




本文地址:https://www.ebpf.top/post/bpf_sched_ext_dive_into

在文章 Linus 强势拍板合入: BPF 赋能调度器终成正果中,我们回顾了 BPF 在调度器在合入社区过程中的历程,补丁 V7 已经在为合并到 6.11 做好了准备,后续代码仓库也变更为了 kernel git 地址,不出意外合并只是时间问题 。本篇博文会重点介绍 sched_ext 的实现原理,sched_ext 是一个由 Meta 和 Google 共同联合推出的可扩展调度器类,称之为 ext_sched_class 或 sched_ext,这种机制允许用户通过定义的 BPF 程序来实现调度类实现针对特定工作负载或场景的调度器策略优化。
Linux 进程调度器
进程调度器是操作系统中都是必不可少的部分。
一般来讲,CPU 时间片是多路复用到多个任务。调度器本质上做出如下决定(选择谁在哪里运行运行多长时间?):
- 任务选择:下一个运行哪个任务?
- CPU 核心选择:确定下一个运行任务运行在的哪些或者哪个 CPU 核心上。
- 时间片:选择的下一个任务运行多长时间?
针对单个任务而言当然是固定在特定的 CPU 集合上运行时间越长越好,但考虑到 CPU 时间是诸多任务复用,那么单个任务运行越久就越可能影响到系统中运行的其他任务,所以调度器需要从全局任务的视角来保障全部任务的运行高效性和公平性。做到全局最优,这是调度器复杂之所在。
此外,调度器可能希望充分利用多个 CPU 核心,因此其可以将任务分配给任何空闲的 CPU 核心。这种调度模式可能会增加整体 CPU 利用率,但更高的 CPU 利用率并不总是意味着更高的性能。当任务频繁地从一个 CPU 迁移到另一个 CPU 时,新分配的 CPU 的缓存需要重新预热,因此在任务下次调度时几乎没有机会重用缓存,导致性能下降。当系统具有多个缓存域(如 NUMA 和 AMD CCX 架构)时,缓存重新预热的成本会更高。
CFS 调度器
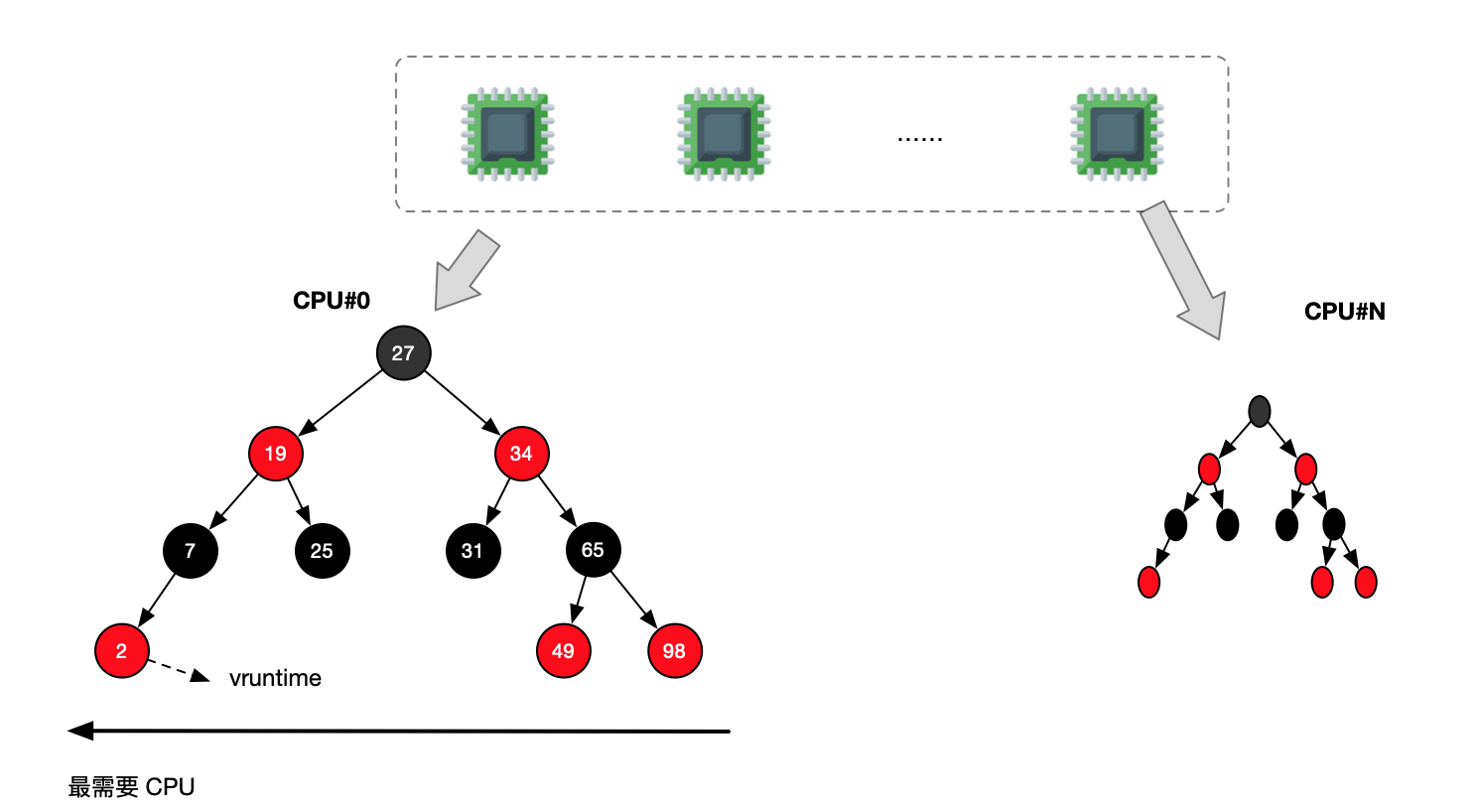
Linux 系统调度器从 2.6.23 版本(2007 年)开始就采用 CFS(Completely Fair Scheduler) 调度器,并且一直是主线内核的默认调度器。CFS 通过使用红黑树数据结构来管理进程,旨在提供完全公平的调度。更细节的资料可参考 Linux 进程管理 和 Linux CFS 调度器:原理、设计与内核实现(2023)。
CFS 调度器的目标是让每个任务尽量公平获得 CPU 资源:
- 任务选择:每个任务都会有一个虚拟运行时间 vruntime,CFS 选择的时候总会选择 vruntime 最小的进程,这就相对保障了公平性。
- 时间片:CFS 并不使用固定的时间片,根据任务的优先级和已使用的 CPU 时间进行综合动态调整。这样可以确保高优先级的任务获得更多的 CPU 时间,而低优先级的任务也不会被完全饿死。
CFS 采用红黑树实现进行优先级选择,红黑树是一种平衡二叉树,能够高效地插入、删除和查找任务:
EEVDF 调度器
CFS 调度器不强制执行调度截止时间,并且在许多情况下,延迟关键任务未能按时调度—这种延迟关键任务的调度延迟会导致高尾延迟。CFS 调度器在服务了 15 年后,于近期被淘汰。EEVDF(Earliest eligible virtual deadline first )调度器在 Linux 内核 6.6 版本(2023 年 11 月)中被引入作为新的默认调度器。EEVDF 由调度器的维护者 Peter Zijlstra 2023 年提交。EEVDF 调度器的设计基于一个来自 90 年代末的研究论文,旨在通过考虑进程的虚拟截止时间和公平性来优化调度决策
