






一、前言
今年年初,宋宝华老师发表了一篇对2023年内核技术总结的文章《熠熠生辉 | 2023 年 Linux 内核十大技术革新功能》。有兴趣的伙伴可以点击蓝色字体链接回顾。
文章提及的10个技术中,与CPU任务调度器核心相关的内容,一共有两个,分别是可扩展调度类以及EEVDF调度算法。EEVDF调度算法的大名,相信大家并不陌生,它对统治内核任务调度多年的CFS调度策略发起了变革。CFS调度策略自Linux 2.6引入以来,其核心算法几乎没有任何变动,地位极其稳固,但随着汽车行业、手机行业、各类视觉增强设备技术的发展,我们对任务调度的公平性有了更高的需求,或者说,对何为公平有了新的理解。公平不仅仅包含时间片分配的公平,也包含调度延迟的公平,很遗憾,传统的CFS调度策略很难满足新的需求。而EEVDF调度算法在Linux 6.6内核的正式引入,给大家带来了解决此类需求的可能性。如此看来,确实能占据“十大技术”一席之地。那么,另一项核心技术“基于eBPF的sched_ext调度类扩展”,乃何许人也,竟能与EEVDF齐名,难道是内核调度界的“北乔峰,南慕容”?我们不着急下定义,先看看sched_ext究竟是何物。
二、sched_ext调度类介绍
2.1 可扩展调度类sched_ext的基本框架
Ext对应的英文单词为“Extensible”,意为可扩展的。开发者Tejun Heo通过整整34笔的PatchSets,提供了一个支持eBPF程序修改调度策略的调度类。其核心目的有三个:
A.让开发者更易于实验和探索新的调度策略,免去编译完整内核镜像的成本;
B.通用调度策略难以满足的特殊应用场景,通过该机制可以实现深度定制化;
C.快速的终端调度器部署。
整体的框架如下图所示。在源码中,sched_ext可扩展调度类的使用,需要配置CONFIG_SCHED_CLASS_EXT,如果希望接入组调度的一些简单逻辑,则需要额外打开配置项CONFIG_EXT_GROUP_SCHED。
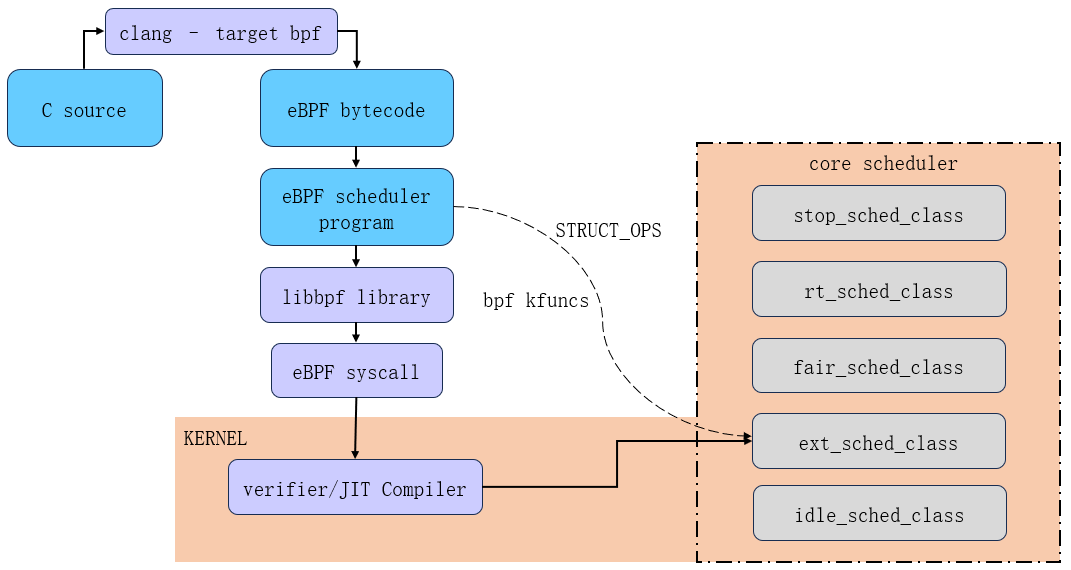
上图可以看出,sched_ext的核心实现,由bpf scheduler和core scheduler组成。core scheduler部分在内核态增加新的ext_sched_class调度类,提供与其它已有调度类相似的能力(如出入队、抢占、任务选取),区别在于,它增加了不少回调以及与用户态交互的ebpf接口集合,方便用户态自行定制调度策略,也就是说,即便我们没有给它做任何定制,它依然拥有一套基础的调度规则。这一部分涉及的文件如下:
include/linux/sched/ext.h // ext调度类的ops接口声明以及调度类核心结构体实现
kernel/sched/ext.h // ext调度类的普通功能接口及标志位声明
kernel/sched/ext.c // ext调度类的核心接口实现
