime的前三行数据以下是返回的前 3 行数据。
state murder forcible_rape robbery aggravated_assaul burglary larceny_theft motor_vehicle_theft population United States 5.6 31.7 140.7 291.1 726.7 2286.3 416.7 295753151 Alabama 8.2 34.3 141.4 247.8 953.8 2650 288.3 4545049 Alaska 4.8 81.1 80.9 465.1 622.5 2599.1 391 669488 第一列显示的是州名,其他列是各种类型犯罪的发生率。比如说,2005年美国全国的平均抢劫案发生率是每10万人口中发生140.7起。接下来我们为谋杀和入室盗窃两个数据创建默认的散点图,
pyplot中的subplots()方法返回的值的类型为元组,其中包含两个元素:第一个为一个画布,第二个是子图。简要介绍一下plot()方法:
plt.plot(x,y,format_string,**kwargs)
plt.plot()函数的本质就是根据点连接线。根据x(数组或者列表)和y(数组或者列表)组成点,然后连接成线,可以通过设置format_string选择画点还是画线。
- x, y :
x是可选的,如果没有x,将默认是从 0 到 n - 1,也就是y的索引- format_string :定义线条的颜色和样式的操作,如
o是圆圈,.是圆点,+是加号 ,*是星号,x是 x 形- **kwargs :可以用来指定很多内容,如
label指定线条的标签,linewidth指定线条的宽度等接下来可以添加代码绘制散点图:
fig,ax=plt.subplots() #subplots返回画布和子图ax.plot(crime2["murder"],crime2["burglary"],"o",color="#00AAFF") #绘制散点图ax.set_xlabel("crime murder", fontsize=12) #设置x轴标签ax.set_ylabel("crime burglary", fontsize=12) #设置y轴标签plt.show() #展示图像结果如下图1所示:
图1 默认生成的有关谋杀案和入室盗窃案的散点图
看上去这两个数据似乎是正相关的:谋杀率相对较高的州,其入室盗窃率也相对较高。但由于有一个点出现在很远的最右侧,所以这个关系并不是很容易发现。这个点(也就是离群值)导致水平轴必须延伸得很长。它代表的是华盛顿特区,该地区的谋杀率远高于其他地区,达到了35.4。谋杀率第二高的州是路易斯安那和马里兰,为9.9。
散点图展示优化
为了让图表更加清楚,我们可以拿掉华盛顿特区,同时除去全美平均值,聚焦于各个单独的州。添加代码如下:
crime2=crime[~crime['state'].isin(['District of Columbia','United States'])] #获取没有全美平均值和华盛顿特区的犯罪率数据ax.plot(crime2["murder"],crime2["burglary"],"o",color="#00AAFF") #绘制散点图其中
crime['state'].isin(['District of Columbia','United States']为选择state中值为'District of Columbia'和'United States'数据,~代表对选择后的数据取反,即取出对应的剩余数据。是不是很简单? 结果如下图2所示:
图2 过滤掉数据之后的散点图
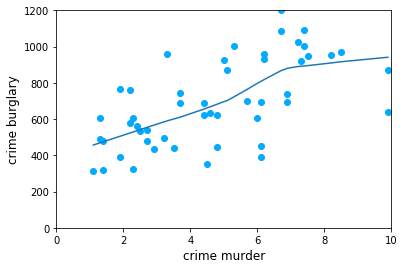
如果让轴从0开始可能会更好,所以在这里再进行一些设置。x 轴应该从0到10,y 轴应该从0到1200。这样做会把所有点的位置向右上移动,添加代码:
ax.set_xlim(0,10) #x轴范围从0到10ax.set_ylim(0,1200) #y轴范围从0到1200结果下图3所示:
图3 坐标轴从0开始的散点图
编程要求
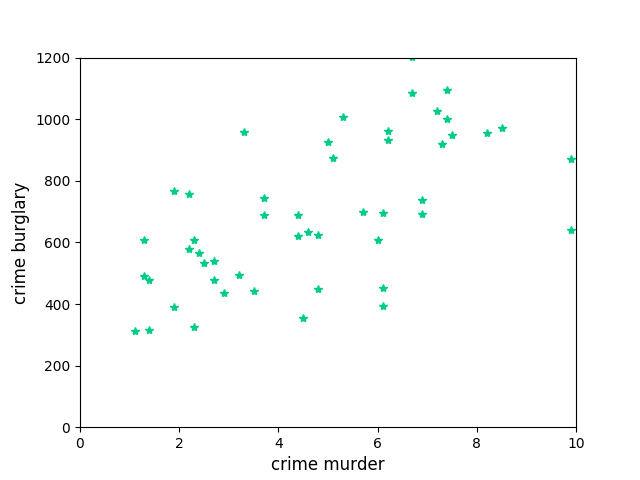
根据提示,在右侧编辑器 Begin - End 区间补充代码,过滤掉华盛顿特区和全美平均值数据,绘制散点图,其中 x 轴和 y 轴均从0开始,点用星号表示,颜色为
"#00CC88"。测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。 图片预期输出示例:
# -*- coding: utf-8 -*-
import pandas as pd #用于生成满足绘图要求的数据格式
from matplotlib import pyplot as plt #用于绘制散点图
# import statsmodels.api as sm #用于局部加权回归
crime=pd.read_csv(r"matplotlibScatter/csv/crimeRatesByState2005.csv") #返回值为二维标记数据结构 DataFrame
def plot():
# ********* Begin *********#
fig,ax=plt.subplots()
ax.set_xlabel("crime murder", fontsize=12)
ax.set_ylabel("crime burglary", fontsize=12)
crime2=crime[~crime['state'].isin(['District of Columbia','United States'])]
ax.set_xlim(0,10)
ax.set_ylim(0,1200)
ax.plot(crime2["murder"],crime2["burglary"],"*",color="#00CC88")
plt.show()
# ********* End *********#
plt.savefig('matplotlibScatter/studentanswer/level_1/crime.png') #保存为png格式
plt.close() #关闭画布窗口
第2关:美国犯罪率数据散点图绘制——局部加权回归
任务描述
本关任务:根据美国犯罪率数据,综合前一关知识,实现局部加权回归,绘制散点图并保存为 PDF 或 png 文件。
相关知识
为了完成本关任务,你需要掌握:
- 局部加权回归;
- 将散点图保存为 PDF 或 png 文件。
局部加权回归
