









非个性化推荐算法
非个性化推荐是指在不知道用户的Preference的情况下根据用户的投票或行为(如点击、购买、查看等)作出的推荐。其可大致分为如下两类:
- 观点累积推荐
- 产品联合推荐
其中,观点累积推荐是指根据系统用户的评分,根据某种统计特征(如净支持数、平均数等),或根据某种算法得出分数,对Item进行Rank的算法。
产品联合推荐是指,通过观测用户的行为,挖掘出Item之间的联系,进而进行推荐的一种算法。如,我们在超市中观测到买
X
的顾客有相当一部分会买商品
产品联合推荐
正如上文所述,进行产品联合推荐的前提是得到Item间的联系。为此,可用如下公式对用户行为进行建模:
Relation(X,Y)=|X∩Y||X|
在这个模型中,我们考虑既买了产品
X
又买了产品为了解决这个问题,我们可以将模型修正如下:
Relation(X,Y)=|X∩Y||X||¬X∩Y||¬X|
此时,若商品
X
与商品观点累积推荐
该推荐算法是根据全体用户的投票来确定Item的评分,因此需要解决以下三个问题:
- 用户投票信息收集(投票/评分数据形式)
- 评分结果展示形式
- Item评分排序形式
投票数据形式
用户的行为可以反映用户对某个Item的态度与喜好。这种行为不仅限于给相应的Item打分,还可以是一些隐式的行为,如购买、点击、浏览等。具体说来,可分类如下:
- 显示数据
- 评分(如给出五星评分条,要求用户打分;典型例子:豆瓣)
- 评论
- 投票(如点赞、点支持等;典型例子:StackOverflow、知乎、微博)
- 隐式数据
- 点击(典型例子:搜索引擎)
- 购买(典型例子:电商网站)
- 关注(典型例子:社交网络)
评分结果展示形式
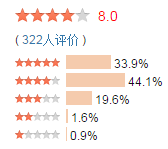
我们可以利用一些简单的手段对各个Item的评分进行展示。如,显示平均评分或者支持票数占总票数的百分比、净支持数、评分分布直方图等。在常见的网站中,豆瓣采用的就是显示评分分布直方图的形式,而知乎则采用净支持数的形式,如下图:
Item排序
对Item进行排序时,我们如果使用原始投票数据或者仅仅加上简单的数理统计作为排序依据时,往往不能收到较为满意的结果。其中一个最明显的问题是,如果投票数据很少,而投票评分很高,如果仅按照原始数据来排序的话,这个Item可能排在很靠前的位置,显然,这种排序方式是不合理的。
为此,我们可以引入衰减平均这一概念,即在没有投票的情况下,认为评分是平均的。即:
Score(i)=∑urui+kμn+k
式中
rui
是用户
u
对Item 在另一些场合,Item的Ranking可能涉及到时间问题。如新闻网站,不仅要考虑用户对内容的感兴趣程度,还要考虑内容发布的时间,时间越久,显然Ranking应该越低,于是可引入时间衰减模型:
再比如Reddit网站在2010年左右的新闻评分计算算法为:
这里,并没有使旧Item的评分随着时间的增长而减少,而是使得新的Item的评分高于旧的Item,以期获得类似的时间衰减的效果。















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









