







一、伙伴算法的由来
在实际情况中,操作系统必须能够在任意时刻申请和释放任意大小的内存,该函数的实现需要考虑延时问题和碎片问题。
延时问题指的是系统查找到可分配单元的时间变长,例如程序请求分配一个64KB的内存空间,系统查看64KB空间发现不全是空余的,于是查看65KB的空间,发现仍不能满足需求,直到查看80KB空间时,才满足了需求,这种方式请求次数多达17次,频繁操作时,非常耗时。
若系统以较大的定长空间来分配内存,在一定程度上可以节省时间,但带来的是碎片过多问题,由于每次用较大的空间进行分配,系统中出现大量碎片,导致内存浪费。严重者会导致内存无法完成分配,虽然仍有许多碎片空间。
基于此,系统需要一种能够高效分配内存,同时又能减少产生碎片的算法,伙伴算法能有效地解决该问题,如今已成为操作系统中的一种基础算法。
二、基本原理
伙伴算法(Buddy system)把所有的空闲页框分为11个块链表,每块链表中分布包含特定的连续页框地址空间,比如第0个块链表包含大小为2^0个连续的页框,第1个块链表中,每个链表元素包含2个页框大小的连续地址空间,….,第10个块链表中,每个链表元素代表4M的连续地址空间。每个链表中元素的个数在系统初始化时决定,在执行过程中,动态变化。
伙伴算法每次只能分配2的幂次页的空间,比如一次分配1页,2页,4页,8页,…,1024页(2^10)等等,每页大小一般为4K,因此,伙伴算法最多一次能够分配4M的内存空间。
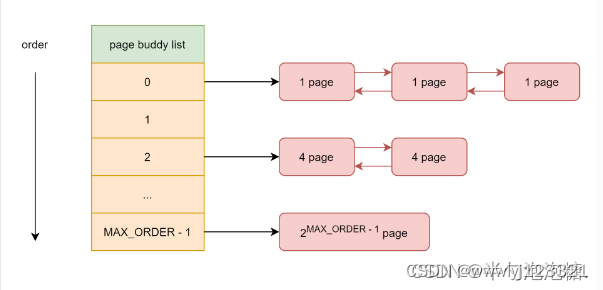
伙伴算法在内核中通常用free_area结构体表示,free_list链表数组,nr_free就是当前链表中空闲页框块数量。举例说明,free_area[2]中nr_free值为3,就是3个大小为4的页框块,总的空闲页就是3*4=12。
#define MAX_ORDER 11
struct free_area {//链表
struct list_head free_list[MIGRATE_TYPES];//页属性
unsigned long nr_free;//空闲页框块数目
};#define MAX_ORDER 11
struct zone{
struct free_area freearea[MAX_ORDER];
};
内存申请
例如需要分配16k的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去。如果free_area[3]也没有空闲,则从更上一级申请空间,依次递推,直到free_area[max_order],如果顶级都没有空间,那么就报告分配失败。
“伙伴关系”定义:
所谓“伙伴”,就是指在空闲块被分裂时,由同一个大块内存分裂出来的两个小块内存就互称“伙伴”。“伙伴”应当满足以下三个条件:
- 两个块大小相同
- 两个块地址连续
- 两个块必须是同一个大块中分离出来的
内存回收