如果你手中的数据太多,或者数据杂乱无章,可能就会很难辨认其中的趋势和模式。为了改善这一点,你可以估算出一条趋势线。 绘制一条线穿过尽可能多的数据节点,同时尽量减少各数据节点与拟合线之间的总距离。最直截了当的做法就是创建一条直线,这其中用到了你在中学时学过的基础斜截式方程:
y=mx+b
其中
m代表斜率,b代表截距。但如果你的趋势不是线性的该怎么办?用直线是不可能拟合带有波峰波谷的数据的。在这里我们可以用到 William Cleveland 和 Susan Devlin 创建的一种统计学方法,它被称作 LOWESS ,即局部加权散点平滑法( Locally Weighted Scatterplot Smoothing )。通过它你能用曲线来拟合数据。LOWESS 从最开头的数据开始对数据进行“切片”。针对每一个切片中的数据,它都会估算出一个低阶多项式。 LOWESS 会分析每一段数据,拟合众多微小的曲线,然后将它们合并形成一条曲线。现在让我们来用 LOWESS 处理数据,以帮助我们更加明确地观察入室盗窃率和谋杀率之间的关系。 先介绍一下 Python 中用于局部加权回归的方法:statsmodels.api.nonparametric.lowess该方法的参数包括:
- 因变量
y,待拟合的数据- 自变量
x,用于拟合的数据- 长度
frac,应该截取多长的作为局部处理,frac为原数据量的比例- 权值函数
w,使用什么样的权值函数w合适- 迭代次数
it,在进行一次局部回归后,是否需要迭代,迭代几次,再次做回归- 回归间隔
delta,是否真的每个点都需要算一次加权回归,能否隔delta距离算一次,中间没算的用插值替换即可 添加如下代码:结果如下图所示:
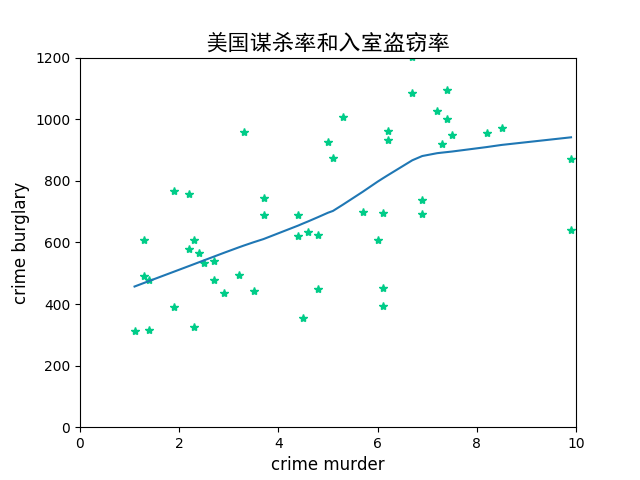
import statsmodels.api as smlowess = sm.nonparametric.lowess(crime2["burglary"], crime2["murder"]) #对数据采用默认值进行平滑处理,返回值为一个二维数组ax.plot(lowess[:, 0], lowess[:, 1]) #将二维数组绘制出来
图1 运用局部加权回归来估算关系
将散点图保存为PDF文件或png文件
如果后续想要用 Illustrator 对图片进行美化,可以将图片保存为 PDF 格式,可以添加代码:
pdf = PdfPages('matplotlibScatter/studentanswer/level_2/crime.pdf') #设置pdf保存的路径和文件名pdf.savefig(fig) #将画布内容保存为PDFplt.close() #关闭画布窗口pdf.close() #关闭PDF文件,避免触发 ValueError 等错误如果想将图片保存为 png 格式文件,则添加代码:
plt.savefig('matplotlibScatter/studentanswer/level_2/crime.png') #保存为png格式plt.close() #关闭画布窗口编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,采用美国犯罪率数据绘制散点图,过滤掉华盛顿特区和全美平均值数据,绘制散点图,其中 x 轴和 y 轴均从0开始,点用星号表示,颜色为
#00CC88,对数据进行局部加权回归,并为图片添加标题,注意标题为汉字黑体,字号大小为16,将图片保存为 png 格式。设置画布尺寸为8.0*4.0。测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。 图片预期输出示例:
# -*- coding: utf-8 -*-
import pandas as pd #用于生成满足绘图要求的数据格式
from matplotlib import pyplot as plt#用于绘制散点图
import statsmodels.api as sm #用于局部加权回归
crime=pd.read_csv(r"matplotlibScatter/csv/crimeRatesByState2005.csv") #返回值为二维标记数据结构 DataFrame
def plot():
# ********* Begin *********#
fig,ax=plt.subplots()
ax.set_xlabel("crime murder", fontsize=12)
ax.set_ylabel("crime burglary", fontsize=12)
ax.set_title("美国谋杀率和入室盗窃率",fontproperties="SimHei", fontsize=16)
crime2=crime[~crime['state'].isin(['District of Columbia','United States'])]
lowess = sm.nonparametric.lowess(crime2["burglary"], crime2["murder"])
ax.plot(lowess[:, 0], lowess[:, 1])
ax.set_xlim(0,10)
ax.set_ylim(0,1200)
ax.plot(crime2["murder"],crime2["burglary"],"*",color="#00CC88")
plt.show()
# ********* End *********#
plt.savefig('matplotlibScatter/studentanswer/level_2/crime.png') #保存为png格式
plt.close() #关闭画布窗口
差异可视化-多维量法(MDS)
第1关:美国国家教育统计中心数据——降维
任务描述
本关任务:对美国国家教育统计中心数据计算距离矩阵,然后通过多维量(MultiDimensional Scaling, MDS)实现降维,并绘制降维后的散点图。
相关知识
为了完成本关任务,你需要掌握:
- 多维量法MDS基本思想
- 计算距离矩阵;
- MDS降维;
- 绘制散点图。
1.多维量法MDS基本思想
