







零.功能介绍
与虚拟角色(非形象)进行文本或语音会话
-
体验地址:RealChar.
一.整体架构
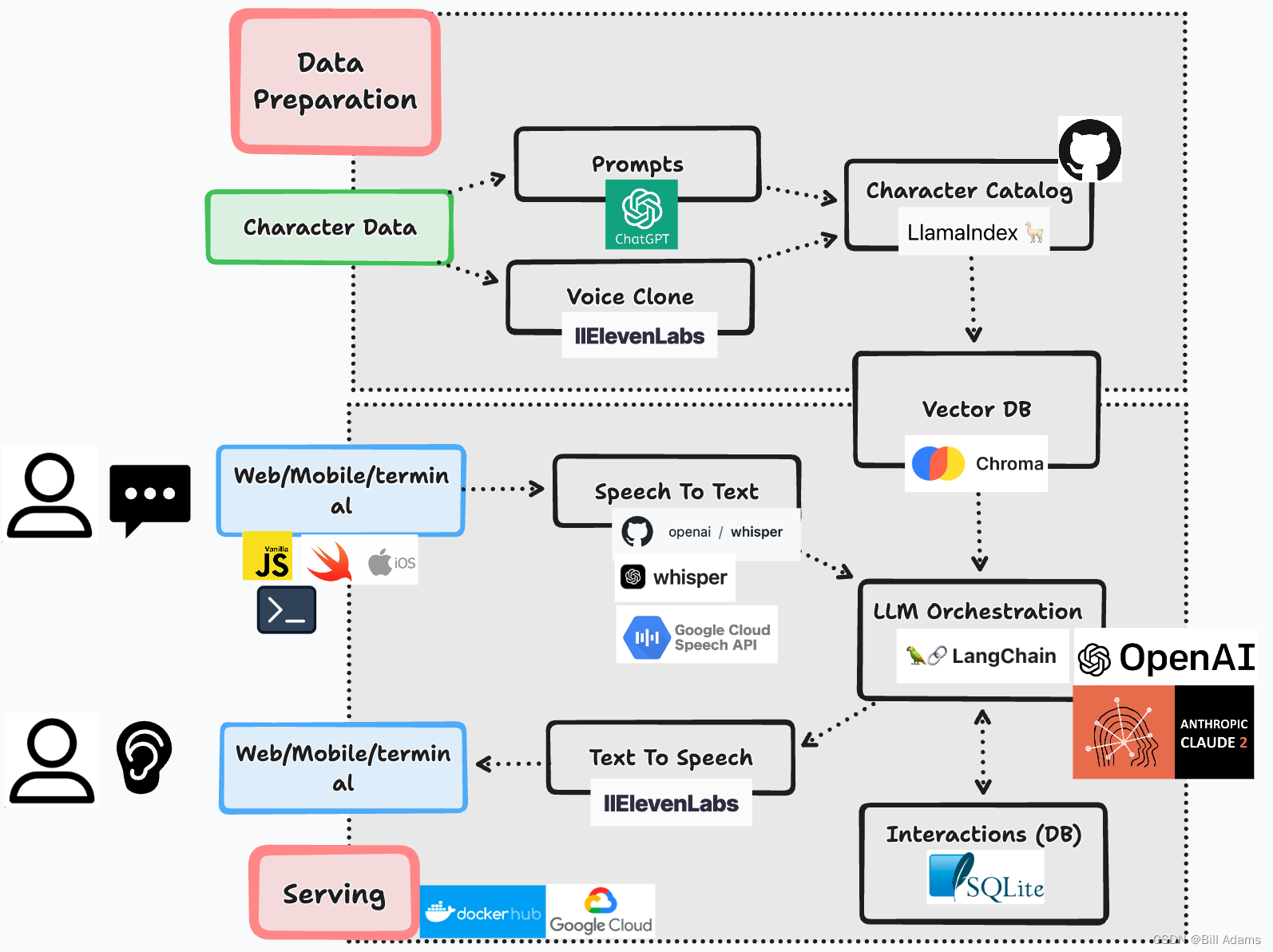
二.技术选型
-
✅Web: Vanilla JS, WebSockets
-
✅Mobile: Swift, WebSockets
-
✅Data Ingestion: LlamaIndex, Chroma
-
✅Speech to Text: Local Whisper, OpenAI Whisper API, Google Speech to Text
-
✅Text to Speech: ElevenLabs
-
✅Voice Clone: ElevenLabs
三.安装方法
-
Step 1. 拉取代码库
git clone https://github.com/Shaunwei/RealChar.git && cd RealChar-
Step 2. 安装依赖
# for ubuntu sudo apt update sudo apt install portaudio19-dev sudo apt install ffmpeg# for mac brew install portaudio brew install ffmpeg
-
安装其他python依赖库
pip install -r requirements.txt-
Step 3. 第一次使用时创建空的sqlite数据库
sqlite3 test.db "VACUUM;"-
Step 4. 升级db
alembic upgrade head-
Step 5. 配置
.env: 更新API Key及相关信息
cp .env.example .env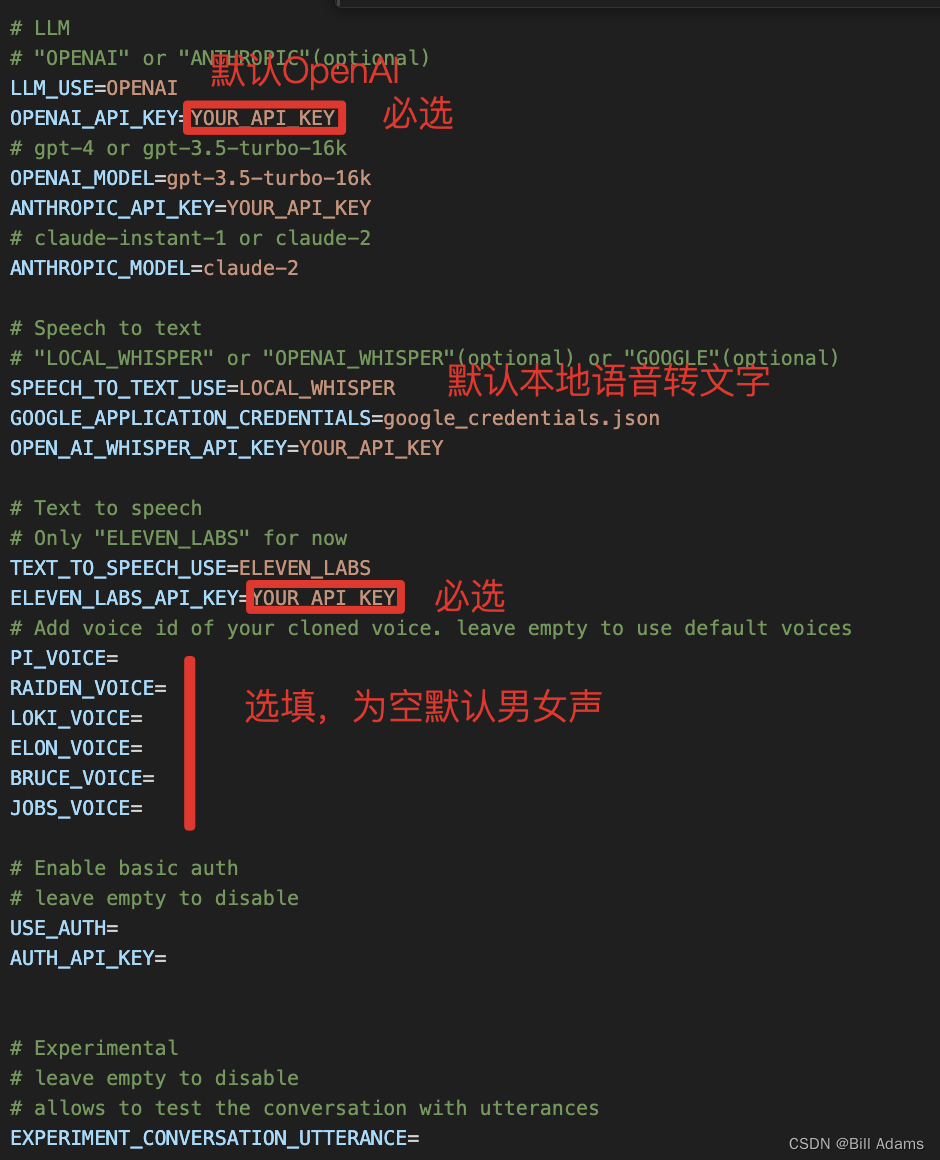
特别说明:由于用到了webrtc,要求使用https,故本地调试时需要安装证书。方法如下:
1.安装mkcert
brew install mkcert
brew install nss
nss 是可选的,如果不使用或者不需要测试 Firefox,那么可以不安装 nss。