bpf scheduler部分则可以细分两个部分,第一部分与其它BPF程序并无差别,即提供基础的bpf调度程序加载注册功能;第二部分是其核心部分,用于在用户态借助BPF STRUCT_OPS特性(支持通过BPF程序实现特殊的kernel侧函数指针),实现真正的客制化策略。STRUCT_OPS特性早在5.4内核引入,尽管最初目的是将TCP 拥塞控制算法迁移到BPF程序中,但其更大的意义在于为微内核演进提供一套较为完善的基础设施。这一部分涉及的文件如下(以central scheduler为例说明):
tools/sched_ext/scx_central.c // central scheduler的加载注册及监控部分实现
tools/sched_ext/scx_central.bpf.c // central scheduler的具体策略实现
2.2 sched_ext调度类的扩展支持接口
在文件include/linux/sched/ext.h中,对关键结构体struct sched_ext_ops做了定义,每部分ops接口都有详细说明,部分关键接口展示如下:
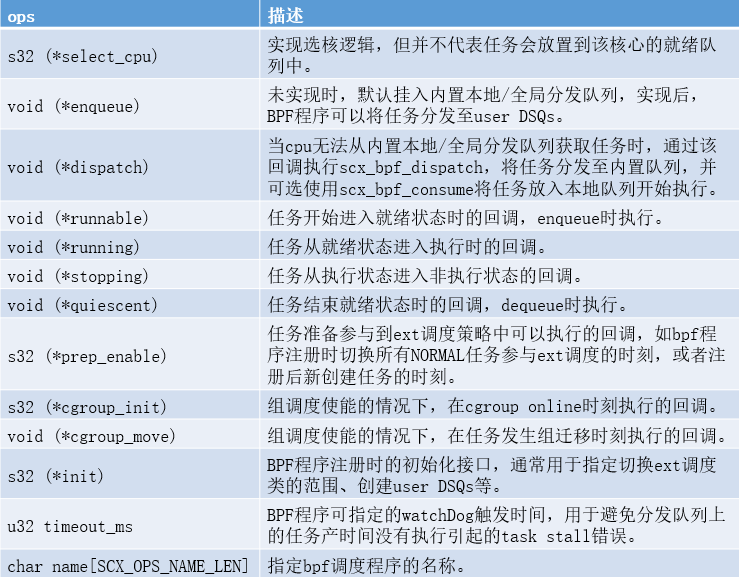
这部分需要配合sched_ext的core scheduler实现来看,我们将在下一章节说明。这里先以(*select_cpu)为例,它为具体任务线程选择运行的CPU,在sched_ext的core scheduler部分,ext调度类任务的选核实现如下:

这里可以留意到,select_task_rq_scx()通过SCX_HAS_OP宏判断*select_cpu是否有注册回调,进而决定是否采用bpf scheduler实现的策略,如果没有注册,则执行scx_select_cpu_dfl(),走ext调度类的默认选核逻辑。这里对bpf程序的ops维护,是通过static-key机制来完成的,内核通过以下数组查找对应的ops回调是否有注册:

数组的下标由函数指针成员在struct sched_ext_ops结构体中的偏移量决定,对应位置的key值代表该ops有没有实现回调,这个初始化是在bpf程序注册的时候判断的。

存在回调的情况下,通过SCX_CALL_OP_TASK_RET宏来执行具体的回调接口。像这样的逻辑,在ext调度类中比比皆是,ext调度类通过在各个关键逻辑中引入ops,实现对调度策略的自由定制。
2.3 sched_ext的核心数据结构
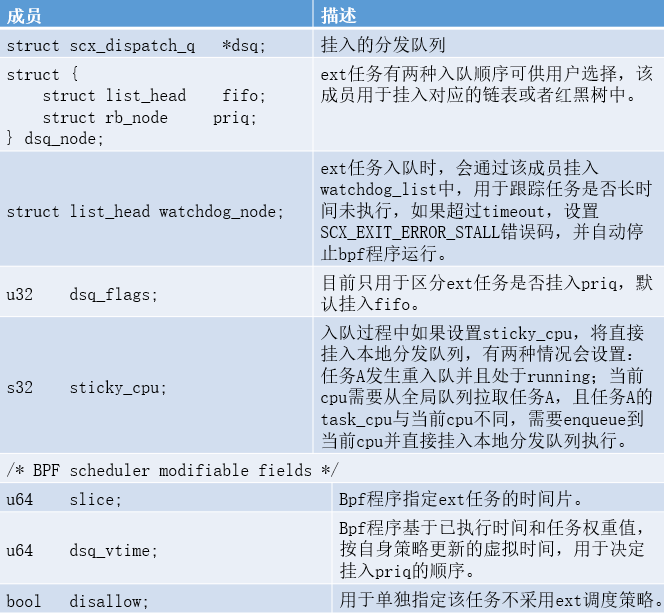
内核每个调度类任务都有各自的调度实体数据结构,ext任务对应的数据结构为struct sched_ext_entity,关键成员信息如下:
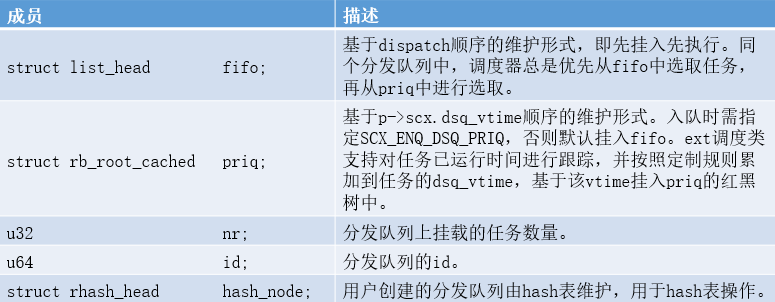
ext调度类采用分发队列的形式维护每个任务,其核心数据结构struct scx_dispatch_q如下:
2.4 sched_ext调度类的内核调度逻辑
