






debug日志
在写这篇日志之前,已经被困扰多时了。
开始,在backward的时候发生如下报错:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [32, 6, 197, 197]], which is output 0 of PowBackward1, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
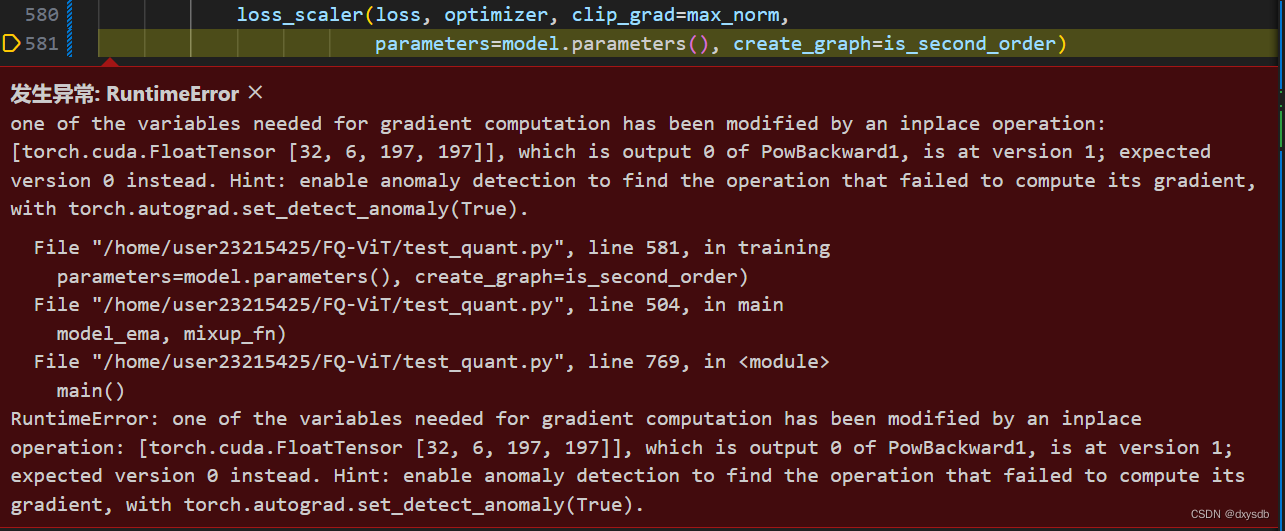
按网上和报错的意见,加入 torch.autograd.set_detect_anomaly(True) 试图寻找哪出了问题,结果被祝Good luck了😭
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [32, 6, 197, 197]], which is output 0 of PowBackward1, is at version 1; expected version 0 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
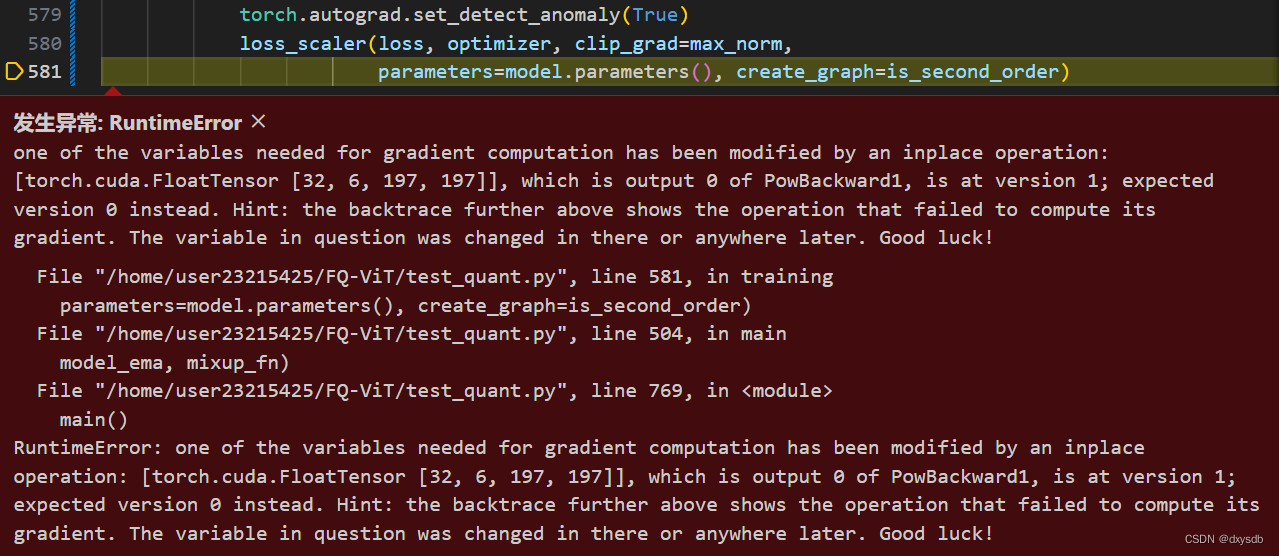
参考这篇博客https://blog.csdn.net/qq_35056292/article/details/116695219进行修改

将代码中类似的地方找出,并作出修改,如:
gates = zeros.scatter(1, top_k_indices, top_k_gates)
importance = gates.sum(0)
