







https://github.com/nndl/solutions
2 机器学习概述
习题2-1 分析为什么平方损失函数不适用于分类问题.


写错了,是 x y ( y − σ ) σ ( 1 − σ ) xy(y-\sigma)\sigma(1-\sigma) xy(y−σ)σ(1−σ)
- 从损失函数上限、距离角度
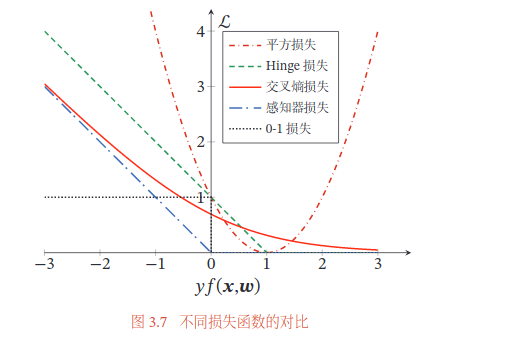
直观上,对特定的分类问题,平方差的损失有上限(所有标签都错,损失值是一个有效值),但交叉熵则可以用整个非负域来反映优化程度的程度。
分类问题中的标签,是没有连续的概念的。1-hot作为标签的一种表达方式,每个标签之间的距离也是没有实际意义的,所以预测值和标签两个向量之间的平方差这个值不能反应分类这个问题的优化程度。
- 从分布的角度
平方损失函数意味着模型的输出是以预测值为均值的高斯分布,损失函数是在这个预测分布下真实值的似然度
※ 最小化平方损失函数本质上等同于在误差服从高斯分布的假设下的极大似然估计,然而大部分分类问题的误差并不服从高斯分布。
- 从梯度的角度
※ 而且在实际应用中,交叉熵在和Softmax激活函数的配合下,能够使得损失值越大导数越大,损失值越小导数越小,这就能加快学习速率。然而若使用平方损失函数,则损失越大导数反而越小(看后面的图),学习速率很慢。
还有个原因应该是softmax带来的vanishing gradient吧。预测值离标签越远,有可能的梯度越小。李龙说的non-convex 问题 ,应该是一种提现形式。
习题2-2 线性回归的样本权重

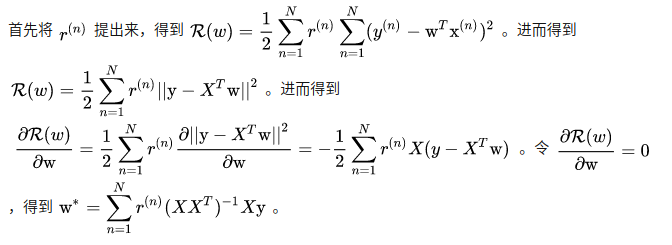
- 权重 r ( n ) r^{(n)} r(n)的作用:
为每个样本都分配了权重,相当于每个样本都设置了不同的学习率,每个样本的重视程度不一样
局部线性回归可以实现对临近点的精确拟合同时忽略那些距离较远的点的贡献,即近点的权值大,远点的权值小,k为波长参数,控制了权值随距离下降的速度,越大下降的越快。越小越精确并且太小可能出现过拟合的问题。
但局部线性回归不会得到一条适合于全局的函数模型,在每一次预测新样本时都会重新的确定参数,从而达到更好的预测效果。当数据规模比较大的时候计算量很大,学习效率很低。
习题2-3 X X T XX^T XXT的秩


2-4 结构风险最小化 最小二乘估计 岭回归

2-5 最大似然估计与最小二乘估计在标签服从高斯分布时等价

2.6 最大似然估计与最大后验估计

2.9 欠拟合→高偏差,过拟合→高方差

2.11 N-gram
假设以每个字字为基本单位,一元:|我|打|了|张|三|#;二元:我|我打|打了|了张|张三|三#;三元:我打|我打了|打了张|了张三|张三#。
当n增长时,计算压力和参数空间会迅速增长。n越大,数据越稀疏。然而,当n很小的时候,例一元模型,仅仅只是根据当前一个字来判断下一个字可能是什么,未免有失偏颇。