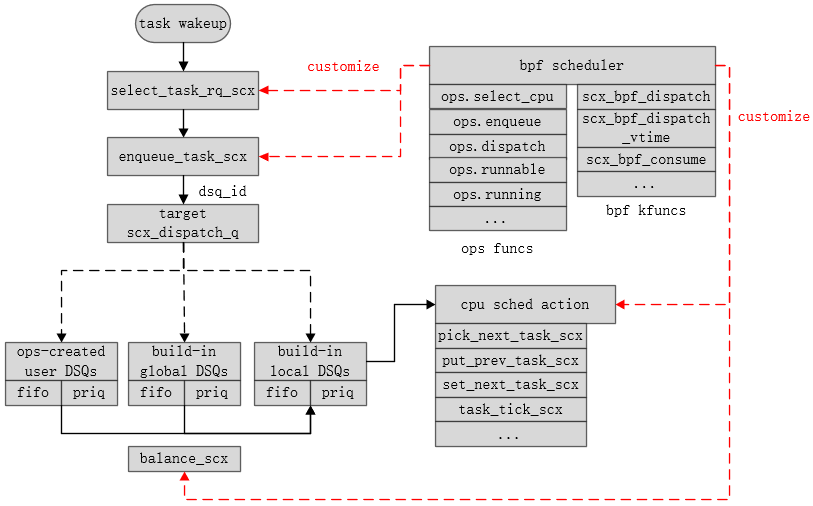
之前说过,ext调度类存在core scheduler部分,它可以在不依赖bpf scheduler实现扩展策略的情况下,完成调度功能,它本身就是在内核新增一个调度类,自然具备其它调度类的基础能力(存在与之对应的sched_entity结构,支持出入队、执行退出、抢占等调度逻辑)。从前面的ops扩展接口中,我们也可以学习到一个调度类是如何影响具体任务的整个调度过程。
2.4.1 调度类处理
既然是一个新增的sched_class,我们必然会关心它在诸多调度类中的优先级如何。ext_sched_class的优先级定义如下:

可见,ext调度类的优先级并不高,Android移动端大部分线程的调度类,都集中在rt_sched_class以及fair_sched_class,也就是说,ext调度类在当下的调度体系中,并不占据优势。如果你也这么想,那就错了,在sched_ext的实现中,fork出来的线程会被加入到scx_tasks的全局链表中,当bpf scheduler注册时,如果指定switch_all,会遍历该链表,将所有非dl_sched_class/rt_sched_class的任务,统一切换成ext_sched_class调度类,并且,在sched_ext生效期间,新增加的任务也适用此逻辑。
Documentation/scheduler/sched-ext.rst

2.4.2 队列维护
不同于传统调度类采用percpu-runqueues的形式维护就绪任务,ext调度类采取的是分发队列。
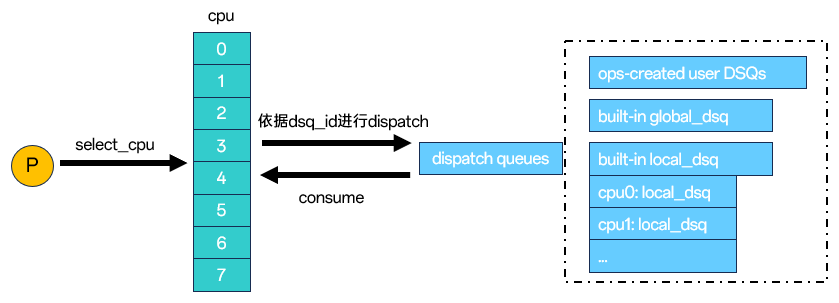
在ext调度体系中,我们可以分成两大类分发队列,即build-in DSQs和ops-created user DSQs,其中,build-in DSQs又可以细分是local(本地)还是global(全局)类型,local_dsq由每个cpu各自维护一个,global_dsq内置默认数量为1;ops-created user DSQs则是通过bpf程序创建,由rhashtable维护。
在各个调度接口中,内核统一采用一个64bit的dsq_id成员,来标识任务需要挂入的分发队列,其含义如下:

Bit 63:1代表build-in类型,0代表ops-created user类型,在指定build-in类型的情况下,“V”为1代表内置默认的global_dsq,为2代表local_dsq,此时任务会直接挂入选择的rq中。
Bit 62:1代表local-on,此时”V”区代表具体的cpu号,该配置用于指定任务放置到目标local cpu;
Bit 61 - Bit 32:预留区域。
Bit 31 - Bit 0:如前面所提,根据“B”区和“L”区的配置,有不同的含义。
传统的percpu-runqueues,任务唤醒选核后,将放置在该rq上等待执行,如果没有诸如负载均衡之类的动作发生,该任务后续就在rq上运行。
