






🌟 小而强大的视觉模型:Moondream2
Moondream是一款免费开源的小型人工智能视觉语言模型。尽管其参数量较小(Moondream1仅有16亿,Moondream2为18.6亿),但它依然能够提供出色的视觉处理能力。该模型可以在本地计算机、移动设备甚至是Raspberry Pi上运行,能够快速理解和处理输入的图像信息,并对用户提出的问题进行解答。Moondream由开发者vikhyatk推出,采用了SigLP、Phi-1.5和LLaVa的训练数据集和模型权重初始化构建。该模型基于宽松的Apache 2.0许可证,允许商用使用。
📸 功能亮点
-
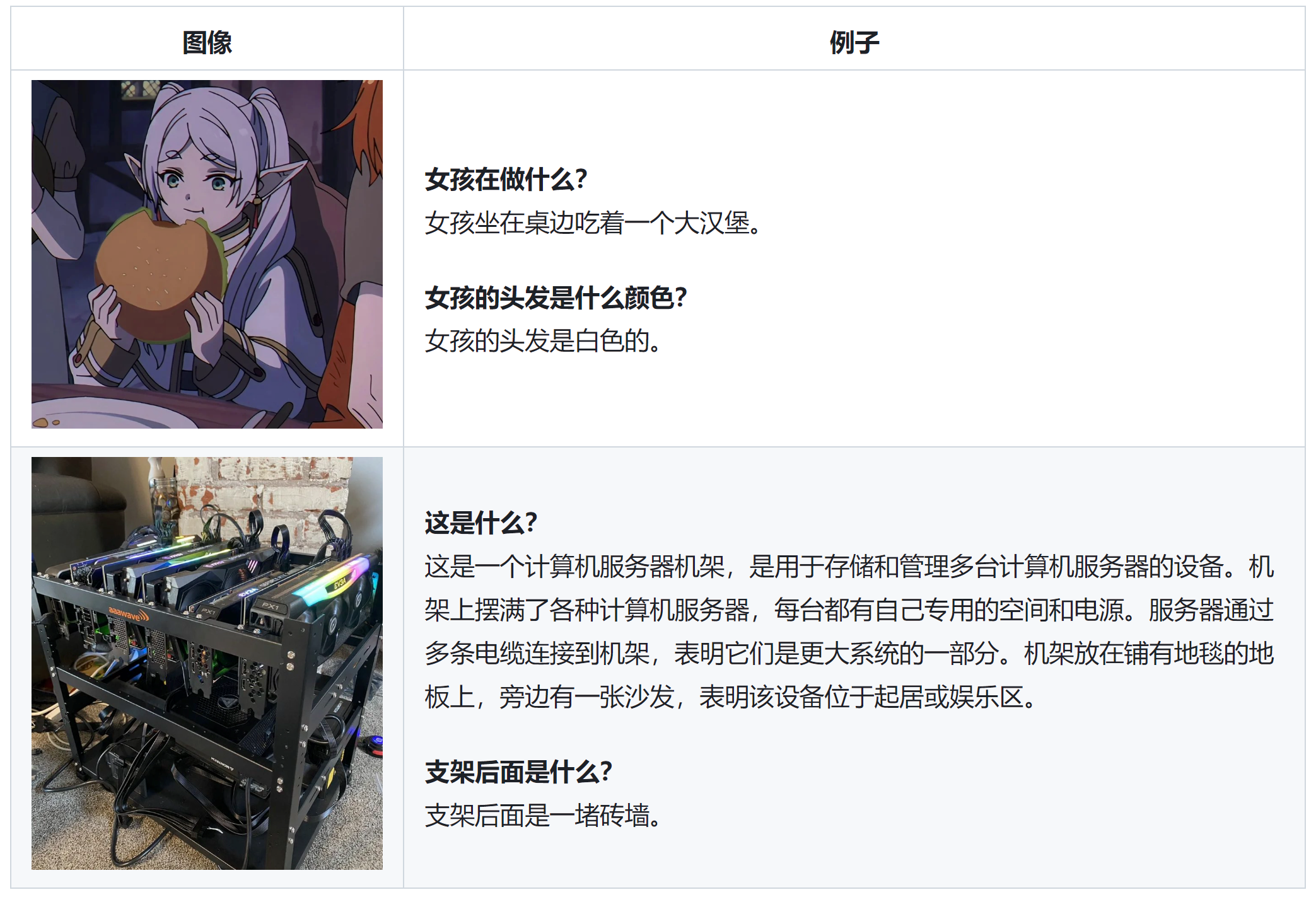
图像问题回答:模型能够回答关于图像的问题,例如“这个女孩在做什么?”、“女孩的头发是什么颜色?”等。
-
图像描述:模型可以对图像进行详细描述,例如“图片中有一个架子,上面放着各种电子设备。左边有一把椅子,背景是砖墙。”等。
-
批量推断:模型支持批量推断,可以同时处理多个图像和问题。
Moondream的这些功能使其在视觉处理任务中表现出色,适用于多种应用场景。无论是个人用户还是企业用户,都可以利用该模型实现高效的图像处理和理解。