回收是申请的逆过程,当释放一个内存块时,先在其对于的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^10为止。
三、源码分析
3.1、物理内存分配接口
伙伴系统有一个特点就是它所分配的物理内存页全部都是物理上连续的,并且只能分配 2 的整数幂个页,这里的整数幂在内核中称之为分配阶。下面要介绍的这些物理内存分配接口均需要指定这个分配阶,假设我们指定分配阶为 order,那么就会从伙伴系统中申请 2 的 order 次幂个物理内存页。
3.1.1、alloc_pages
struct page *alloc_pages(gfp_t gfp, unsigned int order);
- 输入参数:alloc_pages 函数用于分配 2 的 order 次幂个物理内存页,参数 gfp_t gfp 是内核中定义的一个用于规范物理内存分配行为的修饰符,这里我们先不展开。
- 返回值: struct page 类型的指针用于指向申请的内存块中第一个物理内存页。当系统中空闲的物理内存无法满足内存分配时,就会导致内存分配失败,alloc_pages,alloc_page 就会返回空指针 NULL 。
alloc_pages 函数用于分配多个连续的物理内存页,在内核的某些内存分配场景中有时候并不需要分配这么多的连续内存页,而是只需要分配一个物理内存页即可,于是内核又提供了 alloc_page 宏,用于这种单内存页分配的场景,我们可以看到其底层还是依赖了 alloc_pages 函数,只不过 order 指定为 0。
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
3.1.2、__get_free_pages
在物理内存分配成功的情况下,alloc_page 函数返回的都是指向其申请的物理内存块第一个物理内存页 struct page 指针。
大家可以直接理解成返回的是一块物理内存,而 CPU 可以直接访问的却是虚拟内存,所以内核又提供了一个函数 __get_free_pages ,该函数直接返回物理内存页的虚拟内存地址。用户可以直接使用。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
__get_free_pages 函数在使用方式上和 alloc_pages 是一样的,函数参数的含义也是一样,只不过一个是返回物理内存页的虚拟内存地址,一个是直接返回物理内存页。
事实上 __get_free_pages 函数的底层也是基于 alloc_pages 实现的,只不过多了一层虚拟地址转换的工作。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
// 不能在高端内存中分配物理页,因为无法直接映射获取虚拟内存地址
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