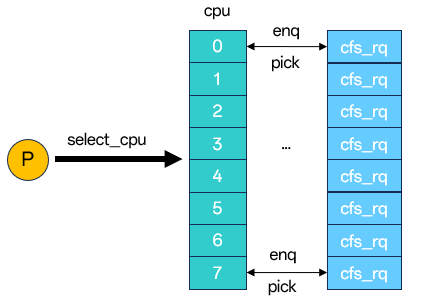
而ext调度类采取的分发队列,则允许任务选核后,挂入到一个全局队列中,而不是直接挂入到传统的rq(当然,通过指定LOCAL标志位,也可以直接放入到对应rq的本地队列中),这个过程叫做“dispatch”,之后在适当的调度点,从全局队列中选取任务放置到本地分发队列中,这个过程叫做“consume”,当cpu需要执行任务时,直接从本地分发队列中选择任务运行。
我们很难直接将这两种维护方式分个高低,得看实际的应用场景。他们的优点和缺点都非常明显。
l同步开销:percpu-runqueues形式下,任务选择完cpu后,只需要持目标cpu的rq锁即可,而分发队列的模式下,任务在持有选取cpu的rq锁之后,仍然需要持分发队列的保护锁,并且该锁可能是全局的锁,同步开销会更大。
l负载均衡:移动平台任务的负载形式变化相对频繁,percpu-runqueues基于任务负载的选核,很有可能造成一段时间后,随着各个就绪队列上任务的此消彼长,各个cpu的负载极易变得不均衡,因此需要考虑各种均衡策略(periodic balance|nohz idle balance|new idle balance),这又是一笔不小的开销。但如果采用分发队列的形式,我们可以选择将任务分发到全局队列中,从全局的视角让cpu去消费任务,当某个cpu上的任务执行完成,再从全局队列中拿取,避免各个cpu负载不均衡的情况发生。
l负载跟踪:采用percpu-runqueues的情况下,cpu可以观察到己方就绪队列的负载情况,可以更好的决策接下来的频点控制,但在全局分发队列的形式下,cpu是无法提前知道,自己将会从分发队列上拿到哪些任务执行。
2.4.3 调度时机
传统的fair调度类,一般存在两种调度点,一个是任务唤醒时触发,另一个是周期性tick中断到来时触发。
对于ext调度类而言,更高优先级的调度类唤醒时,仍然可以对当前执行的ext任务发起唤醒抢占,ext任务也可以对更低优先级的调度类发起,但由于没有实现ext_sched_class->check_preempt_curr接口,因此ext调度类任务之间,并不存在唤醒抢占机制。在tick中断到来时,ext调度类只有在当前任务的scx.slice,即时间片耗尽时,才会发生切换。
2.4.4 小结
从本节的介绍中,我们可以知道ext调度类任务的大致运作机制,bpf scheduler拥有充足的能力对多个环节进行定制,具备极高的自由度,如下图所示:
2.5 sched_ext调度类的bpf scheduler应用
在tools/sched_ext/目录底下,有开发者提供的可扩展调度类应用示例,供大家学习。在这里面,我们发现作者对示例Central scheduler加了这么一行介绍,那我们就看看它是怎么定制的用户态调度策略。