- 任务选择:每个任务都有一个虚拟截止时间,表示应该运行完成的时间,EEVDF 优先选择运行虚拟截止时间最早的任务运行。调度器按照任务优先级和已经获得的CPU时间来计算它们的虚拟截止时间,可以保证延迟敏感的进程能够及时得到CPU时间,而不会被其他进程抢占。
- 时间片:时间片的选择上和 CFS 类似,也是根据任务的优先级和已使用的 CPU 时间进行综合动态调整。
EEVDF 调度器的实现细节包括如何计算虚拟截止时间,如何维护一个按照虚拟截止时间排序的红黑树,如何处理进程的迁移和唤醒,以及如何与其他调度器类协作。结果显示,EEVDF 在一些场景下比CFS 有更好的表现,特别是在延迟敏感的进程较多的情况下,EEVDF可以显著降低调度延迟,提高响应速度,而不会牺牲吞吐量和能耗。
通用调度器的窘境
经过内核中的调度器从 CFS 演进到了 EEVDF,能够提升某些场景下延迟敏感调度任务,但内核调度器的目的是为了保障大多数工作负载(例如数据库、游戏、微服务)和大多数硬件平台(例如 x86、ARM、NUMA、非 NUMA、CCX 等)上通用并工作良好。调度器优化在某些工作负载和硬件组合中表现良好,而在其他工作负载和硬件组合中表现出不符合预期的退化并不罕见。为了避免这种性能回归错误,因此内核社区对更改调度器代码设定了很高的门槛。
采用针对特定工作负载/硬件组合的自定义调度器比使用通用调度器更有利。然而,实现和维护自定义调度器非常痛苦。这不仅是因为替换或自定义内核调度器具有挑战性,还因为自定义调度策略不太可能被上游接受,因此自定义调度器在长期内会带来沉重的维护负担。
sched_ext 是为了解决上述问题而提出的。它允许用户使用 BPF 编写自定义调度策略,而无需修改内核代码。你不需要为维护内核外的自定义调度器而苦恼。此外,BPF 提供了一个安全的内核编程环境。特别是,BPF 验证器确保你的自定义调度器没有内存错误或无限循环。此外,如果你的自定义调度器行为不当——例如未能在规定时间内调度任务(例如 30 秒),sched_ext 的内核部分会终止你的自定义调度器并回退到默认内核调度器(CFS 或 EEVDF)。
最后,但同样重要的是,你可以在不重新安装内核和重启服务器的情况下更新 BPF 调度器。在拥有数十万台服务器的大型数据中心中,这是一种魅力。
BPF 调度扩展器 sched_ext 实现机制
新增1: SCHED_EXT 调度类
调度器在内核中的实现通过调度类实现具体场景的功能,调度类可以理解为一个通用抽象结构,这在面向对象语言中通常称之为理解为基类。不同场景的调度实现通过不同的调度类来实现,具体的调度类实现调度类定义的函数,不同调度类有优先级概念。任务的对应的具体调度类由进程创建时默认设定或者通过函数 sched_setscheduler 调整。
SCHED_EXT 是一个非特权类,这意味着任何进程都可设置为 SCHED_EXT 。 SCHED_EXT 放置在优先级位于的 SCHED_IDLE 和 SCHED_NORMAL 之间。因此, SCHED_EXT 调度程序无法以阻止(例如)以 SCHED_NORMAL 运行的普通 shell 会话运行的方式接管系统。调度类的接口、调度器类和新增的 ext_sched_cls 的整体关系如下图所示:

新版本废弃 scx_bpf_switch_all() 函数: 早期版本有个神奇的增强函数 scx_bpf_switch_all(),用于将新创建出来的任务都会被添加到 scs_tasks 全局列表中,当用户定义的 BPF 调度器注册的时候,可以一键将非 dl_sched_cls/rt_shec_cls 等进程切换为 ext_sched_cls 的功能。详细参见移除 scx_bpf_switch_all。
新增2:eBPF 自定义调度器函数