2.生成证书,并加入系统信任
mkdir -p ~/.cert
mkcert -key-file ~/.cert/key.pem -cert-file ~/.cert/cert.pem "localhost"
mkcert -install
3.修改服务,加入证书
@click.command(context_settings={"ignore_unknown_options": True})
@click.argument('args', nargs=-1, type=click.UNPROCESSED)
def run_uvicorn(args):
click.secho("Running uvicorn server...", fg='green')
subprocess.run(["uvicorn", "realtime_ai_character.main:app",
"--host", "localhost", "--ws-ping-interval", "60", "--ws-ping-timeout", "60", "--timeout-keep-alive", "60", "--ssl-keyfile", "/Users/xxx/.cert/key.pem", "--ssl-certfile", "/Users/xxx/.cert/cert.pem"] +list(args))
-
Step 6. 通过
cli.py或uvicorn启动服务
python cli.py run-uvicorn
# or
uvicorn realtime_ai_character.main:app-
Step 7. 启动客户端:
-
为了更好地会话内容,建议使用GPT4,建议使用耳机以避免回声
-
启动浏览器打开网址:https://localhost:8000
-
-
Step 8. 选择一个角色进行对话
四.角色制作
1.角色记忆库与特征语音生成
角色特征分成两个部分:角色的记忆库文件和角色的语音。其中最重要的部分是角色的记忆库文件,它是在GPT的帮助下生成的。要创建一个角色,首先我们需要检查GPT的记忆库是否包含有关该角色的信息。如果有,整个过程将会容易得多。
(1)角色记忆库创建
我们可以包含许多不同类型的文件,但最重要的是一个CSV文件。
以下两个部分描述了创建洛基记忆文件的过程:
1.如何生成50个洛基演讲示例:
提示词:Help me find 50 examples of how Loki from Marvel Cinematic Universe talks. I want to generate a format like "context", "quote". It needs to be in csv format. The quote should only include Loki's words, represent Loki's personality and how he talks, and be an actual quote from a movie or novel, not made up. The context should be unique.
参考文件:https://chat.openai.com/share/73f29bc2-bbfe-43f1-a3a7-a3ce82a299c3
格式确保有三列,以下是具体的格式参考:https://github.com/Shaunwei/Realtime-AI-Character/blob/main/realtime_ai_character/chacater_catalog/marvel_loki/data/talk.csv
2.如何生成描述洛基背景的文件:
提示词1: Do you know Loki from Marvel movies?
提示词2: Write me a simple system prompt for a new version of you to be Loki the character, and the new version of you can speak and sound like Loki. Tell it as first person. Here is a previous example for a character.
提示词3: Refine and simplify it into 100 words.