“This scheduler is designed to maximize usage of various SCX mechanisms.”
Central scheduler的核心设计点在注释中已经说明清楚,有3个要点:
A.通过一个central cpu用来做调度决策,当其他核心需要任务执行时,必须通过central cpu来完成分发。
B.支持Tickless操作,任务采用无限制的时间片,不需要内核发送TICK来进行任务轮转。
C.Kthread无条件发起抢占,其他任务的抢占则通过kick目标CPU实现(达成轮转目的)。
Central scheduler整体框架如下图展示。我们这里对其扩展的ops进行详细说明,看官们可以更好地了解可扩展调度类的作用:
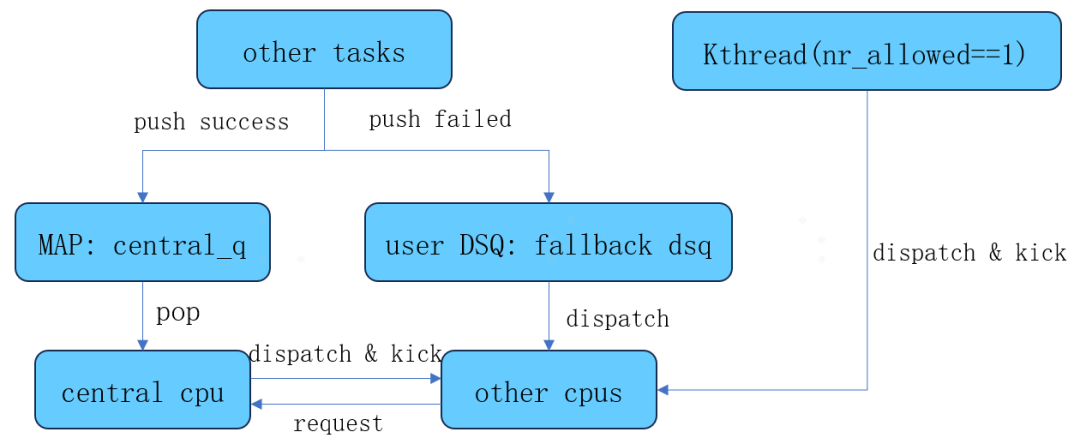
A.ops.init
该调度程序注册时,会进行以下3个动作:
(1)将所有NORMAL类型的任务,统一切换成EXT调度类;
(2)通过scx_bpf_create_dsq接口,创建一个ops-created user类型的全局分发队列fallback dsq;
(3)启动一个1ms的周期性timer,去检测各个cpu的任务执行情况。首先对非central的cpu进行检测,当cpu的执行任务耗尽用户指定的时间片,则对该cpu发起一次带SCX_KICK_PREEMPT flag的kick,清空当前正在执行任务的slice,并强制做一次resched,调用dispatch接口。之后再固定对central cpu发起一次带SCX_KICK_PREEMPT flag的kick。
B.ops.select_cpu
固定返回用户指定的central cpu。
C.ops.enqueue
对于固定单核的Kthread,直接指定dsq_id为SCX_DSQ_LOCAL,将其放入内置local dsq中,并且指定enq_flags为SCX_ENQ_PREEMPT,让Kthread可以抢占当前的scx任务;对于其它scx任务,优先将其push到BpfMap类型数据central_q中,该Map最多可存储4096个数据,如果central_q已经存满,则将其分发至fallback dsq中,如果该任务当前未执行,则指定SCX_KICK_PREEMPT,对central_cpu发起一次kick,触发resched,通知central_cpu进行一次dispatch。
D.ops.dispatch
central scheduler的核心逻辑,cpu发生sched时,如果built-in的本地分发队列以及built-in的全局分发队列都没有任务时,会执行该回调。
当非central cpu触发resched时,首先会考虑从fallback dsq中获取任务进行consume,如果该dsq中没有任务,则kick central cpu,请求分配任务。