假设你现在和另两个人在一个正方形的空房间内。你的任务是根据这两个人的身高安排他们站在合适的位置。他们的身高越接近,就应该彼此靠得越近,如果身高相差越远,彼此的距离就应该拉得更大。其中一人很矮,而另一人很高。这两人应该怎么站?他们应该站在相对的角落里,因为他们的身高是截然相反的。现在又进来了一个人,他的身高中等。根据我们的安排规则,这个新来的应该站在房间的中心,就在之前两个人的正中间。他与高个子的身高差距和矮个子是一样的,因此他和两个人的距离彼此相等。与此同时,高个子和矮个子之间依然保持最大距离。好,现在再引入另一个变量:体重。你知道所有这三个人的身高和体重。矮个子和中等个子的体重完全相等,而高个子的体重最轻。那么,根据身高和体重,你如何安排这三个人在房间中的位置?如果保持前两个人(矮个子和高个子)的对角位置,那么第三个人(中等个子)就应该向矮个子靠近,因为他们的体重是相同的。现在你理解我们的安排规则了吗?两个人越相似,他们彼此间的距离就应该越靠近。在这个简单的例子里,你只有3个人和2个变量,很容易人工计算出结果来。但如果有50个人,而且你需要根据5种标准来安排他们在房间里的位置,就会棘手得多。而这就是多维量法的用武之地。
本例中,每个州都有一行数据,其中包括美国全国平均值和哥伦比亚特区。每个州都有6个变量: 阅读、数学和写作科目的SAT成绩,参加SAT考试的毕业生百分比,高中毕业生就业率,以及辍学率。 和刚才那个房间的比喻类似,只不过这次不再是正方形的房间,而是一个图表;不再是一个个的人,而是一个个的州;不再是身高和体重,而是和教育相关的各项指标。我们的目的还是一样:在一个x-y坐标的图表里面放置各个州,使指标相似的州之间的距离比较接近。
2.计算距离矩阵
首先是导入相关模块,读取美国国家教育统计中心数据,添加代码如下:
import pandas as pd #用于生成满足绘图要求的数据格式from sklearn.manifold import MDS #用于 MDS 降维import matplotlib.pyplot as plt #用于绘制散点图from sklearn.cluster import KMeans #用于 Kmeans 聚类from scipy.spatial import distance #用于计算获取距离矩阵edu=pd.read_csv("MDS/csv/education.csv") #读取 csv 数据,返回值为二维标记数据结构 DataFrame首先观察一下数据,添加代码:
print(edu.shape) #返回数据的行列数print(edu.columns) #返回数据的列名以下是返回的数据:
(52, 7)Index(['state', 'reading', 'math', 'writing', 'percent_graduates_sat','pupil_staff_ratio', 'dropout_rate'], dtype='object')可以发现,数据共有52行,7列,除了美国的50个州的数据以外,还包括美国全国平均值和哥伦比亚特区的两条数据,每条数据除了地区名以外,还有6个变量,分别为:阅读、数学和写作科目的 SAT 成绩,参加 SAT 考试的毕业生百分比,高中毕业生就业率,以及辍学率。数据表格前六行内容如下表所示:
state reading math writing percent_
graduates_satpupil_
staff_ratiodropout_
rateUnited States 501 515 493 46 7.9 4.4 Alabama 557 552 549 7 6.7 2.3 Alaska 520 516 492 46 7.9 7.3 Arizona 516 521 497 26 10.4 7.6 Arkansas 572 572 556 5 6.8 4.6 California 500 513 498 49 10.9 5.5 接下来的目的:在一个 x - y 坐标的图表里面放置各个州,使指标相似的州之间的距离比较接近。 首先,我们只要数据中的第1列到第6列,因为第0列是各州的名称。利用
distance.pdist()和distance.squareform()计算出距离矩阵。 在这里,简要介绍一下distance.pdist()和distance.squareform():distance.pdist()计算在 n 维空间中两两之间的距离。距离值越大,相关度越小。distance.pdist()的返回值是一个距离向量。
scipy.spatial.distance.pdist(X, metric='euclidean', **kwargs)函数名是 Pairwise Distance 的简写, pairwise 是指两两的,对于一个二维数组,
pdist()用于计算任意两行之间的距离。distance.pdist()的参数:
- X:
ndarray类型,n 维空间中 m 个观测值构成的 m 行 n 列的数组- metric:计算距离的函数,有效值是
‘braycurtis’,‘canberra’,‘chebyshev’,‘cityblock’,‘correlation’,‘cosine’,‘dice’,‘euclidean’,‘hamming’,‘jaccard’,‘jensenshannon’,‘kulsinski’,‘mahalanobis’,‘matching’,‘minkowski’,‘rogerstanimoto’,‘russellrao’,‘seuclidean’,‘sokalmichener’,‘sokalsneath’,‘sqeuclidean’,‘yule’- **kwargs:
dick类型,metric的额外参数
distance.squareform()把向量形式的距离向量表示转换成方形的距离矩阵 (dense matrix) 形式,也可以把方形的距离矩阵转换为距离向量。 在计算样本集中的样本之间的距离矩阵时,squareform()函数和pdist()函数经常同时出现,squareform()函数的参数就是pdist()函数的返回值,把pdist()返回的一维形式,拓展为矩阵。 添加代码:
edu_x=edu.iloc[:,1:7] #选择edu中的第 1 列到第 6 列DM_dist = distance.squareform(distance.pdist(edu_x, metric="euclidean")) #计算距离矩阵代码的输出结果为一个矩阵(可以自行打印查看),每个单元格表示该州和另一个州之间相距多远(欧几里得像素距离)。比如说,第2行第2列的值就是阿拉巴马州和阿拉斯加州之间的距离。对象本身在此时并不太重要,重要的是相互之间的差距。
3.降维
怎样将这个的矩阵变成一幅
x - y轴上的图表呢?现在还不行,除非我们为各州建立一套x - y轴的坐标。这就是MDS()函数的作用。它会把距离矩阵作为输入,然后返回一系列点,这些点之间的差距将和矩阵所指定的保持一致。
clf2 = MDS(n_components=2,dissimilarity="precomputed") #将矩阵降成2维数据edu_t2 = clf2.fit_transform(DM_dist) #先拟合数据,再标准化print(edu_t2) #查看数据我们可以看到现在每一行数据都有自己的
