







模型表达(MODEL REPRESENTATION)
以之前的房屋交易问题为例,假使我们回归问题的训练集(Training Set)如下表所示:
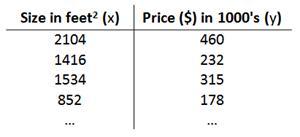
我们将要用来描述这个回归问题的标记如下:
- m 代表训练集中实例的数量
- x 代表特征/输入变量
- y 代表目标变量/输出变量
- (x,y) 代表训练集中的实例
- ( x(i) , y(i) ) 代表第 i 个观察实例
- h 代表学习算法的解决方案或函数也称为假设(hypothesis)
可以得到模型:
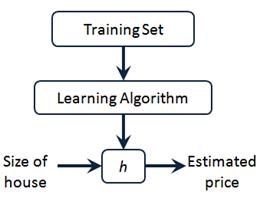
因而,要解决房价预测问题,我们实际上是要将训练集“喂”给我们的学习算法,进而学习得一个假设 h,然后将我们要预测的房屋的尺寸作为输入变量输入给 h,预测出该房屋的交易价格作为输出变量输出为结果。
那么,对于我们的房价预测问题,我们该如何表达 h?
一种可能的表达方式为:
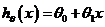
因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
代价函数(COST FUNCTION)
我们现在要做的就是为模型选择合适的参数参数(parameters)
θ0
和
θ1
。我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。
即使得代价函数最小:
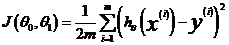
我们绘制一个等高线图,三个坐标分别为
θ0
和
θ1
和 J(
θ0,θ1
):
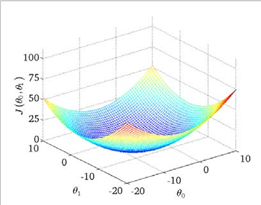
则可以看出在三维空间中存在一个使得 J( θ0 , θ1 )最小的点。
梯度下降(GRADIENT DESCENT)
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 J( θ0,θ1 )的最小值。
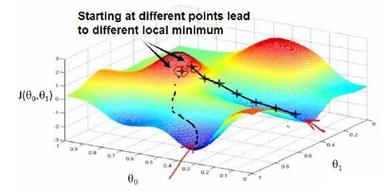
梯度下降背后的思想是:开始时我们随机选择一个参数的组合( θ0 , θ1 ,…, θn ),计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到找到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
批量梯度下降(batch gradient descent)算法的公式为:
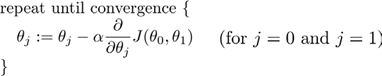
其中α是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
对线性回归运用梯度下降法

对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
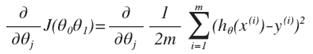
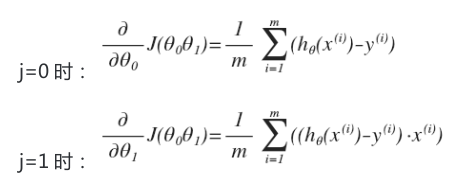
则算法改写成:
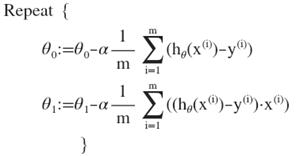















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