if (!page)
return 0;
// 将直接映射区中的物理内存页转换为虚拟内存地址
return (unsigned long) page_address(page);
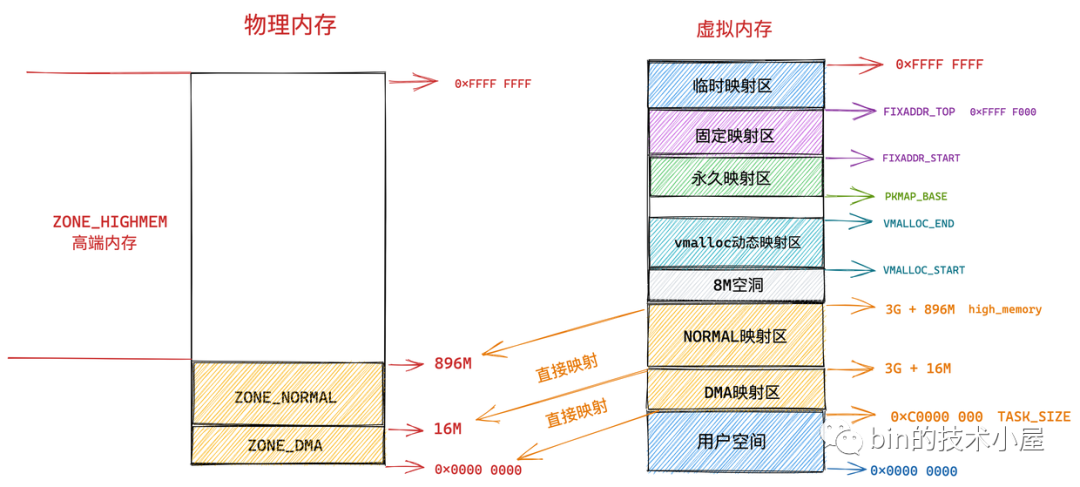
}page_address 函数用于将给定的物理内存页 page 转换为它的虚拟内存地址,不过这里只适用于内核虚拟内存空间中的直接映射区,因为在直接映射区中虚拟内存地址到物理内存地址是直接映射的,虚拟内存地址减去一个固定的偏移就可以直接得到物理内存地址。
如果物理内存页处于高端内存中,则不能这样直接进行转换,在通过 alloc_pages 函数获取物理内存页 page 之后,需要调用 kmap 映射将 page 映射到内核虚拟地址空间中。
3.1.4、get_zeroed_page
无论是 alloc_pages 也好还是 __get_free_pages 也好,它们申请到的内存页中包含的数据在一开始都不是空白的,而是内核随机产生的一些垃圾信息,但其实这些信息可能并不都是完全随机的,很有可能随机的包含一些敏感的信息。
这些敏感的信息可能会被一些黑客所利用,并对计算机系统产生一些危害行为,所以从使用安全的角度考虑,内核又提供了一个函数 get_zeroed_page,顾名思义,这个函数会将从伙伴系统中申请到内存页全部初始化填充为 0 ,这在分配物理内存页给用户空间使用的时候非常有用。
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
get_zeroed_page 函数底层也依赖于 __get_free_pages,指定的分配阶 order 也是 0,表示从伙伴系统中只申请一个物理内存页并初始化填充 0 。
3.1.5、__get_dma_pages
专门用于从 DMA 内存区域分配适用于 DMA 的物理内存页。其底层也是依赖于 __get_free_pages 函数。
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order);
3.2、物理内存释放接口
void __free_pages(struct page *page, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)3.2.1、__free_pages
同 alloc_pages 函数对应,用于释放一个或者 2 的 order 次幂个内存页,释放的物理内存区域起始地址由该区域中的第一个 page 实例指针表示,也就是参数里的 struct page *page 指针。
3.2.1、free_pages
同 __get_free_pages 函数对应,与 __free_pages 函数的区别是在释放物理内存时,使用了虚拟内存地址而不是 page 指针。
3.3、规范物理内存分配行为的掩码 gfp_mask