当central cpu触发resched时,由于它负责其他核心的调度决策,因此,会先确认其他cpu是否发起请求,如果存在request cpu,就会从BpfMap类型数据central_q中获取任务,将其分发至request cpu的本地分发队列中,并对request cpu发起一次kick;之后再为自己考虑,从fallback dsq或者central_q中获取任务执行。
它的设计其实很奇葩,比如没有权重的思想,所有任务一视同仁,又比如在central核心上执行过多的非用户态逻辑,对其上执行的任务很不友好。即便如此,它也为我们展示了可扩展调度器的丰富能力。
三、结语
从设计理念来看,EEVDF属于内部变革,sched_ext则是另起炉灶。可惜的是,EEVDF已然带入6.6内核,而sched_ext仍然没有被社区接受,并受到maintainer的强烈反感。
https://lore.kernel.org/lkml/20230726091752.GA3802077@hirez.programming.kicks-ass.net/
它的优点在于可扩展性,缺点也在于可扩展性,其本身的补丁只是单纯提供一套基础框架以及基本的调度策略,并没有对内核调度器产生实际价值的内容,各家借助这样的机制可以开发出适用于自己环境的调度器,提升产品竞争力,但不利于社区提倡技术分享以及开源。
我们仍然对其报以期待,因为调度器面临的工作负载千变万化,同样的,我们也需要千变万化的调度器来应对各种需求。
四、参考文章
Sched Ext sourcecode: https://github.com/sched-ext/sched_ext/tree/sched_ext
The extensible scheduler class: https://lwn.net/Articles/922405/
Kernel operations structures in BPF: https://lwn.net/Articles/811631/
Introduce BPF STRUCT_OPS: https://lwn.net/Articles/809092/
eBPF Documentation: https://ebpf.io/what-is-ebpf/
BPF Kernel Functions (kfuncs): https://docs.kernel.org/bpf/kfuncs.html
eBPF assembly with LLVM: https://qmonnet.github.io/whirl-offload/2020/04/12/llvm-ebpf-asm/
往
期
推
荐
Linux Large Folios大页在社区和产品的现状和未来

长按关注内核工匠微信
Linux内核黑科技| 技术文章| 精选教程


















 2512
2512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