x - y轴坐标了。
[[ -43.97286465 23.1268358 ][ 49.6051295 5.29747171]···[ 106.77988548 -43.71168863][ 61.56148089 -7.81235842]]4.绘制散点图
在获取每一行数据的
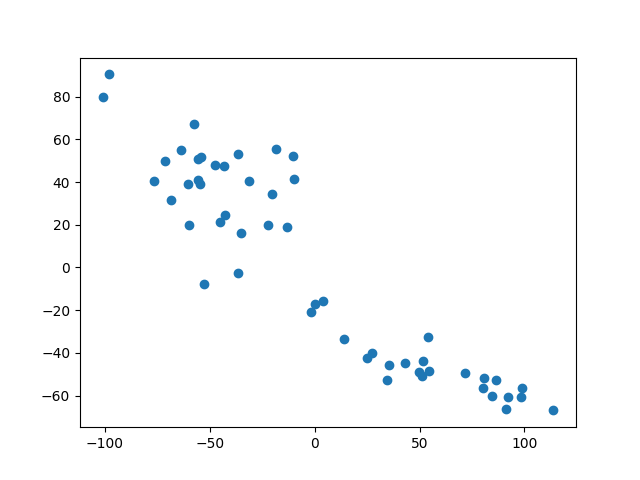
x - y轴坐标的基础上,我们用scatter()函数绘制散点图,添加代码如下:
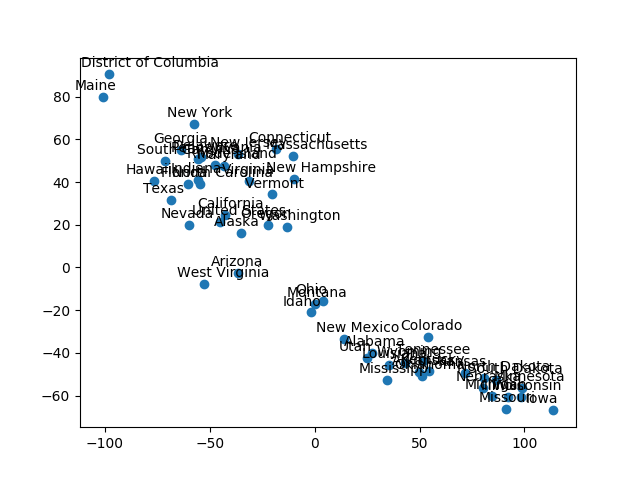
fig,ax=plt.subplots() #subplots返回画布和子图ax.scatter(edu_t2[:,0],edu_t2[:,1]) #绘制散点图结果如下图1所示:
图1 显示多维量法结果的散点图
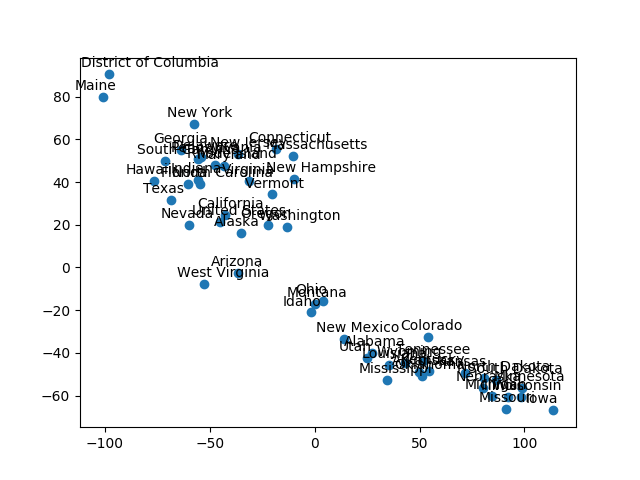
看起来不错。每个圆点都代表一个州。不过还有一个问题:我们不知道哪个点代表哪个州。我们还需要为每个点加上标签。添加代码如下:
names=list(edu.iloc[:,0]) #选取各州名称for i in range(len(names)):plt.annotate(names[i], xy = (edu_t2[:,0][i],edu_t2[:,1][i]), xytext=(-20, 5), textcoords='offset points') #为各数据点添加对应的州名,其中参数 xytext 和 textcoords 为设置标注位置 和 xy 偏差值来定位标注文字所在的位置结果如下图2所示:
图2 为圆点添加州名,以便观察每个州被放在了什么位置
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,对数据进行降维,并根据降维结果绘制散点图,同时标记每个数据点的州名。
测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。
图片预期输出示例:
# -*- coding: utf-8 -*-
import pandas as pd #用于生成满足绘图要求的数据格式
from sklearn.manifold import MDS #用于MDS降维
import matplotlib.pyplot as plt #用于绘制撒点图
from sklearn.cluster import KMeans #用于Kmeans聚类
from scipy.spatial import distance #用于计算获取距离矩阵
edu=pd.read_csv(r"MDS/csv/education.csv") #读取csv数据,返回值为二维标记数据结构 DataFrame
def plot():
# ********* Begin *********#
edu_x=edu.iloc[:,1:7] #选择edu中的第 1 列到第 6 列
DM_dist = distance.squareform(distance.pdist(edu_x, metric="euclidean")) #计算距离矩阵
clf2 = MDS(n_components=2,dissimilarity="precomputed")
edu_t2 = clf2.fit_transform(DM_dist)
fig,ax=plt.subplots()
ax.scatter(edu_t2[:,0],edu_t2[:,1])
names=list(edu.iloc[:,0])
for i in range(len(names)):
plt.annotate(names[i], xy = (edu_t2[:,0][i],edu_t2[:,1][i]), xytext=(-20, 5), textcoords='offset points')
# ********* End *********#
plt.savefig("MDS/studentanswer/level_1/education.png")
plt.close()
第2关:美国国家教育统计中心数据——分别按特征和聚类结果着色
任务描述
本关任务:在前一关降维的基础上,对美国国家教育统计中心数据分别按不同特征与聚类结果着色。
相关知识
为了完成本关任务,你需要掌握: 1.对数据按不同特征着色; 2.对数据进行聚类,并按聚类结果着色。
按不同特征着色
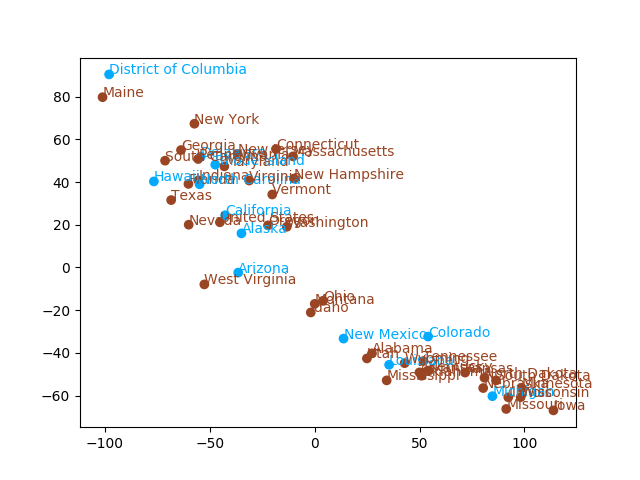
对辍学率按照四分位数5.3% 进行着色,遍历每一行数据,检查数据中的辍学率。添加代码如下:
dropout_rate_colors_list=[]for i in range(0,len(edu_x["dropout_rate"])):if edu_x["dropout_rate"][i]>5.3:dropout_rate_colors_list.append("#00AAFF") #大于5.3的数据为蓝色,并添加到颜色列表中else:dropout_rate_colors_list.append("#994523") #小于5.3的数据为棕色,并添加到颜色列表中同时,对绘图相关的代码进行修改,主要是补充颜色参数:
ax.scatter(edu_t2[:,0],edu_t2[:,1],color=dropout_rate_colors_list) #在绘制散点图的函数中,补充颜色参数names=list(edu.iloc[:,0]) #选择州名这一列数据for i in range(len(names)):plt.annotate(names[i], xy = (edu_t2[:,0][i],edu_t2[:,1][i]),color=dropout_rate_colors_list[i]) #在文本标记函数中,补充颜色参数效果如下图1所示:
图1 按辍学率进行着色的各个州
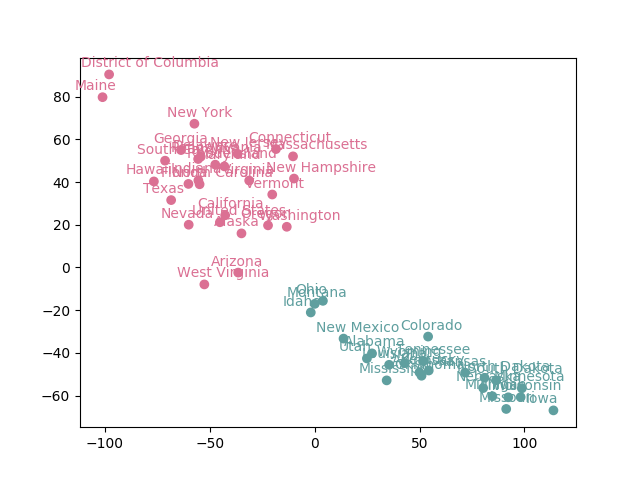
如果按阅读科目的平均分来着色,结果又会怎样?添加代码如下:
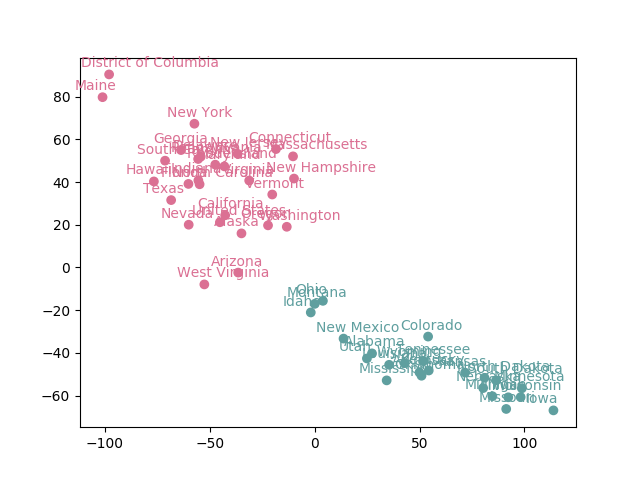