在 SCHED_EXT 调度类实现中,增加了针对用户自定义扩展接口定义。 SCHED_EXT 类的函数实现中,定义了一组基于 eBPF 的扩展函数,以 enqueue_task_scx 为例,在运行过中会判断是否注册了对应的 sched_ext_ops 结构中的 runnable 接口(一般简称为 ops.runnable),如加载的 BPF 程序定义了该操作函数则调用执行,如果没有定义则继续原来的流程。

以 ext_sched_cls.enqueue_task_scx 函数实现为例:
static void set_next_task_scx(struct rq *rq, struct task_struct *p, bool first)
{
// …
/* see dequeue_task_scx() on why we skip when !QUEUED */
if (SCX_HAS_OP(running) && (p->scx.flags & SCX_TASK_QUEUED))
SCX_CALL_OP_TASK(SCX_KF_REST, running, p); // 检查是否注册了 sched_ext_ops.running 函数
clr_task_runnable(p, true);
// …
}
结构中的 ops.running 操作函数可以通过用户编写的 eBPF 程序实现。在官方样例代码 scx_simple 的初始化样例如下所示:
# tools/sched_ext/scx_simple.bpf.c
SCX_OPS_DEFINE(simple_ops,
.select_cpu = (void *)simple_select_cpu,
.enqueue = (void *)simple_enqueue,
.dispatch = (void *)simple_dispatch,
.running = (void *)simple_running, // <==== 指定编写的 eBPF 程序函数
// …
.name = "simple"
);
void BPF_STRUCT_OPS(simple_running, struct task_struct *p) // <== 实现 ops.running 函数
{
if (fifo_sched)
return;
if (vtime_before(vtime_now, p->scx.dsq_vtime))
vtime_now = p->scx.dsq_vtime;
}
通过扩展 BPF 程序结构的方式实现了用户自定义调度逻辑。
SCHED_EXT 调度类工作流程
调度队列 DSQ(Dispatch Queues)
为了适配调度器核心和 BPF 调度器,sched_ext 使用调度队列 DSQ(Dispatch Queues),调度队列既可以作为 FIFO 也可以作为优先级队列。
当前,内置的全局 DSQ 队列和 CPU 本地 DSQ 并不支持优先级功能,仅支持 FIFO 调度。
默认情况下,有一个全局 FIFO ( SCX_DSQ_GLOBAL ) 和 per-CPU 的本地 DSQ ( SCX_DSQ_LOCAL )。 BPF 调度程序可使用scx_bpf_create_dsq() 和 scx_bpf_destroy_dsq() 管理任意数量的 DSQ。
在内核样例代码中的初始化,实现用户自定义的队列样例代码如下:
# tools/sched_ext/scx_simple.bpf.c
#define SHARED_DSQ 0
s32 BPF_STRUCT_OPS_SLEEPABLE(simple_init)
{
return scx_bpf_create_dsq(SHARED_DSQ, -1);
}
在函数 simple_init 通过 scx_bpf_create_dsq 创建了一个 id 为 0 的 DSQ,第 2 个参数为 NUMA node 的 Id。用于后续内核任务的调度管理。
调度周期运行流程
