







理解RDD

- 刚从地里挖出来的土豆食材、清洗过后的干净土豆、生薯片、烤熟的薯片,流水线上这些食材的不同形态,就像是 Spark 中 RDD 对于不同数据集合的抽象。
- RDD 具有 4 大属性,分别是 partitions、partitioner、dependencies 和 compute 属性。正因为有了这 4 大属性的存在,让 RDD 具有分布式和容错性这两大最突出的特性。
- partitions: 图中每一颗土豆就是 RDD 中的数据分片,3 颗土豆一起对应的就是 RDD 的 partitions 属性。
- partitioner: 根据尺寸的不同,即食薯片会被划分到不同的数据分片中。像这种数据分片划分规则,对应的就是 RDD 中的 partitioner 属性。
- dependencies: 每种食材形态都依赖于前一种食材,这就像是 RDD 中 dependencies 属性记录的依赖关系
- compute: 不同环节的加工方法,对应的刚好就是 RDD 的 compute 属性。
RDD的特点

图中展示的是textFile方法读取文件来创建RDD。
RDD要从两个方面考量:1.实现的功能 2.如何进行分区
- 每一个RDD的计算功能是不同的,所以RDD称之为最小的计算单元
- RDD的计算是分布式的,RDD封装了计算逻辑,那么接下来如何将数据分配给不同的Executor做分布式计算,这就是分区的目的
RDD代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合
-
RDD在底层原码中就是一个抽象类
-
弹性
1.存储的弹性:内存与磁盘的自动切换;Spark的计算是基于内存的,但是内存是有限的,在某些情况下可以将数据放在磁盘。
2.容错的弹性:数据丢失可以自动恢复;根据RDD的血缘关系可以追踪到数据源,所以数据丢失问题不大
3.计算的弹性:计算出错重试机制;计算出错,可以从头重新计算
4.分片的弹性:可根据需要重新分片。分片就是分区,可以根据需要重新分区,比如有四个Executor,但是上一层RDD只有两个分区,那么可以在当前RDD重新指定分区个数,更合理的利用资源 -
分布式
数据存储在大数据集群不同节点上。数据的存储和计算都在分布式集群中 -
数据集
RDD封装了计算逻辑,并不保存数据。 -
数据抽象
RDD是一个抽象类,需要子类具体实现 -
不可变
RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD, -
可分区、并行计算
通过分区将数据分开交给不同的Executor,从而实现并行计算
RDD的五大核心属性
- RDD源码中对RDD的说明

(1)分区列表
RDD数据结构中存在分区列表,将数据进行分区,分区间的数据是完全相互独立的,互不影响,然后交给不同的Task,目的是实现并行计算,是实现分布式计算的重要属性。

(2)分区计算函数
Spark在计算时,是使用分区计算函数对每一个分区进行计算。但是,每一个分区计算函数的计算逻辑都是一样的,是由RDD事先封装好,传递到Executor的!

(3)RDD之间的依赖关系

- RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系。从方法中可以看出一个RDD的依赖是一个列表。
- 所谓的RDD依赖关系就是包装,想要获取最外层的RDD,就要逐层网内,从最原始的RDD开始构建。

以wordcount例子为例,每一个算子都会产生一个RDD,都是一层一层包装 - RDD不是单依赖,意味着可以多个RDD合成一个RDD
(4)分区器(可选)
- 分区器制定分区规则
- 当数据为KV类型数据时,可以通过设定分区器自定义数据的分区
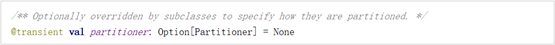
(5)首选位置(可选)
用于解决将task交给哪个Executor进行运算的问题。


- 当数据和Executor在一个节点的时候,Task首选分配给当前节点的Executor,这样避免了数据的网络传输,效率最优。
- 核心概念:移动数据不如移动计算 ;在有数据的节点上创建Executor进行计算
RDD执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合
Spark框架在执行时,先申请资源;然后将应用程序的数据处理逻辑分解成一个一个的计算任务;然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD是Spark框架中用于数据处理的核心模型,接下来我们看看,在Yarn环境中,RDD的工作原理
1.启动Yarn集群环境,此时有了资源
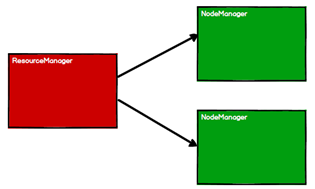
2.Spark通过申请资源创建调度节点和计算节点,也就是Driver和Executor,二者都是运行在NodeManager上
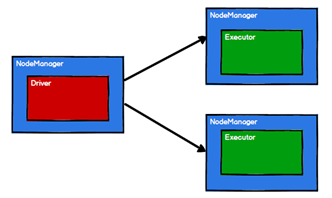
-
Spark框架根据需求将计算逻辑根据分区划分成不同的Task,并将Task放入TaskPool,放进任务池是为了等待被调度
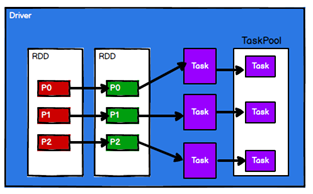
-
调度节点(Driver)将任务根据计算节点Executor的状态 和 RDD首选位置的配置将Task发送到对应的计算节点进行计算
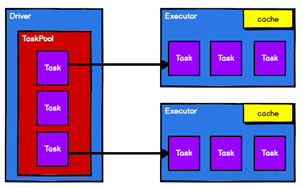
从以上流程可以看出RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给Executor节点执行计算,接下来我们就一起看看Spark框架中RDD是具体是如何进行数据处理的。
Spark中关键角色
1.DAGScheduler
- DAGScheduler是一家公司的总架构师