参考提示文件:https://chat.openai.com/share/a2a213c7-cb1e-441e-a651-129333fefb72(2)角色特征语音合成(基于ElevenLabs)
a.收集数据
在开始之前,您需要语音数据。下载高质量的纯人声音频剪辑。training_data文件夹以供参考。
-
如果您要创建自己的数据集,请确保音频是高质量的。应该没有背景噪音,发音清晰
-
音频格式必须为 mp3,总长度约为 1 分钟
b.创建 ElevenLabs 账户
访问 ElevenLabs 创建账户。您需要它来访问语音合成和语音克隆功能。
获取您的 ELEVEN_LABS_API_KEY :
-
单击个人资料图标并选择“个人资料”。
-
复制 API 密钥
c.语音合成/语音克隆
请按照以下步骤克隆语音:
-
进入语音合成页面。
-
单击“Add Voice”。
-
单击“Add Generative or Cloned Voice”。
-
单击“Instant Voice Cloning”。
-
填写所有必需的信息并上传您的音频样本。
-
单击“Add Voice”。
d.测试你的声音
要测试您刚刚创建的声音:
-
返回语音合成页面。
-
选择您刚刚在“设置”中创建的声音。
-
输入一些文本并单击“Generate”。
e.微调你的声音
您可以通过调整系统和用户提示来使语音朗读效果更好。以下是一些提示:
-
如果声音太单调,请降低稳定性以使其更加情绪化。然而,将稳定性设置为零有时会导致奇怪的口音。
-
较长的句子往往会说得更好,因为它们为人工智能扬声器提供了更多可以理解的上下文。
-
对于说得太快的较短句子,请替换“。”和 ”...”。添加“-”或换行符以暂停。
-
添加与情感相关的单词或短语,或使用标点符号,如“!”、“?”为声音添加情感。
f.在我们的项目中使用您的自定义声音
您需要克隆语音的语音ID。就是这样:
-
选择获取语音 api
-
按照说明操作并在 Responses 中找到特定的 voice_id。
-
不要忘记使用
ELEVEN_LABS_API_KEY和语音 ID 更新您的 .env 文件。
2.角色生成
(1)角色信息目录结构
character_catalog
├── ai_character_helper
│ ├── data
│ │ ├── background
│ │ ├── xxx.md
│ ├── system
│ └── user
├── loki
...
-
每个文件夹是一个AI角色,如:loki
-
只需复制粘贴
ai_character_helper文件夹并将其重命名为您角色的名字 -
ai_character_helper文件夹中有两个文件和一个文件夹-
system文件:用于定义AI角色的系统prompt
-
user文件
-
用于用户输入的用户模板
-
用于为 AI 角色对话提供上下文
-
-
data目录
-
用于在对话过程中提取相关信息
-
自动存储在内存矢量数据库(Chroma)中,以便快速检索
-
支持以下文件类型
-
纯文本文件,如:
background -
.pdf -
.docx -
.pptx -
.png -
.csv -
.epub -
.md -
.mbox -
.ipynb
-
-
-
(2)角色信息制作步骤
-
选一个角色并给角命名
-
复制粘贴
ai_character_helper文件夹并将其重命名为您角色的名字 -
更新
system文件来定义角色描述 -
添加
data文件来增强角色的知识 -
(可选)自定义角色的声音
-
(可选)自定义角色头像
-
(可选)更新
user文件定义自定义用户输入
五.代码结构
1.后台(Python fastAPI)
(1)初始化
a.页面文件加载路由设置
app.include_router(restful_router)
templates = Jinja2Templates(directory=os.path.join(
os.path.dirname(os.path.abspath(__file__)), 'static'))
@router.get("/status")
async def status():
return {"status": "ok"}
@router.get("/", response_class=HTMLResponse)
async def index(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
app.mount("/static", StaticFiles(directory=os.path.join(
os.path.dirname(os.path.abspath(__file__)), 'static')), name="static")b.websocket路由监听设置
app.include_router(websocket_router)c.初始化分类管理器
CatalogManager.initialize(overwrite=True)1. 初始化创建角色,加载角色信息
1.1.加载角色名、system、user等信息
def load_character(self, directory):
with ExitStack() as stack:
f_system = stack.enter_context(open(directory / 'system'))
f_user = stack.enter_context(open(directory / 'user'))
system_prompt = f_system.read()
user_prompt = f_user.read()
name = directory.stem.replace('_', ' ').title()
self.characters[name] = Character(
name=name,
llm_system_prompt=system_prompt,
llm_user_prompt=user_prompt
)
return name1.2.根据角色名加载角色记忆库
def load_data(self, character_name: str, data_path: str):
loader = SimpleDirectoryReader(Path(data_path))
documents = loader.load_data()
print(documents)
text_splitter = CharacterTextSplitter(
separator='\n',
chunk_size=500,
chunk_overlap=100)
docs = text_splitter.create_documents(
texts=[d.text for d in documents],
metadatas=[{
'character_name': character_name,
'id': d.id_,
} for d in documents])
self.db.add_documents(docs)2.词向量数据持久化
if overwrite:
logger.info('Persisting data in the chroma.')
