







训练的目的
用已知的训练集X和贝叶斯分类规则,估计概率密度函数

现实问题:
在特征的每一维不相互独立地情况下,为了保证估计的准确性,训练样本的数量N一定要足够大。一般来说,所需的样本数量随特征空间维数l的增加呈指数增长。比如在一维特征空间中N个训练样本可准确估计,则在l维空间中需要Nl个训练样本。因此如果l较大的话,要想准确估计是很困难的,因为很难有这么多的训练样本。
朴素贝叶斯
为了解决训练样本数量随特征空间维数l的增加呈指数增长的问题,朴素贝叶斯假设特征的每一维都是相互独立的(注:该假设在一定程度上会降低估计的准确度),则:
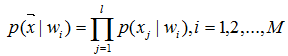
这样在训练时,就只需N*l个训练样本了。
在分类时,将未知样本分类到概率密度函数值最大的那一类















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