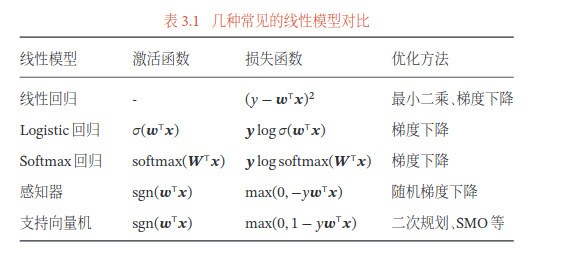
3 线性模型
多分类

“一对其余”方式和“一对一”方式都存在一个缺陷:特征空间中会存在一些难以确定类别的区域,
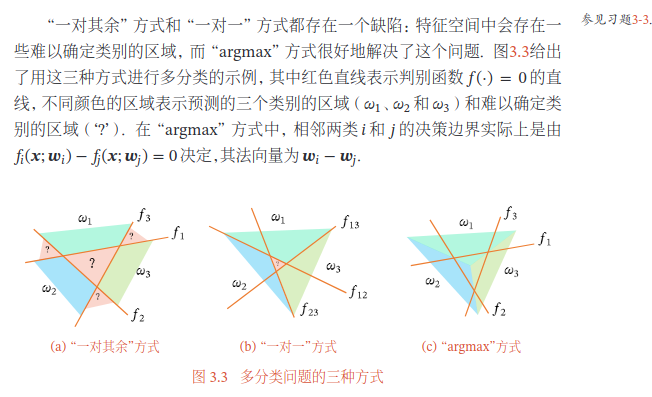
argmax方法是不是可以这样理解:如果有C个类,那么对于每个类都训练一个二分类器,如logisticsRegression。预测的时候对每个类输出一个概率值,取概率值最大的那个类
Logistic Regression
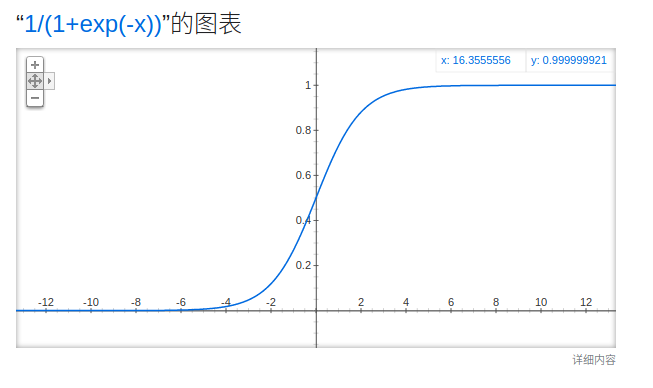
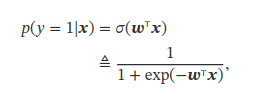
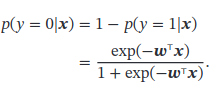
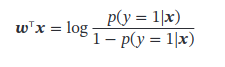
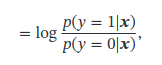

看不懂:
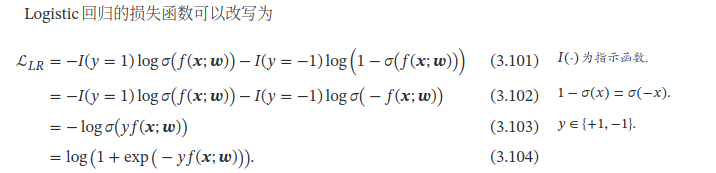
有空搞一下其他形式的logistics:
请问Logit 、 tobit模型、Probit模型有什么区别?它们各自适用的条件是什么?

Softmax Regression
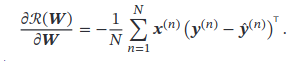
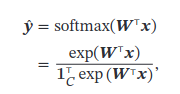
感知机



感觉不太会考,有空看看。。
支持向量机




对于一个线性可分的数据集,其分割超平面有很多个,但是间隔最大的超平面是唯一的.

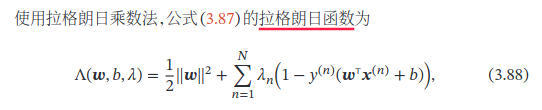

y ⋅ y ^ y\cdot \hat{y} y⋅y^ 形式的损失函数
- 交叉熵
- 感知机
损失函数:误分类点到超平面的距离
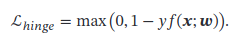
- 软间隔支持向量机
损失函数:合页损失(Hinge Loss)
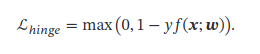
- 平方损失
y 2 = 1 y^2=1 y2=1
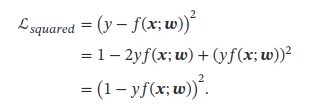
LR SVM 联系区别
参数模型和非参数模型中的“参数”并不是模型中的参数,而是数据分布的参数。
-
参数模型通常假设
总体服从某个分布,这个分布可以由一些参数确定,如正态分布由均值和标准差确定,在此基础上构建的模型称为参数模型; -
非参数模型对于总体的分布
不做任何假设或者说是数据分布假设自由,只知道其分布是存在的,所以就无法得到其分布的相关参数,只能通过非参数统计的方法进行推断。
- 非参数模型也并不是没有参数,而是参数的数目很多
- non-parametric类似单词priceless,并不是没有价值,而是价值很高。


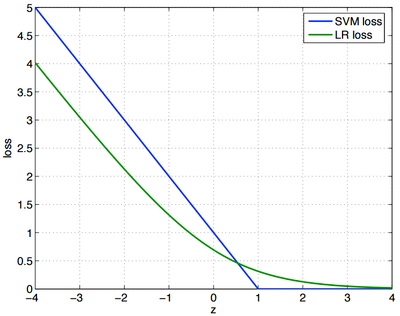
这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
SVM的处理方法是只考虑 support vectors,也就是和分类最相关的少数点,去学习分类器。
而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重,两者的根本目的都是一样的。

3.1 证明在两类线性分类中,权重向量𝒘与决策平面正交.

3.2 y=wx+b 与几何距离

3.3 线性分类中,权重向量一定是训练样本特征的线性组合
没太能看懂。。

- 优化目标
( X w ) y T > 0 (Xw)y^T>0 (Xw)yT>0
- 误差为0
X p = 0 Xp=0 Xp=0
X ( y − X w ) = 0 X(y-Xw)=0 X(y−Xw)=0
- 重点
w = ( X X T )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