self.db.persist()
logger.info(
f"Total document load: {self.db._client.get_collection('llm').count()}")d.初始化连接管理器
ConnectionManager.initialize()
class ConnectionManager(Singleton):
def __init__(self):
self.active_connections: List[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
async def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
print(f"Client #{id(websocket)} left the chat")
# await self.broadcast_message(f"Client #{id(websocket)} left the chat")
async def send_message(self, message: str, websocket: WebSocket):
if websocket.application_state == WebSocketState.CONNECTED:
await websocket.send_text(message)
async def broadcast_message(self, message: str):
for connection in self.active_connections:
if connection.application_state == WebSocketState.CONNECTED:
await connection.send_text(message)
def get_connection_manager():
return ConnectionManager.get_instance()e.初始化文本转语音(初始化elevenlabs)
get_text_to_speech()
def get_text_to_speech() -> TextToSpeech:
use = os.getenv('TEXT_TO_SPEECH_USE', 'ELEVEN_LABS')
if use == 'ELEVEN_LABS':
from realtime_ai_character.audio.text_to_speech.elevenlabs import ElevenLabs
ElevenLabs.initialize()
return ElevenLabs.get_instance()
else:
raise NotImplementedError(f'Unknown text to speech engine: {use}')
config = types.SimpleNamespace(**{
'default_voice': '21m00Tcm4TlvDq8ikWAM',
'default_female_voice': 'EXAVITQu4vr4xnSDxMaL',
'default_male_voice': 'ErXwobaYiN019PkySvjV',
'chunk_size': 1024,
'url': 'https://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream',
'headers': {
'Accept': 'audio/mpeg',
'Content-Type': 'application/json',
'xi-api-key': os.environ['ELEVEN_LABS_API_KEY']
},
'data': {
'model_id': 'eleven_monolingual_v1',
'voice_settings': {
'stability': 0.5,
'similarity_boost': 0.75
}
}
})
class ElevenLabs(Singleton, TextToSpeech):
def __init__(self):
super().__init__()
logger.info("Initializing [ElevenLabs Text To Speech] voices...")
self.voice_ids = {
"Raiden Shogun And Ei": os.environ.get('RAIDEN_VOICE') or config.default_female_voice,
"Loki": os.environ.get('LOKI_VOICE') or config.default_male_voice,
"Reflection Pi": os.environ.get('PI_VOICE') or config.default_female_voice,
"Elon Musk": os.environ.get('ELON_VOICE') or config.default_male_voice,
"Bruce Wayne": os.environ.get('BRUCE_VOICE') or config.default_male_voice,
"Steve Jobs": os.environ.get('JOBS_VOICE') or config.default_male_voice
}
def get_voice_id(self, name):
return self.voice_ids.get(name, config.default_voice)
async def stream(self, text, websocket, tts_event: asyncio.Event, characater_name="", first_sentence=False) -> None:
if DEBUG:
return
headers = config.headers
data = {
"text": text,
**config.data,
}
voice_id = self.get_voice_id(characater_name)
url = config.url.format(voice_id=voice_id)
if first_sentence:
url = url + '?optimize_streaming_latency=4'
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data, headers=headers)
async for chunk in response.aiter_bytes():
await asyncio.sleep(0.1)
if tts_event.is_set():
# stop streaming audio
break
await websocket.send_bytes(chunk)f.初始化语音转文本(初始化google、whisper)
get_speech_to_text()
def get_speech_to_text() -> SpeechToText:
use = os.getenv('SPEECH_TO_TEXT_USE', 'LOCAL_WHISPER')
if use == 'GOOGLE':
from realtime_ai_character.audio.speech_to_text.google import Google
Google.initialize()
return Google.get_instance()
elif use == 'LOCAL_WHISPER':
from realtime_ai_character.audio.speech_to_text.whisper import Whisper
Whisper.initialize(use='local')
return Whisper.get_instance()
elif use == 'OPENAI_WHISPER':
from realtime_ai_character.audio.speech_to_text.whisper import Whisper
Whisper.initialize(use='api')
return Whisper.get_instance()
else:
raise NotImplementedError(f'Unknown speech to text engine: {use}')
// 默认local,可选local、google、openai whisper
config = types.SimpleNamespace(**{
'model': 'tiny',
'language': 'en',
'api_key': os.getenv("OPENAI_API_KEY"),
})
class Whisper(Singleton, SpeechToText):
def __init__(self, use='local'):
super().__init__()
if use == 'local':
logger.info(f"Loading [Local Whisper] model: [{config.model}]...")
