







如何在Python中选择数据集中相等数量的0和1值
介绍:
在数据处理中,有时候会遇到类不平衡的情况,即某些类别的样本数量明显偏多或偏少。在处理类不平衡数据时,有时需要从数据集中选择相等数量的样本,以保持数据的平衡性。
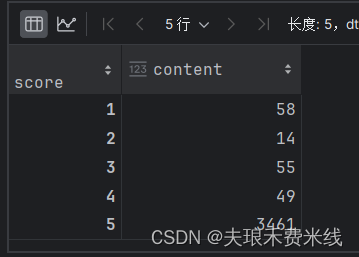
比如在电商评论数据中,五星评论数量远远高于其他数据。
df = pd.read_csv('京东评论数据.csv')
df['content'].groupby(df['score']).count()
得到结果:
解决
这里的解决思路是从两个样本中分别选出等量的样本/或者特定比例的样本
pandas解决
- 首先,使用pandas库将数据加载到一个DataFrame中。
- 接下来,从数据集中选择所有值为0的数据。
- 然后,从数据集中随机选择与值为0的数据数量相等的值为1的数据。
- 最后,将选定的数据合并成一个新的DataFrame,即所需的平衡数据集。
import pandas as pd
# 加载数据
data = pd.read_csv('data.csv')
# 选择值为0的数据
data_0 = data[data['column_name'] == 0]
# 选择等量的值为1的数据
data_1 = data[data['column_name'] == 1].sample(n=len(data_0), random_state=1)
# 合并数据
selected_data = pd.concat([data_0, data_1])
# 现在,selected_data中包含了你所需的数据,其中包括相同数量的0和1的值
用在我们的电商平台评论数据上就是
import pandas as pd
df = pd.read_csv('京东评论数据.csv')
df['score'].astype(int)
df_0 = df[df['score']<4]
df_1 = df[df['score']>=4].sample(n=len(df_0),random_state=1)
data = pd.concat([df_0,df_1])
data['score'].astype(int)
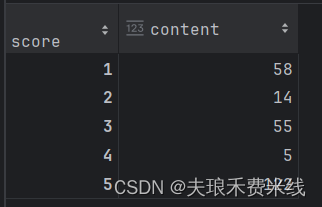
data['content'].groupby(data['score']).count()
得到结果:
sklearn解决
思路和pandas相同,仍然是分别选择再合并,只是我们使用resample函数调整数据集大小
from sklearn.utils import resample
import pandas as pd
# 加载数据
data = pd.read_csv('data.csv')
# 分割数据为值为0和值为1的两个子集
data_0 = data[data['column_name'] == 0]
data_1 = data[data['column_name'] == 1]
# 从值为1的数据中随机选择与值为0的数据相等数量的样本
data_1_downsampled = resample(data_1, replace=False, n_samples=len(data_0), random_state=1)
# 合并数据
balanced_data = pd.concat([data_0, data_1_downsampled])
# balanced_data 现在包含了相等数量的值为0和1的数据
评论数据分析练习
最后放一个我做的基于svm电商评论数据情感分类案例,大家看个乐子吧
数据来源:群鲸 3000条京东手机评论
数据预处理
import pandas as pd
df = pd.read_csv('京东评论数据.csv')
df['score'].astype(int)
df_0 = df[df['score']<4]
df_1 = df[df['score']>=4].sample(n=len(df_0),random_state=1)
data = pd.concat([df_0,df_1])
data['score'].astype(int)
data['content'].groupby(data['score']).count()
生成文本向量,划分训练集
import jieba
emotion= []
text_split=[]
## score》=4视为积极
for index,row in data.iterrows():
if row['score']>=4:
emotion.append(1)
else:
emotion.append(0)
bg=jieba.lcut(row['content'])
text_split.append(" ".join(bg))
from sklearn.feature_extraction.text import CountVectorizer
cv=CountVectorizer()
X=cv.fit_transform(text_split).toarray()
Y = emotion
拟合模型进行预测
from sklearn.model_selection import train_test_split
from sklearn import svm
import time
start_time = time.time()
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=1)
svm = svm.SVC(kernel='sigmoid',gamma=0.7,C=10,max_iter=1000)
svm.fit(X_train,Y_train)
Y_pred = svm.predict(X_test)
from sklearn import metrics
print(svm.score(X_test,Y_test))
print("report:\n",metrics.classification_report(Y_test,Y_pred))
print(metrics.confusion_matrix(Y_test,Y_pred))
end_time = time.time()
得到精确度和召回率都是0.65左右,效果不是很好哈哈哈,您可以调整参数或者用其他模型分类















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









