










关联规则挖掘是数据挖掘的重要任务之一,主要用于从大型数据库中发现变量之间的有趣关系或模式。关联规则广泛应用于市场篮子分析、推荐系统、网络入侵检测等领域。
1. 基本概念
(1) 关联规则的定义
- 关联规则:形式为 X⇒Y 的规则,表示当条件项集 X 出现时,结果项集 Y 很可能同时出现。
- X 和 Y 是项集,且 X∩Y=∅。
- 示例:{牛奶, 面包} ⇒\Rightarrow {黄油},表示购买牛奶和面包的顾客也倾向于购买黄油。
(2) 重要指标
-
支持度 (Support):
- 定义:规则 X⇒Y的支持度是 X∪Y同时出现的频率。
- 公式:
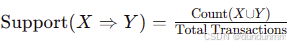
- 含义:描述规则的重要性。
-
置信度 (Confidence):
- 定义:规则 X⇒Y的置信度是 X 出现的条件下 Y出现的概率。
- 公式:
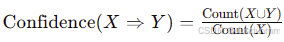
- 含义:描述规则的可靠性。
-
提升度 (Lift):
- 定义:规则 X⇒YX \Rightarrow Y 的提升度衡量 XX 和 YY 是否独立。
- 公式:
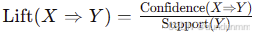
- 含义:提升度 >1> 1 表示 XX 和 YY 有正相关性;提升度 =1= 1 表示独立;提升度 <1< 1 表示负相关性。
2. 常用算法
(1) Apriori算法
- 基本思想:
- 使用“频繁项集挖掘”的思想,从小到大逐步生成频繁项集。
- 基于先验性质:频繁项集的所有子集必然是频繁的。
- 算法流程:
- 初始化:从所有单项开始,计算其支持度,过滤低于阈值的项。
- 生成候选项集:根据频繁 k-项集生成 k+1-项候选集。
- 频繁项集筛选:计算候选项集的支持度,保留满足阈值的项。
- 重复步骤2-3,直到无法生成新的频繁项集。
- 根据频繁项集生成关联规则,并计算置信度,筛选规则。
(2) FP-Growth算法
- 基本思想:
- 使用“频繁模式树” (FP-tree) 表示数据集,避免生成候选项集。
- FP-tree是一种压缩表示,减少了内存和计算成本。
- 算法流程:
- 构建FP-tree:通过扫描数据集,构建以频繁项为节点的树结构。
- 递归挖掘:在FP-tree上递归生成频繁项集。
- 生成规则:与Apriori相似。
(3) ECLAT算法
- 基本思想:
- 使用垂直数据格式,将每个项和其对应的事务ID表示为集合。
- 基于事务ID交集快速计算支持度。
- 优点:
- 避免频繁扫描事务数据库。
- 在稀疏数据中效率更高。
3. 关联规则挖掘的应用
- 市场篮子分析:发现商品之间的购买模式,例如“买啤酒的人往往会买尿布”。
- 推荐系统:根据用户历史行为,推荐潜在感兴趣的商品或服务。
- 网络入侵检测:发现异常访问模式,提高网络安全性。
- 医学研究:发现疾病与症状、治疗方案之间的潜在关系。
4. 优化与挑战
(1) 优化方向
- 数据预处理:减少稀疏项集,提高计算效率。
- 分布式挖掘:利用MapReduce等技术处理大规模数据。
- 动态更新:针对动态数据库的增量更新算法。
(2) 挑战
- 规则筛选:
- 大量规则可能造成信息过载,需要根据具体应用场景选择高价值规则。
- 高维数据:
- 高维度数据可能导致项集组合爆炸,需要改进算法。
- 噪声数据:
- 噪声数据可能影响规则的可靠性,需结合清洗技术。
5. 实践案例
以下是一个基于Python的简单关联规则挖掘示例:
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
# 示例数据
data = {'牛奶': [1, 0, 1, 1, 0],
'面包': [1, 1, 1, 0, 1],
'黄油': [0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# 挖掘频繁项集
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
print(frequent_itemsets)
# 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print(rules)
6. 总结
- 关联规则挖掘通过发现数据中的潜在模式,为商业决策和科学研究提供了有力支持。
- 理解支持度、置信度和提升度等指标,有助于挖掘有价值的规则。
- 选择适当的算法(如Apriori、FP-Growth)和工具(如Python的
mlxtend库)可以高效完成关联规则挖掘任务。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