reading_colors_list=[]average=sum(edu_x["reading"])/len(edu_x["reading"]) #计算阅读平均值for i in range(0,len(edu_x["reading"])):if edu_x["reading"][i] < average:colors_list.append("#DB7093") #小于平均值的数据为粉红色,并添加到颜色列表中else:colors_list.append("5F9F9F") #大于平均值的数据为灰绿色,并添加到颜色列表中同时别忘了修改绘图相关的代码。 结果如下图2所示:
图2 按阅读科目平均分进行着色的各个州
现在似乎已经浮现出清晰的模式了,低分的州都在左上方,高分的州都在右下方。按聚类结果着色
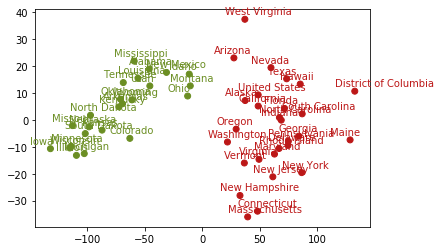
首先,对 K-means 聚类进行简要介绍。 k 均值聚类算法( k-means clustering algorithm )是一种迭代求解的聚类分析算法,其步骤是,预将数据分为 K 组,则随机选取 K 个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。 在
sklearn.cluster.KMeans中,常用以下几个参数:
- n_clusters:
int,生成的聚类数,即产生的质心( centroids )数- max_iter:
int,执行一次 k - means 算法所进行的最大迭代数- n_init:
int,用不同的质心初始化值运行算法的次数,最终解是在 inertia 意义下选出的最优结果- init:此参数指定初始化方法,默认值为
'k-means++',有三个可选值:'k-means++','random',或者传递一个ndarray向量 在这部分,我们添加如下代码,实现聚类。查看
k = 2 #聚类的类别iteration = 500 #聚类最大循环次数data_zs = 1.0*(edu_x - edu_x.mean())/edu_x.std() #数据标准化model = KMeans(n_clusters = k, max_iter = iteration) #分为k类model.fit(data_zs) #开始聚类edu_y = pd.concat([edu_x, pd.Series(model.labels_, index = edu_x.index)], axis = 1) #将edu_x和标签列合并edu_y.rename(columns={0: 'label'}, inplace = True) #将标签列的列名修改为 "label" ,inplace = True不创建新的对象,直接对原始对象进行修改edu_y的数据:
reading math writing ... pupil_staff_ratio dropout_rate label0 501 515 493 ... 7.9 4.4 11 557 552 549 ... 6.7 2.3 02 520 516 492 ... 7.9 7.3 13 516 521 497 ... 10.4 7.6 14 572 572 556 ... 6.8 4.6 0可以看到,每行数据均已经被分类,类型非0即1。 接下来,我们要按类型为数据添加颜色,添加代码如下:
clustering_colors_list=[]for i in range(0,len(edu_y)):if int(edu_y.iloc[i,-1])==0:clustering_colors_list.append("#6b8e23") #聚类类型为0的数据标记绿色,并添加到颜色列表中else:clustering_colors_list.append("#bc1717") #聚类类型为1的数据标记红色,并添加到颜色列表中并对绘图相关的代码进行修改,添加代码如下:
ax.scatter(edu_t2[:,0],edu_t2[:,1],color=clustering_colors_list) #修改散点图中颜色参数names=list(edu.iloc[:,0])for i in range(len(names)):plt.annotate(names[i], xy = (edu_t2[:,0][i],edu_t2[:,1][i]),color=clustering_colors_list[i]) #修改文本标记的颜色参数聚类结果如下图3所示:
图3 基于 Kmeans 模型聚类得到的结果
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,在第一关降维的基础上,绘制散点图,并按阅读科目的平均分来着色,小于平均值的数据为粉红色(
"#DB7093"),大于平均值的数据为灰绿色("5F9F9F")。测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。
图片预期输出示例:
# -*- coding: utf-8 -*-
import pandas as pd #用于生成满足绘图要求的数据格式
from sklearn.manifold import MDS #用于MDS降维
import matplotlib.pyplot as plt #用于绘制撒点图
from sklearn.cluster import KMeans #用于Kmeans聚类
from scipy.spatial import distance #用于计算获取距离矩阵
edu=pd.read_csv(r"MDS/csv/education.csv") #读取csv数据,返回值为二维标记数据结构 DataFrame
def plot():
# ********* Begin *********#
edu_x=edu.iloc[:,1:7] #选择edu中的第 1 列到第 6 列
DM_dist = distance.squareform(distance.pdist(edu_x, metric="euclidean")) #计算距离矩阵
clf2 = MDS(n_components=2,dissimilarity="precomputed")
edu_t2 = clf2.fit_transform(DM_dist)
fig,ax=plt.subplots()
reading_colors_list=[]
average=sum(edu_x["reading"])/len(edu_x["reading"]) #计算阅读平均值
for i in range(0,len(edu_x["reading"])):
if edu_x["reading"][i] < average:
reading_colors_list.append("#DB7093") #小于平均值的数据为粉红色,并添加到颜色列表
