






在工作中碰到需要对已经导出的excle文件进行格式转换,总是手动替换觉得重复性太高,所以写了一点代码,现在还有序号那一列没有完成
ip格式转换:
原图:

需要转成的格式:

import xlrd #引入库
import xlwt
#读文件
#打开文件并返回一个工作蒲对象。open_workbook可以点进去看看函数里面的参数的含义之类的
wb=xlrd.open_workbook(r"S:\测评部-第七组\003第七组\2022-05-25上海楷领科技有限公司-凌云集成电路设计赋能平台\05网络安全测试\change\Solved_123.60.55.30_rsas_host系统_漏洞情况汇总.xlsx")
sheet_num=wb.nsheets #获取excel里面的sheet的数量
sheet_names=wb.sheet_names() #获取到Excel里面所有的sheet的名称列表,即使没有sheet也能用。
sheet=wb.sheet_by_index(0) #通过索引的方式获取到某一个sheet,现在是获取的第一个sheet页,也可以通过sheet的名称进行获取,sheet_by_name('sheet名称')
rows=sheet.nrows #获取sheet页的行数,一共有几行
columns=sheet.ncols #获取sheet页的列数,一共有几列
list = [] # 装读取结果的序列
for rownum in range(2, rows): # 遍历每一行的内容
row = sheet.row_values(rownum) # 根据行号获取行
if row: # 如果行存在
app = [] # 一行的内容
for i in range(columns): # 一列列地读取行的内容
app.append(row[i])
list.append(app) # 装载数据
print(list)
#写入一个新的excle文件
# 1.创建 Workbook:wa
wa = xlwt.Workbook()
# # 2.创建 worksheet
ws = wa.add_sheet('漏洞清单')
#将list中的元素提取出来写入ws里
#一次写入一列,把list所有元素中的第2个元素写到ws的第3列(从第9行开始写入)
for j in range (len(list)):
ws.write(j+8,3,list[j][1])
ws.write(j+8,4,list[j][4])
ws.write(j+8,5,list[j][3])
ws.write(j+8,6,list[j][7])
#原文件的第4列需要提取IP后写入汇总后文件的第1列,提取端口号写入第2列,循环提取和写入
for k in range (len(list)):
dizhi=list[k][5].split()#提取IP地址后形成一个列表
print(dizhi)
duankou=dizhi[2].split(":")#在dizhi列表的基础上提取端口
# print(duankou)
ws.write(k+8,1,dizhi[1])#将IP写入表ws
ws.write(k+8,2,duankou[1])#将端口写入表ws
# 保存文件
wa.save(r'S:\测评部-第七组\003第七组\2022-05-25上海楷领科技有限公司-凌云集成电路设计赋能平台\08等级测评报告\myExcel.xls')
应用格式转换:
写文件还和上面一样,唯一不同的是应用原文件“漏洞地址”那一列直接写入新文件,不需要像主机原文件那样需要把ip和端口号提取出来
应用原文件:
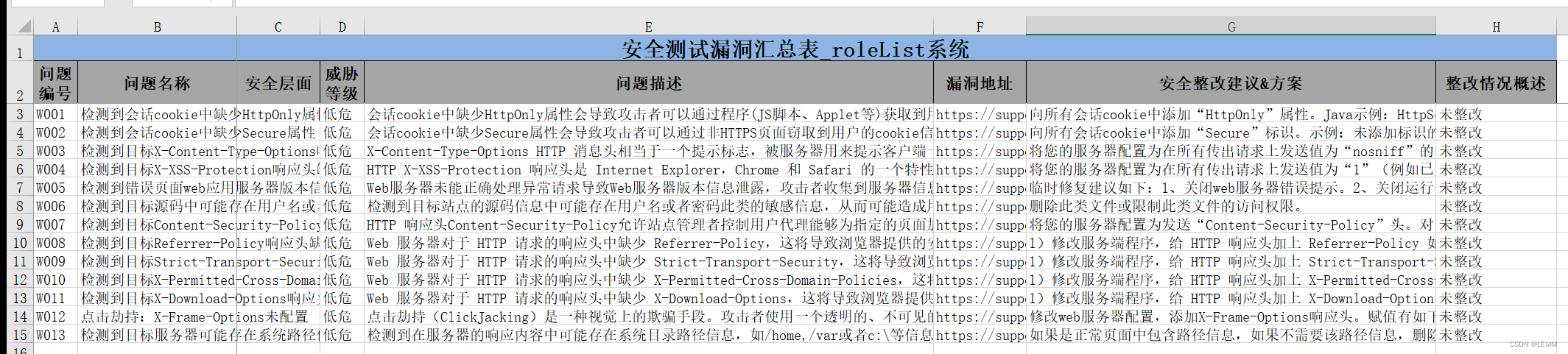
import xlrd #引入库
import xlwt
#读文件
#打开文件并返回一个工作蒲对象。open_workbook可以点进去看看函数里面的参数的含义之类的
wb=xlrd.open_workbook(r"S:\测评部-第七组\003第七组\2022-05-25上海楷领科技有限公司-凌云集成电路设计赋能平台\05网络安全测试\change\Solved_https___support.kltlingyun.com___roleList_rsas_web系统_漏洞情况汇总.xlsx")
sheet_num=wb.nsheets #获取excel里面的sheet的数量
sheet_names=wb.sheet_names() #获取到Excel里面所有的sheet的名称列表,即使没有sheet也能用。
sheet=wb.sheet_by_index(0) #通过索引的方式获取到某一个sheet,现在是获取的第一个sheet页,也可以通过sheet的名称进行获取,sheet_by_name('sheet名称')
rows=sheet.nrows #获取sheet页的行数,一共有几行
columns=sheet.ncols #获取sheet页的列数,一共有几列
list = [] # 装读取结果的序列
for rownum in range(2, rows): # 遍历每一行的内容
row = sheet.row_values(rownum) # 根据行号获取行
if row: # 如果行存在
app = [] # 一行的内容
for i in range(columns): # 一列列地读取行的内容
app.append(row[i])
list.append(app) # 装载数据
print(list)
#写入一个新的excle文件
# 1.创建 Workbook:wa
wa = xlwt.Workbook()
# # 2.创建 worksheet
ws = wa.add_sheet('漏洞清单')
#将list中的元素提取出来写入ws里
#一次写入一列,把list所有元素中的第2个元素写到ws的第3列(从第9行开始写入)
for j in range (len(list)):
ws.write(j+8,3,list[j][1])
ws.write(j+8,4,list[j][4])
ws.write(j+8,5,list[j][3])
ws.write(j+8,6,list[j][7])
ws.write(j+8,1,list[j][5])
ws.write(j+8,2,"N/A")
# 保存文件
wa.save(r'S:\测评部-第七组\003第七组\2022-05-25上海楷领科技有限公司-凌云集成电路设计赋能平台\08等级测评报告\yy.xls')














 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









