







作为原书《现代操作系统》的补充
伙伴系统
是用于分配连续的物理内存页的算法。
为什么要分配连续物理内存页?
实际问题在于有少数几个场景下一定需要用物理内存和物理内存地址,第一是页表本身的管理,既然内存映射依赖页表,那显然不能用虚拟内存来管理页表了,页表中的结构还必须保证在物理上也是连续的,不能跨过页边界跑到不连续的地方去。第二是给硬件使用的内存(典型的如DMA)也需要是在物理上连续的内存,它们是不经过内存映射的。这些内存同样有自己的生命周期,因而必须有物理内存分配器。既然反正都有了,那也不必拘泥于malloc+虚拟内存的方案了,很多地方就都可以用。
作者:灵剑
Why Contiguous memory allocation is required in linux?
有些IO设备只能处理连续范围物理内存,因此连续的内存分配是必需的。
Contiguous memory allocation (CMA) is needed for I/O devices that can only work with contiguous ranges of physical memory.
在IOMMU系统上,连续的地址空间可以映射到非连续的物理内存上。也有些设备能够作scatter/gather DMA
On systems with an I/O memory management unit (IOMMU), this would not be an issue because a buffer that is contiguous in the device address space can be mapped by the IOMMU to non-contiguous regions of physical memory
Also some devices can do scatter/gather DMA (i.e., can read/write from/to multiple non-contiguous buffers).
理想状态下,所有IO设备应当被设计成既能处理IOMMU,也能作scatter/gather DMA。但现实不是如此,有的设备只能工作在连续的物理内存上…(下文省略)
Ideally, all I/O devices should be designed to either work behind an IOMMU or should be capable of scatter/gather DMA. Unfortunately, this is not the case and there are devices that require physically contiguous buffers. There are two ways for a device driver to allocate a contiguous buffer…
与分页/分段算法的关系
我们已经了解了分页算法、虚拟页表、页置换算法。这时候又了解到伙伴系统,那它与分页、分段算法有什么关系呢?是平级关系吗?
SLAB分配器
有SLAB、SLUB、SLOB三种分配器,统称SLAB分配器。
linux slub实现 kmem_cache
根据书中描述,SLAB会为每个大小维护一个内存资源池(大小通常为
2
n
2^n
2n字节)。每个内存资源池会维护多个slab,而每个slab都由一个/多个连续的物理页组成,从伙伴系统申请而来。维护了current和partial两个指针,前者是用于当前分配的slab,后者指向一个队列的slab,备用。
个人认为,队列中的slab里,并非每个块都一定是空闲的,空闲块之间组成空闲链表,中间可能有已分配出去的内存块。只要你有一个空闲块,就可以加入partial的队列。
常用的空闲链表
有隐式空闲链表、显式空闲链表、分离空闲链表。
跟随wendeng的git博客可以了解三种链表。
此处作原文的附加阐述
隐式空闲链表
之所以称为隐式空闲链表是因为分配需要遍历堆中所有的块,才能知道空闲块的集合。自然分配效率低下。
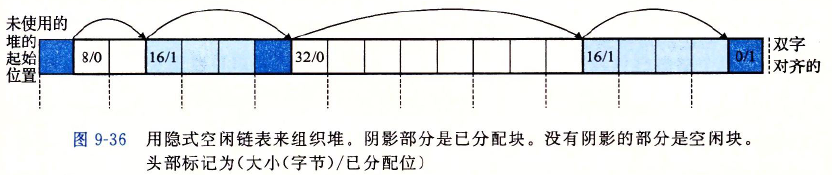
其中:
- 8/0是指该块大小为8,0表示它是空闲块。
- 16/1表示该块大小为16,1表示它不是空闲块,它已分配。
显式分配链表
如imageslr中详见"malloc 的实现方式二:显式空闲链表 + 按需分配"所说,这种方法的缺点是可能有外部碎片:
这种方式的缺点是:多次调用 malloc 后,空闲内存被切成很多的小内存片段,产生较多外部碎片,会导致用户在申请内存使用时,找不到足够大的内存空间。这时需要进行内存整理,将连续的空闲内存合并,但是这会降低函数性能。
这种做法会导致空闲链表不连续,有很多空闲块碎片,即使它们的总和大于所需分配的块,但每个块各自都不大于当前块。
另外该文的"malloc 的实现方式一:显式空闲链表 + 整块分配"标题可能写错,这一段没看懂建议跳过
分离空闲链表
如imageslr"malloc 的实现方式三:分离的空闲链表"中"分离适配"一节所说,会把内存分配的请求分散到不同的空闲链表上。这里还是看原文吧:

- 这种做法自然是能解决内部碎片的,因为按需从空闲块中取出需要的内存来分配。
- 外部碎片也是能解决大部分的:
- 因为从直觉上来说,外部碎片的产生是因为许多零碎的小内存块隔断了本来大块的空闲块,使得整个块不能连续地被利用。如果要获得一个完整的大内存块,可能需要中间好一些零碎的小内存块被释放,才能凑齐。
- 但如果在空闲链表里,分配的内存大小相近,则只需连续出现少量的内存块被释放,就能凑齐一个满足当前分配大小的空闲块,不那么容易出现外部碎片。
C 标准库中提供的 GNU malloc 包就是采用的这种方法















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