当 CPU 就绪时会优先从本地选择任务,如果本地 DSQ 不为空,则选择第一个任务。否则,CPU 会尝试使用内置的全局 DSQ。如最后仍然没有产生可运行的任务,则调用 ops.dispatch() 进行调度或消费任务。
sched_ext 中的 BPF 调度器工作流程可从任务唤醒和 CPU 就绪两个维度进行分析,这仅给出核心流程示意图。

-
当任务唤醒时,
ops.select_cpu()是调用的第一个操作函数。这里主要有两个目的:
-
CPU 选择优化提示。
-
如目标 CPU 空闲,则唤醒所选目标 CPU。
-
ops.select_cpu() 操作函数返回的 CPU 是一个优化提示,并不具有约束力。实际的决定是在调度的最后一步做出的。但是,如果 ops.select_cpu() 选择的 CPU 与任务最终运行的 CPU 匹配,考虑到 CPU 基本的各种缓存,性能会略有提升。
选择 CPU 的副作用是将其从空闲状态唤醒。虽然 BPF 调度程序可使用辅助函数 scx_bpf_kick_cpu() 唤醒任何 CPU,但恰当地使用 ops.select_cpu() 可以更简单、更高效。
在操作函数 ops.select_cpu() 中调用内核函数 scx_bpf_dispatch() 可立即将任务分配到 DSQ。如调用函数 scx_bpf_dispatch() 时候设置了标志位 SCX_DSQ_LOCAL ,该任务将被调度到从 ops.select_cpu() 返回的 CPU 的本地 DSQ 。
上述理解可能有些抽象,这里给出 scx_simple 中 ops.select_cpu 函数的实现所示:
#tools/sched_ext/scx_simple.bpf.c
s32 BPF_STRUCT_OPS(simple_select_cpu, struct task_struct *p, s32 prev_cpu, u64 wake_flags)
{
bool is_idle = false;
s32 cpu;
cpu = scx_bpf_select_cpu_dfl(p, prev_cpu, wake_flags, &is_idle);
if (is_idle) {
scx_bpf_dispatch(p, SCX_DSQ_LOCAL, SCX_SLICE_DFL, 0); // 分支 1
}
return cpu; // 分支 2
}
此外,直接从 ops.select_cpu() 调度将导致跳过 ops.enqueue() 回调。
请注意,调度程序核心将忽略无效的 CPU 选择,例如,如果它超出了任务允许的 cpumask 范围。
-
如果没有走优先调度分发(即上述代码分支 1),在选择选择目标 CPU ,后续会调用
ops.enqueue()(代码分支2)。ops.enqueue()可以做出以下决定之一:-
通过分别使用
SCX_DSQ_GLOBAL或SCX_DSQ_LOCAL调用scx_bpf_dispatch()将任务分派到全局或本地 DSQ。 -
通过使用小于 2^63 的 DSQ ID 调用
scx_bpf_dispatch(),立即将任务分派到自定义 DSQ。 -
在 BPF 端对任务进行排队。
# tools/sched_ext/scx_simple.bpf.c /* * Built-in DSQs such as SCX_DSQ_GLOBAL cannot be used as priority queues * (meaning, cannot be dispatched to with scx_bpf_dispatch_vtime()). We * therefore create a separate DSQ with ID 0 that we dispatch to and consume * from. If scx_simple