







该实验的数据集是MostPopular Data Sets(hits since 2007)中的wine数据集,这是是对在意大利同一地区生产的三种不同品种的酒,做大量分析所得出的数据。这些数据包括了三种酒中13种不同成分的数量。
经过几天对数据集以及分类算法的研究,详细研究了朴素贝叶斯分类器和其他学习算法,包括决策树和神经网络等等。同时由于这个数据集有13个属性,用决策树实现起来会很复杂。我最终选择了用贝叶斯分类算法来实现。编程的时候采用c++语言实现分类的功能。我将178个样本分成118个训练样本和60个测试样本,采用朴素贝叶斯分类算法,计算出先验概率和后验概率,通过比较概率的最大值,判别出测试样本所属于的酒的类型,同时输出测试样本计算的正确率和错误率。
1.实验数据集介绍
1.1Wine数据集
该实验的数据源是Wine data,这是对在意大利同一地区生产的三种不同品种的酒,做大量分析所得出的数据。如下图1-1所示:

这些数据包括了三种酒中13种不同成分的数量。13种成分分别为:Alcohol,Malicacid,Ash,Alcalinity of ash,Magnesium,Total phenols,Flavanoids,Nonflavanoid phenols,Proanthocyanins,Color intensity,Hue,OD280/OD315 of diluted wines,Proline。在 “wine.data”文件中,每行代表一种酒的样本,共有178个样本;一共有14列,其中,第一列为类标志属性,共有三类,分别记为“1”,“2”,“3”;后面的13列为每个样本的对应属性的样本值。其中第1类有59个样本,第2类有71个样本,第3类有48个样本。
由于数据源文件中的每个样本的数据都是完整的,没有空缺值等,所以我没有对该数据源文件进行数据的清理工作。
2.实验方案
2.1朴素贝叶斯分类算法
每个数据样本用一个n维特征向量X={x1,x2,…,xn}表示,分别描述对n个属性A1,A2,..,An样本的n个度量。假定有m个类C1,…,Cm,对于数据样本X,分类法将预测X属于类Ci,当且仅当:P(Ci|X)> P(Cj|X),1<=j<=m而且j不等于i。
根据贝叶斯定理, :P(Ci|X)=P(X|Ci)P(Ci)/P(X)
由于P(X)对于所有类都是常数,只需最大化P(X|Ci)P(Ci),计算P(X|Ci),朴素贝叶斯分类假设类条件独立.即给定样本属性值相互条件独立,即:
,在使用中,p常用频度代替。
2.2朴素贝叶斯分类的原理与流程
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。朴素贝叶斯分类的正式定义如下:
1、设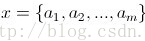
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合。
3、计算
。
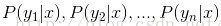
4、如果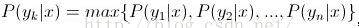
则
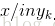
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
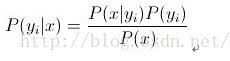
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
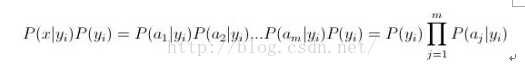
根据上述分析,朴素贝叶斯分类的流程可以由下图2-1表示(暂时不考虑验证):

在http://archive.ics.uci.edu/ml/网页上下载实验所用的Wine数据集。点击Wine数据集,在页面上,点击Data Folder,下载wine.data数据,即为实验所需的数据集。
首先,将Wine数据集分成118个训练样本和60个测试样本,分别保存在“Ttrainingwine.data”和 “testwine.data”中。用DataRead从文件中读取数值。
然后用朴素贝叶斯算法的思想:
1.统计三类红酒数据的数量,各自求和,拿各自类的数量除以总数,求出它们的先验概率p(Q1),p(Q2),p(Q3),保存在数组R中的R[0], R[1], R[2]。
2.分别求P(Xk|Q1)中 ,P(Xk|Q2)中和 P(Xk|Q3) 中Xk的个数。
3.计算概率p(X|Q1),计算p(Q1)*p(X|Q1),同样的方法去计算概率p(X|Q2), p(Q2)*p(X|Q2), p(X|Q3), p(Q3)*p(X|Q3),把这三个计算出来的概率值p(Q1)*p(X|Q1),p(Q2)*p(X|Q2),p(Q3)*p(X|Q3)保存在数组gailv中的gailv[0],gailv[1],gailv[2]。
4.比较gailv[0],gailv[1],gailv[2],找出最大值,最大值所对应的那个类即为我们要找的wine的分类。
3.3朴素贝叶斯算法实现的源代码
关于具体的实现代码见下面,此处不做详细的说明。
实验结果如下面的截图所示。
源代码:
MachineLearning.h:
#include <string>
#include <set> //set是C++标准库中的一种关联容器。所谓关联容器就是通过键(key)来读取和修改元素。
//set容器的每一个键只能对应一个元素,即不存在键相同的不同元素。
#include <map> //map 一种容器 也叫关联数组
//你先把它理解成数组 一个个的元素知道吧
//然后你再这样理解,每个元素都有两个值,一个叫“键”,一个叫“值”
//你可以通过“键”找到相关的“值”
//通常map容器 只能存入单一实例,就是说不能有相同的“键/值”
//map 就是 在key和value之间建立映射,是的可以通过key访问/获取value。
#include <vector> //标准库Vector类型,使用需要的头文件
//vector是一种顺序容器,事实上和数组差不多,但它比数组更优越。
//一般来说数组不能动态拓展,因此在程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