安装指南
为了简化安装流程,Mac爱范团队将上述工具封装成了一个独立的启动包,用户只需简单点击即可运行,无需配置繁琐的Python环境。以下是获取和安装该应用的详细步骤:
下载应用
前往下载页面:🌟 小而强大的视觉模型:Moondream2_AI MAC范,点击页面右侧的下载按钮进行下载。
注意:仅支持搭载有 Mac M1/2/3 系列芯片的设备。
安装步骤
-
从上述链接下载DMG镜像文件,将
app文件拖拽到Applications文件夹中。 -
复制安装完成后,
首次启动先不要在启动台打开,在应用程序文件夹右键打开,如下所示,原因参考Mac 安装软件常见问题 -
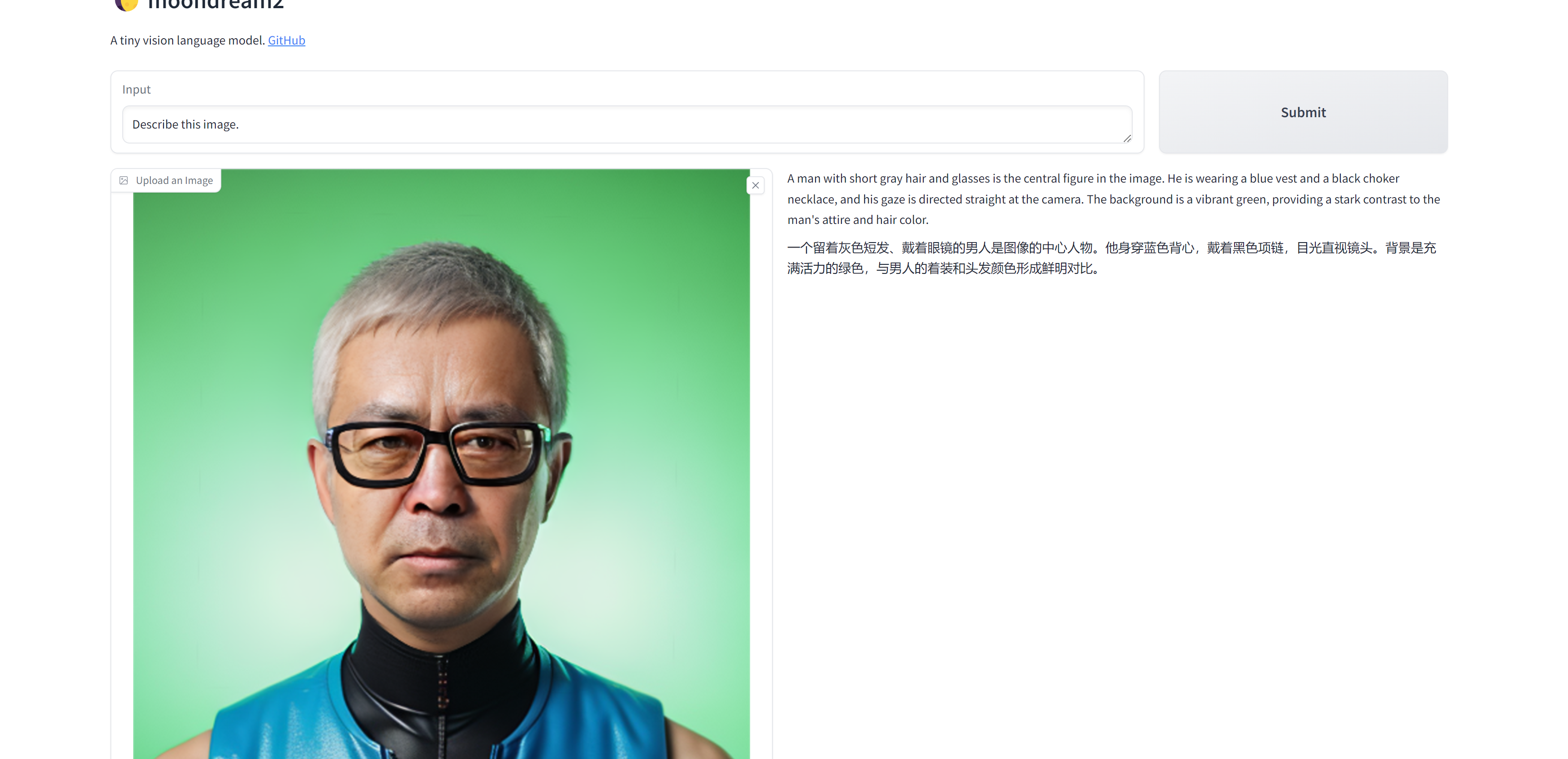
软件会自动在默认浏览器打开操作界面,地址为 http://127.0.0.1:7860/,此时可以开始在浏览器中使用。
各位新老朋友,麻烦点个赞👍和在看👀吧!















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