修改为:
gates = zeros.scatter(1, top_k_indices, top_k_gates)
gates_detached = gates.detach()
importance = gates_detached.sum(0)
但是报错仍然存在,询问了学姐的意见,可能是optimizer各种奇奇怪怪的原因,所以对它修改
(PS:因为我这里做的是只对一部分model进行训练,之前我只是在requires_grad上做了改动)
opt_params = []
for name, param in model.named_parameters():
# print(name,param.requires_grad,param.shape)
if '.gate.' in name:
param.requires_grad = True
opt_params.append(param)
else:
param.requires_grad = False
# Create an instance of the Adam optimizer
optimizer = optimizer = torch.optim.Adam(opt_params)
报错仍然存在
12.21
发现chat-GPT的强大之处,把需要训练的代码全部复制给chat-GPT问他有没有inplace的操作,一点一点改过来了😍,虽然发生了新的报错,但是总之是先面孔了
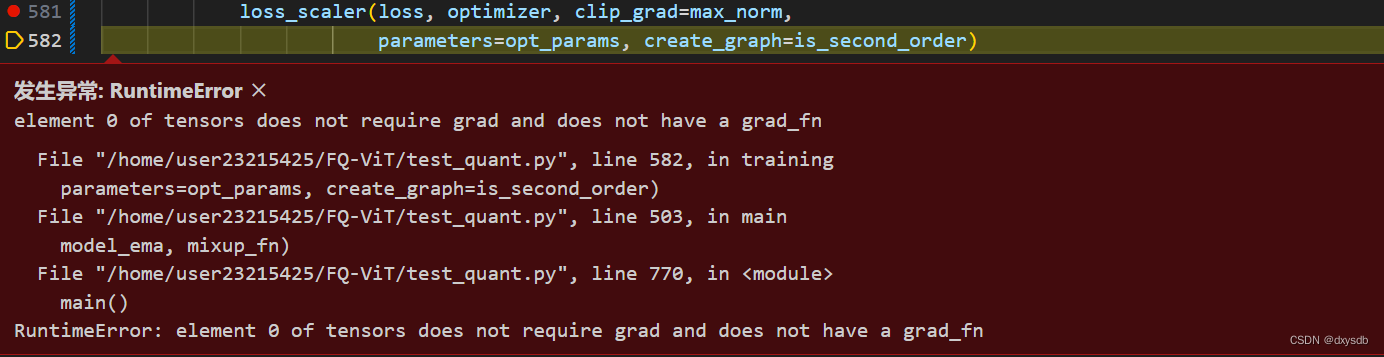
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









