






团队名称
西南石油大学:龙井湖
问题陈述
编写⼀个基于oneAPI的C++/SYCL程序来执行矩阵乘法操作。需要考虑大尺寸矩阵的乘法操作以及不同线程之间的数据依赖关系。通常在实现矩阵乘法时,可以使用块矩阵乘法以及共享内存来提高计算效率。
正常没有任何处理的矩阵乘法就如下图,会有三层循环,所需的操作数n=rows_A*clos_B*cols_A,计算成本是很大的。

项目简介
提高矩阵乘法效率的主要核心是并行计算。矩阵分块乘法将我们最后将要得到的矩阵按照一个给定的大小进行分块,每一个块的结果运算都是独立的,只需要从要相乘的两个矩阵中获取相应数据计算即可得出结果,每个块之间不会相互影响结果,所以可以在GPU上并行计算执行这些矩阵块,从而可以实现并行矩阵乘法,提高矩阵乘法的效率,缩减运行时间。
软硬件设备
使用英特尔oneAPI Developer Cloud平台
[opencl:cpu:0] Intel(R) OpenCL, Intel(R) Xeon(R) E-2176G CPU @ 3.70GHz 3.0
[2023.16.7.0.21_160000] [opencl:gpu:1] Intel(R) OpenCL HD Graphics, Intel(R) UHD Graphics P630 [0x3e96] 3.0 [22.43.24595.35]
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) UHD Graphics P630 [0x3e96] 1.3 [1.3.24595]
实现方案
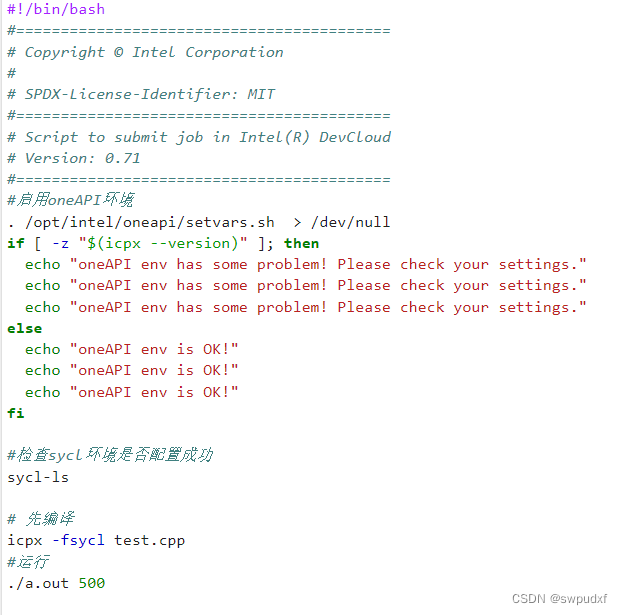
使用qsub命令提交run.sh到指定队列完成任务
run.sh内容:(./a.out后紧接着的是矩阵的宽度)
我们将整个输出图像分为N/10份*N/10份 每份的大小是10*10点 我们每个工作组内的内容就是计算10*10个输出点。利用item.get_group可以得到我们工作组在全局范围内的一个索引,这样我们就可以将i和j对应到整个图像上的点位

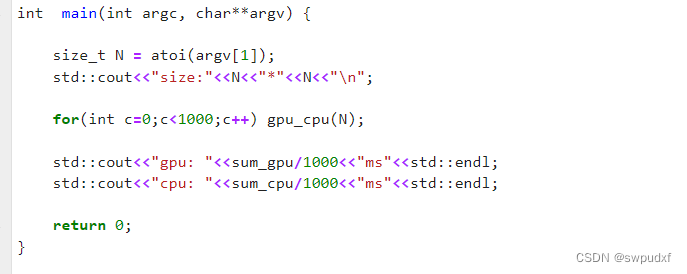
然后输入大小N*N的数组进行1000次初始化以及操作得到的合计时间再除以1000得到平均时间
时间效益
我们做了7组数据分别对应矩阵宽度为10、50、100、300、500、800、1000 得到.o文件显示数据汇总得到柱状图:
横坐标为图像宽度 纵坐标为时间使用(ms) 为了对比清晰 我们将数据分为了两组 一组为10、50、100
一组为300、500、800、1000


对于较大的矩阵(如1000*1000),GPU 相对于 CPU 显著提高了计算速度。
随着矩阵大小的减小,GPU 的相对优势减小,而在非常小的矩阵(如10*10)上,GPU 的计算时间甚至可能比 CPU 更长。这是因为 GPU 在处理小规模问题时可能受到启动和传输开销的影响。
总体而言,GPU 在大规模矩阵上的计算速度相对于 CPU 更快。然而,在处理小规模问题时,GPU 的优势可能不够明显。
总结
我们在解决作业一时使用到了Intel® oneAPI Base Toolkit里的DPC++编译器,并且使用sycl编程模型,在代码中我们使用了sycl的队列,缓冲区,访问器,以及使用parallel_for实现并行计算。并且openapi提供的标准API如DPC++ 这使得开发者可以使用熟悉的 C++ 语言来编写代码,而无需为不同硬件架构学习不同的编程语言,这是一个非常友好的一个开发工具。
github链接:GitHub - dxf2003/matrix-multiplication: Programming parallel matrix multiplication using sycl















 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