gfp是get free page的缩写,这个参数由3种flag组成,分别为action modifier, zone modifier,type。
3.3.1、Action Modifier
actions modifier 规定了内核应该如何分配内存(比如中断处理程序获取内存时要求不能睡眠)
这些内存分配行为修饰符同样也是定义在 /include/linux/gfp.h 文件中:
#define ___GFP_RECLAIMABLE 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_ZERO 0x100u
#define ___GFP_ATOMIC 0x200u
#define ___GFP_DIRECT_RECLAIM 0x400u
#define ___GFP_KSWAPD_RECLAIM 0x800u
#define ___GFP_NOWARN 0x2000u
#define ___GFP_RETRY_MAYFAIL 0x4000u
#define ___GFP_NOFAIL 0x8000u
#define ___GFP_NORETRY 0x10000u
#define ___GFP_HARDWALL 0x100000u
#define ___GFP_THISNODE 0x200000u
#define ___GFP_MEMALLOC 0x20000u
#define ___GFP_NOMEMALLOC 0x80000u
-
___GFP_RECLAIMABLE 用于指定分配的页面是可以回收的,___GFP_MOVABLE 则是用于指定分配的页面是可以移动的,这两个标志会影响底层的伙伴系统从哪个区域中去获取空闲内存页,这块内容我们会在后面讲解伙伴系统的时候详细介绍。
-
___GFP_HIGH 表示该内存分配请求是高优先级的,内核急切的需要内存,如果内存分配失败则会给系统带来非常严重的后果,设置该标志通常内存是不允许分配失败的,如果空闲内存不足,则会从紧急预留内存中分配。
-
___GFP_IO 表示内核在分配物理内存的时候可以发起磁盘 IO 操作。什么意思呢?比如当内核在进行内存分配的时候,发现物理内存不足,这时需要将不经常使用的内存页置换到 SWAP 分区或者 SWAP 文件中,这时就涉及到了 IO 操作,如果设置了该标志,表示允许内核将不常用的内存页置换出去。
-
___GFP_FS 允许内核执行底层文件系统操作,在与 VFS 虚拟文件系统层相关联的内核子系统中必须禁用该标志,否则可能会引起文件系统操作的循环递归调用,因为在设置 ___GFP_FS 标志分配内存的情况下,可能会引起更多的文件系统操作,而这些文件系统的操作可能又会进一步产生内存分配行为,这样一直递归持续下去。
-
___GFP_ZERO 在内核分配内存成功之后,将内存页初始化填充字节 0 。
-