else:
reading_colors_list.append("#5F9F9F") #大于平均值的数据为灰绿色,并添加到颜色列
ax.scatter(edu_t2[:,0],edu_t2[:,1],color=reading_colors_list)
names=list(edu.iloc[:,0]) #选择州名这一列数据
for i in range(len(names)):
plt.annotate(names[i], xy = (edu_t2[:,0][i],edu_t2[:,1][i]), xytext=(-20, 5), textcoords='offset points',color=reading_colors_list[i])
plt.show()
# ********* End *********#
plt.savefig("MDS/studentanswer/level_2/education.png")
plt.close()
地理数据可视化
第1关:对全球未成年人生育率数据实现地理数据可视化——对数据进行处理
任务描述
本关任务:本次实训提供了《2008年联合国人类发展报告》中的未成年人生育率数据,我们首先需要对数据进行处理和简要分析。
相关知识
为了完成本关任务,你需要掌握:
- 对数据进行处理;
- 对数据进行简要分析
对数据进行处理
首先要载入待使用的包,还有数据:
from pyecharts import Geo #从 pyecharts 中导入 Geo 类import pandas as pd #导入 pandas#导入 csv 表df=pd.read_csv(r'pyechartadol-fertility.csv',encoding='gb18030')现在检查一下头几行数据,输入变量
df,之后设置你希望看到的行数。
print(df[0:5])
latitude ad_fert_rate hdi_rank longitude country 0 64.57131364 8.6 1 17.93155909 1 -32.44479091 14.9 2 135.9337909 2 -43.49638636 22.6 3 0.996154545 3 39.095963 35.9 4 -101.601563 4 53.41276818 15.9 5 -8.243890909 第一列
latitude显示的是纬度,第二列ad_fert_rate显示的是未成年人生育率数据,第三列hdi_rank显示的是序号,第四列longitude为经度,第五列country为国家名。比如说第一行数据为在经度为17.93155909,纬度为64.57131364的挪威,未成年人生育率为8.6‰,为了能在地图上展现数据,我们必须要把国家名与国家所在经纬度绑定起来,添加代码如下:
#对df类的数据迭代处理,将country值作为key,经纬度值生成的列表作为value,生成字典geo_countries_coords={df.iloc[i]['country']:[df.iloc[i]['longitude'],df.iloc[i]['latitude']] for i in range(len(df))}输出示例:
{'Norway': [17.93155909, 64.57131364], 'Australia': [135.9337909, -32.44479091]....}添加代码,生成两个 list,用于后续的绘图:
attr=list(df['country']) #生成国家名列表value=list(df['ad_fert_rate']) #生成生育率值列表我们可以利用
describe()方法观察ad_fert_rate数据的特征,添加代码:
print(df['ad_fert_rate'].describe())输出结果如下:
count 173.000000mean 52.889595std 44.008710min 3.20000025% 16.20000050% 39.00000075% 78.200000max 201.400000Name: ad_fert_rate, dtype: float64其中,
count表示数据的数量,mean表示数据的均值,std表示数据的标准差,min表示数据中的最小值,25%表示数据的下四分位,50%表示数据的中位数,75%表示数据的上四分位,max表示数据中的最大值。这些数据对我们来说已经可以理解了,但我们只是受众中的一部分。如果希望其他没有看过此数据的人也能理解数据所表达的含义,就需要在接下来通过可视化的方式直接展现数据。编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,利用
describe()方法输出ad_fert_rate数据的特征。测试说明
平台会对你编写的代码进行测试,如果你的输出与正确答案输出一致,则通关。 答案预期输出示例:
count 173.000000mean 52.889595std 44.008710min 3.20000025% 16.20000050% 39.00000075% 78.200000max 201.400000Name: ad_fert_rate, dtype: float64
from pyecharts import Geo
import pandas as pd
#导入csv表
df=pd.read_csv(r'pyecharts_map/csv/adol-fertility.csv',encoding='gb18030')
# ********* Begin *********#
geo_countries_coords={df.iloc[i]['country']:[df.iloc[i]['longitude'],df.iloc[i]['latitude']] for i in range(len(df))}
attr=list(df['country'])
value=list(df['ad_fert_rate'])
print(df['ad_fert_rate'].describe())
# ********* End *********#
第2关:对全球未成年人生育率数据实现地理数据可视化——创建Geo对象
任务描述
本关任务:为实现地理数据可视化,本关需要了解用于绘制地图的 pyecharts 包,以及如何创建地图对象 Geo 。
相关知识
为了完成本关任务,你需要掌握:
- 熟悉 pyecharts ;
- 创建 Geo 对象。
熟悉 pyecharts
