






这篇开学后会编辑得详细点
原理解释
1. 概念
- 马尔可夫链 Markov Chain: 对于状态空间
S
S
S ,马尔可夫链定义了状态之间的转移概率。
假设,当前时刻 t t t 的状态为 q t q_t qt ,则下一个时刻 t + 1 t+1 t+1 的状态 q t + ! q_{t+!} qt+! 的条件概率 P ( q t + 1 ∣ q t ) P(q_{t+1}|q_t) P(qt+1∣qt) 之于 t t t 时刻状态有关 - 隐马尔可夫模型 Hidden Markov Model:HMM是在马尔可夫链的基础上引入了观察变量,同时状态变量不再直接观察到,而是通过观察变量的状态间接推断。HMM由一个隐藏的马尔可夫链和一个可见的输出序列组成。
有点抽象是吧,可以参考这篇知乎,举了一个通俗易懂的例子https://zhuanlan.zhihu.com/p/151011287
结构
假设隐马尔可夫模型包含以下几个要素:
- 状态集合:S= {s1,s2,…,sn},n是状态数量
- 观察集合:O={o1,o2,…,om},m是观察值数量
- 转移概率矩阵:定义状态转移概率矩阵 A A A, A i j A_{ij} Aij表示从状态 s i s_i si转移到状态 s j s_j sj的概率
- 发射概率:定义发射概率矩阵 B B B , B i k B_{ik} Bik表示在 s i s_i si状态下观察到 o k o_k ok的概率
- 初始概率:定义初始状态概率向量 p 0 p_0 p0 初始概率 p 0 i p_{0i} p0i表示系统初始时刻处于 s i s_i si的概率
代码实现
这里以2024美赛C题温网比赛数据为例(互联网上很容易找到)
简单的一个预处理
因为后续计算转移概率、获胜概率都会用到比分数据,这里将比分整理到一列
# 读取数据
data = pd.read_csv("Wimbledon_featured_matches.csv")
# 添加一列表示比赛积分状态(包括局分和盘分)
data['score_status'] = data['p1_games'].astype(str) + '-' + data['p2_games'].astype(str) + ' ' + data['p1_sets'].astype(str) + '-' + data['p2_sets'].astype(str)
df[df['match_id']==df['match_id'][0]][['match_id','score_status']]
这里只分析第一场比赛,设置一下参数(也方便后续分析其他比赛调整这个参数)。将第一场比赛数据储存到df
match_1 = data.iloc[0]['match_id']
df = data[data['match_id']==match_1]
主体部分:
- 马尔可夫链主要需要确定的就是转移概率矩阵,这里我们考虑从当前比分转移到下一比分的概率
这里记得补充说明详细一点
代码实现:
# 构建状态转移矩阵
def build_transition_matrix(df):
transition_matrix : {tuple,dict} # transition_matrix[this_state] = {nextstate1:p1, nextstate2:p2,.... }
for i in range(len(df) - 1):
row = df.iloc[i]
next_row = df.iloc[i + 1]
current_state = (row['player1'],row['score_status'],row['server'])
next_state = (next_row['player1'], next_row['score_status'],row['server'])
if current_state not in transition_matrix:
transition_matrix[current_state] = {}
if next_state not in transition_matrix[current_state]:
transition_matrix[current_state][next_state] = 0
transition_matrix[current_state][next_state] += 1
# 将计数转换为概率
for current_state, next_states in transition_matrix.items():
total_transitions = sum(next_states.values())
for next_state in next_states:
transition_matrix[current_state][next_state] /= total_transitions
return transition_matrix
transition_matrix = build_transition_matrix(df)
transition_matrix
-
获胜概率: p w i n = ( p w i n ) / ( p w i n + p l o s e ) p_{win} = (p_win) / (p_{win}+p_{lose}) \quad pwin=(pwin)/(pwin+plose)
举个例子,当前比分为2-2时,下一比分只可能为2-3或3-2,此时player1获胜概率就为 p 3 − 2 / ( p 2 − 3 + p 3 − 2 ) p_{3-2}/(p_{2-3}+p_{3-2}) p3−2/(p2−3+p3−2)
def calculate_win_prob(transition_matrix,player):
win_prob = {}
if player==1:
player=2 #score state格式 5-2 1-1,str[2]提取player2比分
for state in transition_matrix:
# 运动员的胜率计算
if state not in win_prob.keys():
win_prob[state] = 0 # 初始化胜率为0
win_score:int=0
lose_score:int=0
for next_state, prob in transition_matrix[state].items():
if next_state[1][player]>state[1][player]:
win_score+=prob
else:
lose_score+=prob
print(win_score,lose_score)
win_prob[state] = win_score/(win_score+lose_score)
return win_prob
win_prob1 = calculate_win_prob(transition_matrix,0)
win_prob2 = calculate_win_prob(transition_matrix,1)
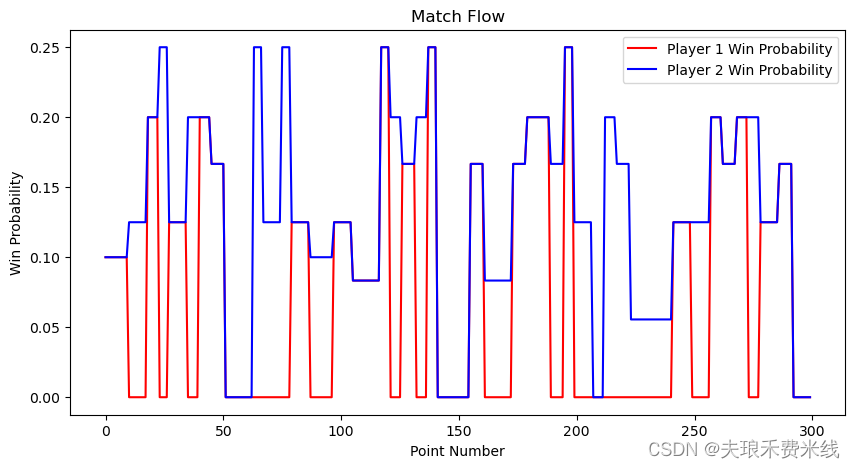
结果展示
可视化第一场比赛双方获胜概率变化
数据的解释就自己发挥啦,我这里的的解释是双方获胜概率差距很大的时候(比如130-150区间),是一个赛点















 6891
6891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