___GFP_ATOMIC 该标志的设置表示内存在分配物理内存的时候不允许睡眠必须是原子性地进行内存分配。比如在中断处理程序中,就不能睡眠,因为中断程序不能被重新调度。同时也不能在持有自旋锁的进程上下文中睡眠,因为可能导致死锁。综上所述这个标志只能用在不能被重新安全调度的进程上下文中。
-
___GFP_DIRECT_RECLAIM 表示内核在进行内存分配的时候,可以进行直接内存回收。当剩余内存容量低于水位线 _watermark[WMARK_MIN] 时,说明此时的内存容量已经非常危险了,如果进程在这时请求内存分配,内核就会进行直接内存回收,直到内存水位线恢复到 _watermark[WMARK_HIGH] 之上。
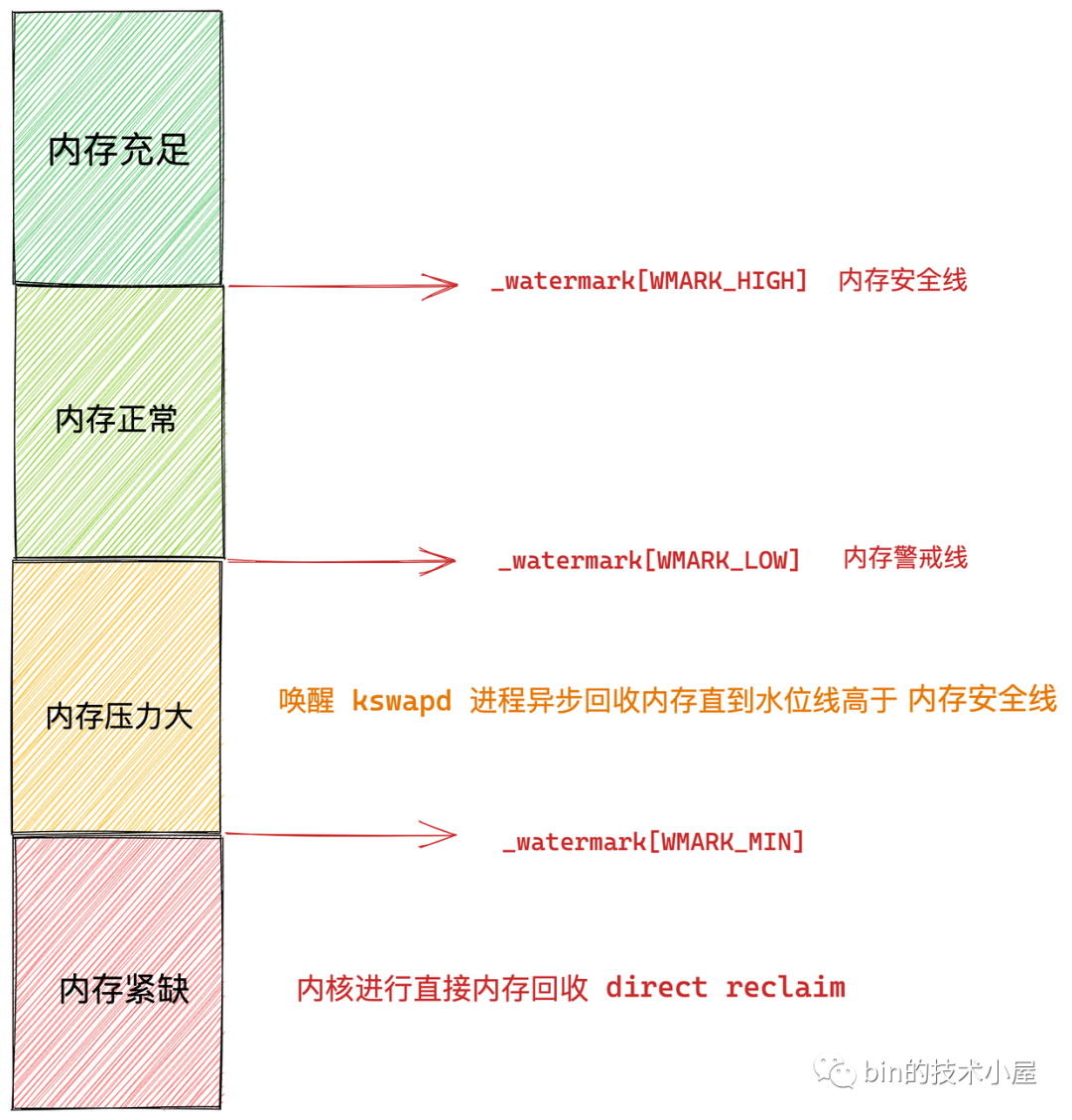
image.png
-
___GFP_KSWAPD_RECLAIM 表示内核在分配内存的时候,如果剩余内存容量在 _watermark[WMARK_MIN] 与 _watermark[WMARK_LOW] 之间时,内核就会唤醒 kswapd 进程开始异步内存回收,直到剩余内存高于 _watermark[WMARK_HIGH] 为止。
-
___GFP_NOWARN 表示当内核分配内存失败时,抑制内核的分配失败错误报告。
-
___GFP_RETRY_MAYFAIL 在内核分配内存失败的时候,允许重试,但重试仍然可能失败,重试若干次后停止。与其对应的是 ___GFP_NORETRY 标志表示分配内存失败时不允许重试。
-
___GFP_NOFAIL 在内核分配失败时一直重试直到成功为止。
-
___GFP_HARDWALL 该标志限制了内核分配内存的行为只能在当前进程分配到的 CPU 所关联的 NUMA 节点上进行分配,当进程可以运行的 CPU 受限时,该标志才会有意义,如果进程允许在所有 CPU 上运行则该标志没有意义。
-
___GFP_THISNODE 该标志限制了内核分配内存的行为只能在当前 NUMA 节点或者在指定 NUMA 节点中分配内存,如果内存分配失败不允许从其他备用 NUMA 节点中分配内存。
-
___GFP_MEMALLOC 允许内核在分配内存时可以从所有内存区域中获取内存,包括从紧急预留内存中获取。但使用该标示时需要保证进程在获得内存之后会很快的释放掉内存不会过长时间的占用,尤其要警惕避免过多的消耗紧急预留内存区域中的内存。
-
___GFP_NOMEMALLOC 标志用于明确禁止内核从紧急预留内存中获取内存。___GFP_NOMEMALLOC 标识的优先级要高于 ___GFP_MEMALLOC
3.3.2、Zone Modifier
zone modifyer 规定了从哪个区域(zone)分配内存

区域修饰符 zone modifiers 定义在内核 /include/linux/gfp.h 文件中:
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
大家这里可能会感到好奇,为什么没有定义 ___GFP_NORMAL 的掩码呢?