only supported global FIFO scheduling, then we could * just use SCX_DSQ_GLOBAL. */ #define SHARED_DSQ 0 void BPF_STRUCT_OPS(simple_enqueue, struct task_struct *p, u64 enq_flags) { if (fifo_sched) { // 针对定义队列 SHARED_DSQ 进行顺序分发 scx_bpf_dispatch(p, SHARED_DSQ, SCX_SLICE_DFL, enq_flags); } else { // 针对定义队列 SHARED_DSQ 进行优先级分发 u64 vtime = p->scx.dsq_vtime; /* * Limit the amount of budget that an idling task can accumulate * to one slice. */ if (vtime_before(vtime, vtime_now - SCX_SLICE_DFL)) vtime = vtime_now - SCX_SLICE_DFL; scx_bpf_dispatch_vtime(p, SHARED_DSQ, SCX_SLICE_DFL, vtime, enq_flags); }
-
-
当 CPU 就绪时(可调度),首先查看其本地 DSQ。如果本地 DSQ 为空,则它会查看全局 DSQ。如果仍然没有要运行的任务,则调用
ops.dispatch(),可调用以下两个函数来实现任务派送到本地 DSQ。-
scx_bpf_dispatch()函数可将任务分派给 DSQ。可以使用任何目标 DSQ -SCX_DSQ_LOCAL、SCX_DSQ_LOCAL_ON | cpu、SCX_DSQ_GLOBAL或自定义 DSQ。虽然当前无法在持有 BPF 锁的情况下调用scx_bpf_dispatch(),但这一问题正在开发中并将得到支持。scx_bpf_dispatch()安排调度而不是立即执行。最多可以有ops.dispatch_max_batch个待处理任务。 -
scx_bpf_consume()将任务从指定的非本地 DSQ 转移到调度的 DSQ。持有任何 BPF 锁时无法调用此函数。scx_bpf_consume()在尝试使用指定的 DSQ 之前刷新挂起的已分派任务。# tools/sched_ext/scx_simple.bpf.c void BPF_STRUCT_OPS(simple_dispatch, s32 cpu, struct task_struct *prev) { scx_bpf_consume(SHARED_DSQ); }
-
-
ops.dispatch()返回后,如果本地 DSQ 队列中已有任务,则 CPU 运行第一个任务。如果为空,则执行以下步骤:-
尝试消费全局 DSQ。如果成功,则运行该任务。
-
如果
ops.dispatch()已分派任何任务,请重试 #3。 -
如果前一个任务是 SCX 任务并且仍然可以运行,则继续执行它(参见
SCX_OPS_ENQ_LAST)。 -
继续闲置。
-
请注意,BPF 调度程序始终可以选择立即在 ops.enqueue() 中分派任务。如果仅使用内置 DSQ,则无需实现 ops.dispatch() ,因为任务永远不会在 BPF 调度程序上排队,并且本地和全局 DSQ 都会自动使用。
scx_bpf_dispatch() 在目标 DSQ 的 FIFO 上对任务进行排队。使用 scx_bpf_dispatch_vtime() 作为优先级队列。 SCX_DSQ_LOCAL 和 SCX_DSQ_GLOBAL 等内部 DSQ 不支持优先级队列调度,必须使用 scx_bpf_dispatch() 调度。有关详细信息,请参阅 tools/sched_ext/scx_simple.bpf.c 中的函数文档和用法。