pyecharts 是一个由百度开源的数据可视化库,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。 pyecharts 具有如下特性:
- API 设计简洁,使用流畅,支持链式调用
- 囊括了数十种常见图表,图表样式丰富,本次实训我们将采用 pyecharts 的地理图表实现数据可视化
- 支持主流 Notebook 环境,Jupyter Notebook 和 JupyterLab
- 可轻松集成至 Flask,Django 等主流 Web 框架
- 详细的文档和示例,帮助开发者更快的上手项目,感兴趣的同学可以点击链接查看 pyecharts 更多特性 pyecharts文档
创建Geo对象
想要在地图上展现数据,我们需要创建
Geo对象和展示坐标点,首先我们来创建Geo对象。
geo=Geo() #创建Geo对象,用于画出地图的背景Geo 中包含众多参数,为得到更好的展示效果,可通过这些参数对图像进行灵活且细致的调整。
Geo(title,subtitle,width,height,title_pos,title_top,title_color,subtitle_color,title_text_size,subtitle_text_size,background_color,page_title,renderer,is_animation)各参数说明如下:
- title:主标题文本,支持换行,默认为
""- subtitle:副标题文本,支持换行,默认为
""- width:画布宽度,默认为
800(px)- height:画布高度,默认为
400(px)- title_pos:标题距离左侧距离,默认为
'left',有'auto','left','right','center'可选,也可为百分比或整数- title_top:标题距离顶部距离,默认为
'top',有'top','middle','bottom'可选,也可为百分比或整数- title_color:主标题文本颜色,默认为
'#000'- subtitle_color:副标题文本颜色,默认为
'#aaa'- title_text_size:主标题文本字体大小,默认为 18
- subtitle_text_size:副标题文本字体大小,默认为 12
- background_color:画布背景颜色,默认为
'#fff'- page_title:指定生成的 html 文件中
title标签的值。默认为'Echarts'- renderer:指定使用渲染方式,有
'svg'和'canvas'可选,默认为'canvas'; 3D 图仅能使用'canvas'- param extra_html_text_label:额外的 HTML 文本标签( p 标签)。类型为
list,list[0]为文本内容,list[1]为字体风格样式(选填)。如["this is a p label", "color:red"]- param is_animation:是否开启动画,默认为
True。实际使用过程中,我们其实经常用到的就几个参数,如
title,title_color,title_pos,width,height,background_color,只要熟悉这几个基本就够用了,所有参数都有默认值,这意味着在最极端情况下,直接用Geo()也可以,不过画出来的就是一张白纸。选用以上几个参数后,我们添加代码如下:
from pyecharts import Geo #从 pyecharts 中导入 Geo 类geo = Geo('世界未成年人生育率分布',title_color = "#003399", title_pos = "center",width = 1600,height = 800,background_color = "#C6E2FF")下图1是这一步的效果图,即地图的背景:
图1 创建Geo对象的示例效果图
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,生成 html 文件,展示地图背景。参数设置如下: 标题:"educoder" 画布宽度:400 画布高度:400 标题位置:画布正中央 标题颜色:
"#FF0011"背景颜色:"#404A59"测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。 图片预期输出示例:


from pyecharts import Geo
import pandas as pd
#导入csv表
df=pd.read_csv(r'pyecharts_map/csv/adol-fertility.csv',encoding='gb18030')
# ********* Begin *********#
geo = Geo('educoder',title_color ="#FF0011", title_pos = "center",width = 400,height = 400,background_color = "#404A59")
# ********* End *********#
#生成html文件
geo.render( 'pyecharts_map/studentfile/studentanswer/level_2/map_geo.html')
第3关:对全球未成年人生育率数据实现地理数据可视化——在地图上展现坐标点
任务描述
本关任务:综合前两关学习的内容,本关我们需要在地图上将这些数据以气泡图的形式进行展示。
相关知识
为了完成本关任务,你需要掌握:
- 在地图上展现坐标点的方法;
- 综合前两关的知识,在地图上将这些数据以气泡图的形式进行展示。
在地图上展示坐标点
展示坐标点采用
geo.add()方法实现。geo.add()的作用就是将点展示到上面加载的地图上,add()有很多参数,各参数说明如下:
- series_name:
str,系列名称,用于tooltip的显示,legend的图例筛选- names:
list,数据项 (坐标点名称)- value:
list,数据项 (坐标点值)- type:
Geo图类型,有scatter,effectScatter,heatmap,lines4 种,默认"scatter"- is_selected:默认
'True',是否选中图例- symbol:默认
circle,标记图形形状有circle,pin,rect,diamon,roundRect,arrow,triangle- symbol_size:默认 12 ,标记的大小
- color:默认
None,label颜色- maptype:地图选择,如广东、广州、china、world