这是因为内核对物理内存的分配主要是落在 ZONE_NORMAL 区域中,如果我们不指定物理内存的分配区域,那么内核会默认从 ZONE_NORMAL 区域中分配内存,如果 ZONE_NORMAL 区域中的空闲内存不够,内核则会降级到 ZONE_DMA 区域中分配。
内核在 /include/linux/gfp.h 文件中定义了一个叫做 gfp_zone 的函数,这个函数用于将我们在物理内存分配接口中指定的 gfp_mask 掩码转换为物理内存区域,返回的这个物理内存区域是内存分配的最高级内存区域,如果这个最高级内存区域不足以满足内存分配的需求,则按照 ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA 的顺序依次降级。
下面是不同的 gfp_t 掩码设置方式与其对应的内存区域降级策略汇总列表:
| gfp_t 掩码 | 内存区域降级策略 |
|---|---|
| 什么都没有设置 | ZONE_NORMAL -> ZONE_DMA |
| __GFP_DMA | ZONE_DMA |
| __GFP_DMA & __GFP_HIGHMEM | ZONE_DMA |
| __GFP_HIGHMEM | ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA |

需要注意的是不能给__get_free_page()、 __get_free_pages()或者kmalloc()指定 __GFP_HIGHMEM,因为从高端内存中分配的页可能没有映射到到内核地址空间中,因此没有逻辑地址。不能返回一个有效的逻辑地址。
3.3.2、Type Flags
type flags实际上是前两者的组合,是为了方便某些场合下规定特定的flags而设计的,简化了flags的指定,减少错误的发生。
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
-
GFP_ATOMIC 是掩码 __GFP_HIGH,__GFP_ATOMIC,__GFP_KSWAPD_RECLAIM 的组合,表示内存分配行为必须是原子的,是高优先级的。在任何情况下都不允许睡眠,如果空闲内存不够,则会从紧急预留内存中分配。该标志适用于中断程序,以及持有自旋锁的进程上下文中。
-
GFP_KERNEL 是内核中最常用的标志,该标志设置之后内核的分配内存行为可能会阻塞睡眠,可以允许内核置换出一些不活跃的内存页到磁盘中。适用于可以重新安全调度的进程上下文中。
-
GFP_NOIO 和 GFP_NOFS 分别禁止内核在分配内存时进行磁盘 IO 和 文件系统 IO 操作。
-
GFP_USER 用于映射到用户空间的内存分配,通常这些内存可以被内核或者硬件直接访问,比如硬件设备会将 Buffer 直接映射到用户空间中
-
GFP_DMA 和 GFP_DMA32 表示需要从 ZONE_DMA 和 ZONE_DMA32 内存区域中获取适用于 DMA 的内存页。
-
GFP_HIGHUSER 用于给用户空间分配高端内存,因为在用户虚拟内存空间中,都是通过页表来访问非直接映射的高端内存区域,所以用户空间一般使用的是高端内存区域 ZONE_HIGHMEM。
3.4、源码分析
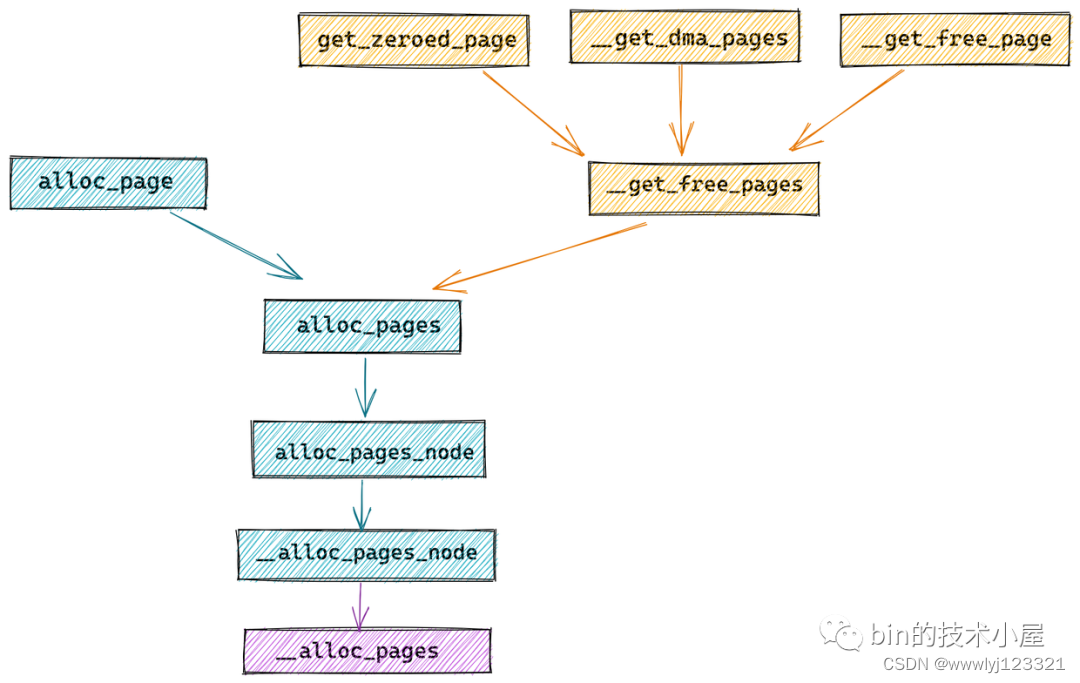
我们看到内存分配的任务最终会落在 alloc_pages 这个接口函数中,在 alloc_pages 中会调用 alloc_pages_node 进而调用 __alloc_pages_node 函数,最终通过 __alloc_pages 函数正式进入内核内存分配的世界~~
__alloc_pages 函数为 Linux 内核内存分配的核心入口函数
获取物理页面的核心流程由alloc_pages()函数来完成