切换到 sched_ext
CONFIG_SCHED_CLASS_EXT 是启用 sched_ext 的配置选项, tools/sched_ext 包含示例调度程序。在编译内核的时候,应启用以下配置选项才能使用 sched_ext:
CONFIG_BPF=y
CONFIG_SCHED_CLASS_EXT=y
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT=y
CONFIG_DEBUG_INFO_BTF=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_PAHOLE_HAS_SPLIT_BTF=y
CONFIG_PAHOLE_HAS_BTF_TAG=y
当前最新的 Patch V7,代码仓库代码地址为 https://git.kernel.org/pub/scm/linux/kernel/git/tj/sched_ext.git/。 sched_ext 仅在 BPF 调度程序加载并运行时使用。
如显式地将任务的调度策略设置为 SCHED_EXT ,其将被视为 SCHED_NORMAL 并由 CFS 调度,直到加载 BPF 调度程序。加载时,此类任务将切换到 sched_ext 并由 sched_ext 调度器程序进行调度。
终止 sched_ext 调度程序、触发 SysRq-S 或检测到任何内部错误(包括停止的可运行任务)都会中止 BPF 调度程序并将所有任务恢复回 CFS。
# make -j16 -C tools/sched_ext
# tools/sched_ext/scx_simple
local=0 global=3
local=5 global=24
local=9 global=44
local=13 global=56
local=17 global=72
^CEXIT: BPF scheduler unregistered
BPF 调度器的当前状态可以确定如下:
# cat /sys/kernel/sched_ext/state
enabled
# cat /sys/kernel/sched_ext/root/ops
simple
tools/sched_ext/scx_show_state.py 是一个 drgn 脚本,它显示更详细的信息:
# tools/sched_ext/scx_show_state.py
ops : simple
enabled : 1
switching_all : 1
switched_all : 1
enable_state : enabled (2)
bypass_depth : 0
nr_rejected : 0
如编译时候设置了 CONFIG_SCHED_DEBUG 选项,则可按如下方式确定任务是否在 sched_ext 上运行:
# grep ext /proc/self/sched
ext.enabled : 1
总结
本文尝试从内核调度器 CFS/EEVDF、schd_ext 实现机制和工作流程给出了简单介绍,结合内核中的 scx_simple BPF 调度器给与了具体说明,如果你对 sched_ext 的实现和应用感兴趣,你可以通过编译内核的方式来对 tools/sched_ext/ 目录下实现的调度器进行学习和实验,相信你可以得到更多的发现和调度的启示。相信,在 sched_ext 合入到内核代码后,这将为我们的测试和实现带来更多的便利。
本人水平有限,如有错误欢迎批评指正。


















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