- DAGScheduler把DAG拆分成很多的Tasks,每组的Tasks都是一个 Sage。
- 解析时是以Shuffle为边界 反向解析构建Stage
每当遇到 Shuffle,就会产生新的Stage
然后以一个个TaskSet(每个Stage封装一个TaskSet)的形式提交给底层调度器TaskScheduler。
它的三个主要职责:
- 根据用户代码构建DAG;
- 以Shuffle为边界切割Stages;
- 基于Stages创建TaskSets,并将TaskSets提交给TaskScheduler 请求调度
DAGScheduler划分Stage的原理
Spark在分布式环境下将数据分区,然后将作业转化为DAG, 并分阶段进行 DAG的调度和任务的分布式并行处理。DAG将调度提交给DAGScheduler, DAGScheduler调度时会根据是否需要经过Shuffle过程将Job划分为多个 Stage。

-
在上图中,RDD a到ShuffledRDD之间,以及UnionRDD到CoGroupedRDD 之间的数据需要经过Shuffle过程,因此RDD a和UnionRDD分别是Stage1跟Stage3和Stage2跟Stage3的划分点。
-
而ShuffledRDD到CoGroupedRDD 之间,以及RDD b到MappedRDD到UnionRDD和RDDc到UnionRDD之间的数据不需要经过Shuffle过程。因此,ShuffledRDD和CoGroupedRDD的依赖是窄依赖,两个RDD属于同一个Stage3,其余RDD划分为2个Stage。
-
Stage1和Stage2是相对独立的,可以并行运行。Stage3则依赖于Stage1和Stage2的运行结果,所以Stage3最后执行。
-
由此可见,在DAGScheduler调度过程中,Stage阶段换份是依据作业是否有Shuffle过程,也就是存在ShuffleDependency的宽依赖时,需要进行Shuffle,此时才会将作业划分为多个Stage
2. SchedulerBackend
- SchedulerBackend是一家公司的人力资源总监。
对于集群中可用的计算资源,SchedulerBackend 用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。
这里的 ExecutorDataMap 是一种 HashMap,它的 Key 是标记 Executor 的字符串,Value 是一种叫做 ExecutorData 的数据结构。ExecutorData 用于封装 Executor 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等等,它相当于是对 Executor 做的"资源画像"。
SchedulerBackend 可以同时提供多个 WorkerOffer 用于分布式任务调度。WorkerOffer 这个名字起得很传神,Offer 的字面意思是公司给你提供的工作机会,到了 Spark 调度系统的上下文,它就变成了使用硬件资源的机会。
SchedulerBackend 与集群内所有 Executors 中的 ExecutorBackend 保持周期性通信,双方通过 LaunchedExecutor、RemoveExecutor、StatusUpdate 等消息来互通有无、变更可用计算资源。
3.TaskScheduler
- TaskScheduler是一家公司干活的总负责人。
TaskScheduler的核心任务是提交TaskSets到集群运算并汇报结果。
他主要做三件事:
- 为TaskSet创建和维护一个TaskSetManager,并追踪任务的本地性以及错误信息。
遇到Straggle任务时,会放到其他节点进行重试。 - 向DAGScheduler汇报执行情况,包括在Shuffle输出丢失的时候报告 fetch failed错误等信息。
- 每个任务都是自带本地倾向性的,换句话说,每个任务都有自己擅长做的事情。
4.ExecutorBackend
- ExecutorBackend是分公司的人力资源主管。
ExecutorBackend拿到Task任务之后,随即把Task派发给分公司的工人。这些工人,就是Executors线程池中一个又一个的CPU线程,每个线程负责处理一个Task。
每当 Task 处理完毕,这些线程便会通过 ExecutorBackend,向 Driver 端的 SchedulerBackend 发送 StatusUpdate 事件,告知 Task 执行状态。接下来,TaskScheduler 与 SchedulerBackend 通过接力的方式,最终把状态汇报给 DAGScheduler。
直到整个Spark程序中的所有Task执行完毕。一次完整的Spark任务就执行结束了。















 2686
2686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









