







1. 介绍
过去的视觉识别都是基于SIFT 和 HOG。
- SIFT
- HOG
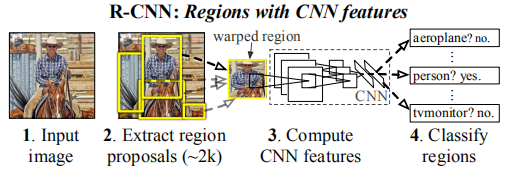
如上图所示,R-CNN这个物体检查系统可以大致分为四步进行:
1).获取输入图像
2).提取约2000个候选区域
3).将候选区域分别输入CNN网络(这里需要将候选图片进行缩放)
4).将CNN的输出输入SVM中进行类别的判定
2. R-CNN的物体检测
R-CNN物体检测系统包含三个模块:
1)第一个模块是生成与分类独立的候选区域;这些候选区域定义了检测器有效候选区域集。
2)第二个模块是一个大的卷积神经网络,它从每个区域提取一个固定长度的特征向量。
3)第三个模块是SVM线性分类集。
2.1 模型设计
2.1.1 候选区域
目前生成与分类队里的候选区域的方法有很多;例如包括:
- objectness [1],
- selective search [32],
- category-independent object proposals [11],
- constrained parametric min-cuts (CPMC) [5],
- multi-scale combinatorial
- grouping [3],
- Cires¸an et al. [6],
R-CNN使用selective search方法进行候选区域的工作。
2.1.2 特征提取
- 特征向量提取
R-CNN从每个候选区域的4096维特征向量提取;是通过AlexNet神经网络并基于Caffe框架实现的。 - 神经网络结构
输入图像大小为227*227;5个卷积层和2个全连接层组成。 - 兼容
为了与AlexNet网络结构兼容,R-CNN统一转换成227*227的尺寸大小对每一个候选区域。
需要注意的是,在对候选区域进行转换的时候,R-CNN对所有区域进行了膨胀处理:将紧密边界框box周围,人工添加p像素,文中使用p=16
2.2 测试阶段检测
在测试阶段,对测试图像集,使用selective search的fast mode方法 提取大约2000个候选区域。
提取特征:扭曲每个候选区域,并且前向传播通过CNN。
评分:对每一个类别,每个提取的特征向量通过SVM进行打分。
确定最终边界框Box:对每一个类别,计算IoU重叠程度值,应用非极大值抑制方法,以最高分的区域为基础,剔除掉那些重叠位置的区域。
2.2.1 运行时分析
两个处理方式提升检测效果。
首先,CNN参数值共享;
其次,低维度的特征向量计算(UVA检测系统360K相比,只有4k dimensional)。
接下来就是一些数据,证明效率比UVA系统、DPMs和hashing高。
2.3 训练
2.3.1 有监督的预训练
框架:Caffe CNN 库
数据集:ILSVRC 2012。图像级别标注,没有边界框标签。
简明讲,R-CNN接近匹配AlexNet的性能,获取2.2%的top-1错误率,高于ILSVRC 2012 验证集。这个差异缘于训练过程的简单化。
2.3.2 Domain-specific fine-tuning
约定:IoU值大于等于0.5是正样本,否则为负样本。
训练策略:使用随机梯度下降法SGD,初始学习率为0.001,128的batch大小。
2.3.3 目标分类
引入:二分类识别汽车;很明显包含一辆汽车的图像是正样本,而没有小汽车的图像是负样本。但是不清楚的是,如何标注与汽车重叠的区域呢?
解决:R-CNN采用IoU重叠阈值解决上述问题。这个阈值设定为0.3,如果低于0.3,则此区域被判定为Negative。文章选择阈值0.3,是基于验证集网格搜索决定的{0,0.1,…, 0.5}
IoU overlap threshold import:当设置为0.5时,mAP下降了5个百分点;而设置为0时,下降了4个百分点。
hard negative mining method:为了适应大的训练数据,R-CNN采用hard negative mining method方法,可以快速收敛,并且单通道通过所有图像后,mAP停止增长。
2.4 Results on PASCAL VOC 2010-12
R-CNN神经网络结构在VOC 2012训练上微调CNN,优化支持向量机在训练和验证集上。文章向验证服务提交了两种算法的测试结果,一个是带边界框回归(R-CNN BB-Bounding box regression),另一个是不带边界框回归(R-CNN)。
对此两种算法结果,和当时流行的目标检测算法进行对比。

3. Visualization, ablation, and modes of error
3.1. 可视化已学习的特征
在CNN中第一层直接显示,并且容易理解;一般情况下,用来捕捉物体边界和突出的颜色。对于CNN后面的层的理解才是挑战。R-CNN提出一个简单的(和互补的)非参数方法,直接显示神经网络中已学习到的特征参数等。
这个简单的方法,其原理是挑选出一个特征,将其作为一个物体检测器。也就是说,在候选区域集上,计算特征的激活值activations,并且基于激活值进行从高到低的排序,最后显示高分值区域。
3.2 框架精简研究
3.2.1 没有微调fine-tuning情况下的性能
为了清楚哪一层对目标检测的性能是关键的。文章分析了基于VOC 2007数据的CNN最后三层的结果。
惊奇的发现,移除第七和第六的全连接层,竟然有这很好的结果;虽然第五层的池化层特征仅仅使用6%的CNN参数计算。因此,CNN中最重要的当属卷积层,而非属全连接层。
3.2.1 带有微调fine-tuning情况的性能
为了和不带有fine-tuning情况进行对比,文章同样拿VOC 2007数据集进行训练验证;结果证明,fine-tuning微调后,第六和第七全连接层提升效果明显(详看下表二、三、五、六行)。因此,第五层池化层 从 ImageNet 训练集中学习了物体的泛化能力,然而性能的提升则是通过特定领域的 fine-tune。

3.3 检测错误分析
文章采用Hoiem等人提出的检测分析工具,用来揭露文章方法的错误模型;并且通过此分析工具不断的进行微调以达到更好的效果。
3.4 边界框回归
基于错误模型的分析,文章使用一个简单的方法降低局部错误。
关于此简单方法的介绍:受Felzenszwalb等人提出的边界框回归的启发;文章训练一个线性回归模型预测一个新的检测窗,此预测是基于给定selective search候选区域的第五层池化层特征。从几个表中和图中,可以看出这个简单的方法修复了大量的错误检测,mAP提升了3到4个百分点。
4. 语义分割
略















 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