//定义一个函数alloc_pages,它接受两个参数:gfp(页面分配标志)和order(要分配的连续页面的数量,存在形式为2的order次幂个物理页面,就是页块在free_area数组中的索引)。函数返回一个指向struct page的指针
struct page *alloc_pages(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;//初始化为系统的默认内存策略
struct page *page;//保存分配到的页面的地址。
// 检查当前是否在中断上下文中,以及是否为特定节点分配页面
// 如果不在中断中并且没有为特定节点请求页面,则获取当前任务的内存策
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);//获取当前任务的内存策略
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
//判断内存策略的模式是否为交叉分配
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));//是多首选节点模式,根据指定的多首选节点策略分配页
else if (pol->mode == MPOL_PREFERRED_MANY)//如果是优先分配多个节点
page = alloc_pages_preferred_many(gfp, order,
policy_node(gfp, pol, numa_node_id()), pol);
else//均不是,使用__alloc_pages方法,传入相关的节点和nodemask信息
page = __alloc_pages(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;//返回分配到的页面的地址
}
四、调试
1. buddy_info
buddy info 描述了当前可用内存的分布情况,实际上就是每一个zone下的free_area结构体情况,每一列表示对应链表中对应的nr_free值。
# cat /proc/buddyinfo
Node 0, zone DMA 4 4 3 3 3 3 2 0 1 1 2
Node 0, zone Normal 140 90 34 5201 2816 556 29 0 0 0 0
Node 0, zone HighMem 0 2542 1859 253 961 3568 560 19 1 0 0 可以看到这份信息里面包含3个zone, DMA, Normal, HighMem。
DMA 行第3列表示有4个 2^2 × page_size 的内存块可以用
HighMem的第4列表示253个 2^3 × page_size 的内存块可以用
以此类推,越是往后的空间,就越是连续,数目越多,就代表这个大小的连续空间越多,当大的连续空间很少的时候,也就说明,内存碎片已经非常多了。
全部加起来就是当前free状态的内存size
ref:
Linux内核学习笔记(二)内存管理_stored objects can be colored to prevent multiple -CSDN博客
https://www.cnblogs.com/cherishui/p/4246133.html
Linux内存分配与回收——伙伴算法_linux伙伴算法-CSDN博客
Linux 内存碎片化检视之 buddy_info | extfrag_index | unusable_index_cat /proc/buddyinfo-CSDN博客















 2245
2245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









