







写这篇博客之前,不知道该起个什么名字,因为我想学习SVM的知识,以便和前一篇博客有衔接,但是这篇文章里面实际上并没有多少是介绍SVM的,反而有一点是介绍MLC的,而且MLC介绍的也不深入。权且叫做学习SVM前的数学预热吧。
废话少说,进入正题。
条件概率:
设A,B是两个事件,且P(A)>0,称

为在事件A发生的条件下事件B发生的条件概率。
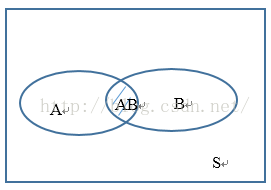
可以形象地理解为图中阴影区AB占A的面积的比例。
在SVM或者MLC等分类方法的学习过程中经常碰到先验概率和后验概率两个概念,为了理解这两个概念,则首先要知道全概率公式和贝叶斯(Bayes)公式(看到贝叶斯公式,就有一种很熟悉的感觉,其实它就一直躺在我们的数学课本中,只不过把它忘记了)。
在介绍全概率公式个贝叶斯公式之前,首先要介绍样本空间的划分的定义。
定义:设S为试验E的样本空间,B1,B2,…,Bn为E的一组事件,若事件满足:
1) BiBj=Ø,i≠j, i,j=1,2,3,…,n
2) B1∪B2∪…∪Bn=S
则成B1,B2,…,Bn为样本空间S的一个划分。

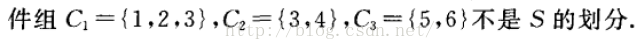
那么,我们在此基础上引出全概率公式的定义:
假设A为试验E的事件,B1,B2,…,Bn为样本空间S的一个划分,且P(Bi)>0,则:
P(A)=P(A|B1)P(B1)+P(A|B2)P(B2)+…+ P(A|Bn)P(Bn)
为全概率公式。
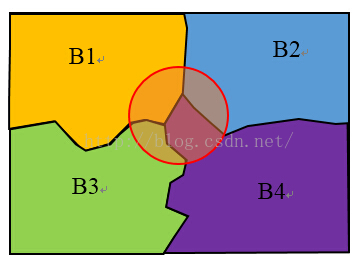
|
对应的,贝叶斯公式则为:
|
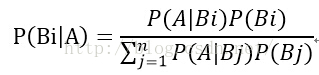
那么,如何形象地理解贝叶斯公式呢?还是以上图为例。分子部分可以理解为根据事件A占Bi的比例来求A与Bi公共部分的“面积”。分母部分则为红色圆所占的“面积”。而P(Bi|A)则可理解为在圆中,Bi的面积所占的比例。
现在,结合一个数学课本上的例子阐明先验概率和后验概率的定义。
例子:对以往的数据分析结果表明,当机器调整得良好时,产品的合格率为98%,而机器发生故障时,其产品的合格率为55%。机器每天早上启动时,其调整良好的概率为95%,试求已知某日早上第一件产品是合格时,机器调整良好的概率是多少?
解: 设A为事件“产品合格”,B为事件“机器调整良好”。已知P(A|B)=0.98, ,P(B)=0.95, ,所需求的概率为P(B|A),由贝叶斯公式:
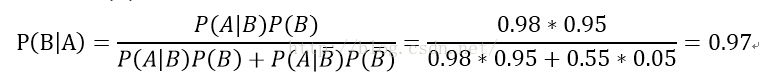
上面题中由以往数据分析得到的机器良好概率0.95为先验概率,而0.97是在生产第一件产品之后得到的修正概率,即为后验概率。
现在,结合MLC来说明条件概率以及先验概率的简单用途[W用1] 。假设影像只有一个波段,如果A类地物有30个像素作为训练样本,B类地物也有30个像素作为训练样本。(不同类型地物选用相同数量的像素作为训练样本),像元灰度值在0-255之间。
正态分布概率密度函数的确定取决于期望和方差。这里我们用训练样本像元灰度值的期望和方差作为这类地物灰度值的概率密度函数的期望和方差。
条件概率的公式为 p(y|x)=(p(x|y)*p(y))/p(x) (1)
这里,x代表像元灰度值,y代表像元类型,比如p(A|100)=0.3,p(B|100)=0.7,当灰度值为100时,像元为A类地物的概率为0.3,当灰度值为100时,像元为B类地物的概率为0.7.
p(x|y)由样本值获得,见概率密度分布图。p(y)为先验概率,指某种地物类型在整体中的比例(一般取平均,两类地物的时候为1/2,三类地物的时候为1/3)。p(x)为像素灰度取值的概率,当像元在0-255之间取值的时候,p(x)为1/256,这两个都是确定项。因此p(y|x)取决于p(x|y),后者可由概率密度分布曲线获得(根据概率密度分布曲线,如何获得P(x|y)?,后面再解答[W用2] )。
“最大”体现在,当x的取值确定后,对应地物类型y的概率p(y|x)最大时,就归为哪种地物。
1>当波段数大于等于2的时候,x为一个矢量,比如x=(100,150,50),p(x|y)是条件联合概率密度。
2>由于地物未必是平均分配的,可以对公式(1)进行迭代计算,将第一次计算的结果p(y1)作为第二次的先验概率。
3>当影像数据服从正态分布或联合正态分布的时候,最大似然法是最好的;但是如果数据不服从正态分布,这种方法未必合适。
至此,对MLC的原理应该有一个简单的了解。但是,在遥感影像分类中,往往是多个波段参与分类,那么我们在进一步介绍MLC之前,还得继续补充一点数学知识。















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