- is_roam:默认
'True',是否开启鼠标缩放和平移漫游。'scale'缩放、'move'平移、'True'都开启- is_visualmap:默认
'True',显示图例条- visual_range:图例条范围
- visual_text_color:图例条颜色
- geo_normal_color:常态下地图的颜色
- geo_emphasis_color:触发下地图的颜色(鼠标放在地图上)
- effect_scale:涟漪的多少,当
type = "effectScatter"时才有效- is_label_show:显示标签
- label_text_color:标签颜色
- label_pos:默认
"inside",标签位置包括'inside','top','bottom','left','right'- border_color:边界颜色
- visual_type:设置的是哪个视觉映射组件,可选
'size'和'color',默认为color- visual_range_size:显示的点的半径大小范围,默认
[20, 50]- is_piecewise:颜色是否分段显示(
'False'为渐变,'True'为分段)- geo_cities_coords:使用我们自定义的地点的经纬度数据
最常用的是
series_name、names、value、type、maptype、is_visualmap、visual_range、visual_text_color、symbol_size,其中series_name、names、value、maptype这四个是必填项。在地图上,以气泡图的形式展现数据
在前两关的基础上,我们添加代码如下:
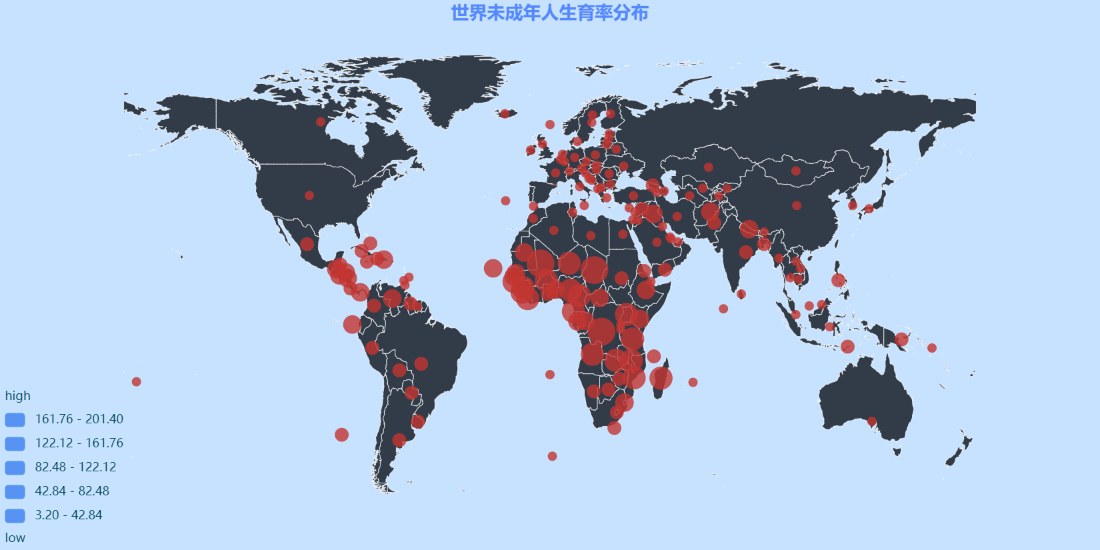
geo.add("",attr,value,is_label_show = False, #不显示标签type="scatter", #显示为散点图is_visualmap = True, #显示图例is_piecewise = True, #分段显示图例visual_split_number = 5, #图例分为几组visual_range = [min(value),max(value)], #可视化数据范围visual_type = "size",visual_range_size = [value[i]*3.14 for i in range(len(df))], #气泡大小visual_text_color="#004455", #标签颜色border_color = '#ffffff', #地图边界颜色label_text_color="#004455", #标签颜色maptype = 'world', #选择地图为世界地图geo_cities_coords=geo_countries_coords) #使用自定义的 经纬度数据geo.render( 'D:\map\世界未成年人生育率分布.html')注意,这两个参数是绘制气泡图的关键,可以控制是否生成气泡图,以及气泡的大小,气泡的大小可以根据数值和展示效果合理调整。我们添加代码如下:
visual_type="size", #“size”选择绘制气泡图,“color”选择绘制彩色散点图visual_range_size=[value[i]*3.14 for i in range(len(df))], #控制气泡大小生成的图片为 html 文件,如下图1所示:
图1 世界未成年人生育分布图
根据提示,综合前两关的知识,在右侧编辑器 Begin-End 区间补充代码,生成 html 文件,将未成年人生育率数据在世界地图上以气泡图的形式展示,参数设置参照上文相关知识的说明。
测试说明
平台会对你编写的代码进行测试,如果你的图形与正确答案图形一致,则通关。 图片预期输出示例:
from pyecharts import Geo
import pandas as pd
#导入csv表
df=pd.read_csv(r'pyecharts_map/csv/adol-fertility.csv',encoding='gb18030')
# ********* Begin *********#
geo_countries_coords={df.iloc[i]['country']:[df.iloc[i]['longitude'],df.iloc[i]['latitude']] for i in range(len(df))}
attr=list(df['country'])
value=list(df['ad_fert_rate'])
geo = Geo('educoder',title_color = "#FF0011", title_pos = "center",width = 400,height = 400,background_color = "#404A59")
geo.add("",attr,value,
is_label_show = False, #不显示标签
type="scatter", #显示为散点图
is_visualmap = True, #显示图例
is_piecewise = True, #分段显示图例
visual_split_number = 5, #图例分为几组
visual_range = [min(value),max(value)], #可视化数据范围
visual_type = "size",
visual_range_size = [value[i]*3.14 for i in range(len(df))], #气泡大小
visual_text_color="#004455", #标签颜色
border_color = '#ffffff', #地图边界颜色
label_text_color="#004455", #标签颜色
maptype = 'world', #选择地图为世界地图
geo_cities_coords=geo_countries_coords) #使用自定义的 经纬度数据
geo.render( 'D:\map\世界未成年人生育率分布.html')
# ********* End *********#
#生成html文件
geo.render( 'pyecharts_map/studentfile/studentanswer/level_3/map.html')



















 2527
2527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