self.model = whisper.load_model(config.model)
self.recognizer = sr.Recognizer()
self.use = use
if DEBUG:
self.wf = wave.open('output.wav', 'wb')
self.wf.setnchannels(1) # Assuming mono audio
self.wf.setsampwidth(2) # Assuming 16-bit audio
self.wf.setframerate(44100) # Assuming 44100Hz sample rate(2)交互流程
a.请求连接
两件事:鉴权、异步接收数据
manager = get_connection_manager()
@router.websocket("/ws/{client_id}")
async def websocket_endpoint(
websocket: WebSocket,
client_id: int = Path(...),
api_key: str = Query(None),
db: Session = Depends(get_db),
llm: LLM = Depends(get_llm),
catalog_manager=Depends(get_catalog_manager),
speech_to_text=Depends(get_speech_to_text),
text_to_speech=Depends(get_text_to_speech)):
# basic authentication
if os.getenv('USE_AUTH', '') and api_key != os.getenv('AUTH_API_KEY'):
await websocket.close(code=1008, reason="Unauthorized")
return
await manager.connect(websocket)
try:
main_task = asyncio.create_task(
handle_receive(websocket, client_id, db, llm, catalog_manager, speech_to_text, text_to_speech))
await asyncio.gather(main_task)
except WebSocketDisconnect:
await manager.disconnect(websocket)
await manager.broadcast_message(f"Client #{client_id} left the chat")b.会话建立
接收端的第一个消息:
{'type': 'websocket.receive', 'text': 'web'}根据客户端ID及平台类型建立会话,并响应服务端角色列表供用户选择。
# 0. Receive client platform info (web, mobile, terminal)
data = await websocket.receive()
if data['type'] != 'websocket.receive':
raise WebSocketDisconnect('disconnected')
platform = data['text']
logger.info(f"Client #{client_id}:{platform} connected to server")
# 1. User selected a character
character = None
character_list = list(catalog_manager.characters.keys())
user_input_template = 'Context:{context}\n User:{query}'
while not character:
character_message = "\n".join(
[f"{i+1} - {character}" for i, character in enumerate(character_list)])
await manager.send_message(
message=f"Select your character by entering the corresponding number:\n{character_message}\n",
websocket=websocket)
data = await websocket.receive()响应服务器角色列表:
Select your character by entering the corresponding number:
1 - Elon Musk
2 - Loki
3 - Raiden Shogun And Ei
4 - Bruce Wayne
5 - Steve Jobsc.角色选择
角色选择消息:
{'type': 'websocket.receive', 'text': '2'}根据角色编号获取角色对象,为对话启动做准备:
data = await websocket.receive()
if data['type'] != 'websocket.receive':
raise WebSocketDisconnect('disconnected')
if not character and 'text' in data:
selection = int(data['text'])
if selection > len(character_list) or selection < 1:
await manager.send_message(
message=f"Invalid selection. Select your character [{', '.join(catalog_manager.characters.keys())}]\n",
websocket=websocket)
continue
character = catalog_manager.get_character(
character_list[selection - 1])
conversation_history.system_prompt = character.llm_system_prompt
user_input_template = character.llm_user_prompt
logger.info(
f"Client #{client_id} selected character: {character.name}")d.角色对话
启动无限循环,首先接收用户的会话文本或语音数据
文本数据样例:
{'type': 'websocket.receive', 'text': 'how are you'然后根据数据是文本还是二进制语音进行相关处理
如果是文本对话数据
则组装会话历史交由大模型生成对话结果,对话结果通过两条链路返回端,一条基于文本的逐词返回,一条则通过文本转语音返回语音二进制流。
特别说明,如果接受的文本以[&]开头,则表示用户中断上一轮对话,此时需要终止文本返回和语音转文本返回,并启动新的对话。
对话结束后,会将[end]\n响应到端
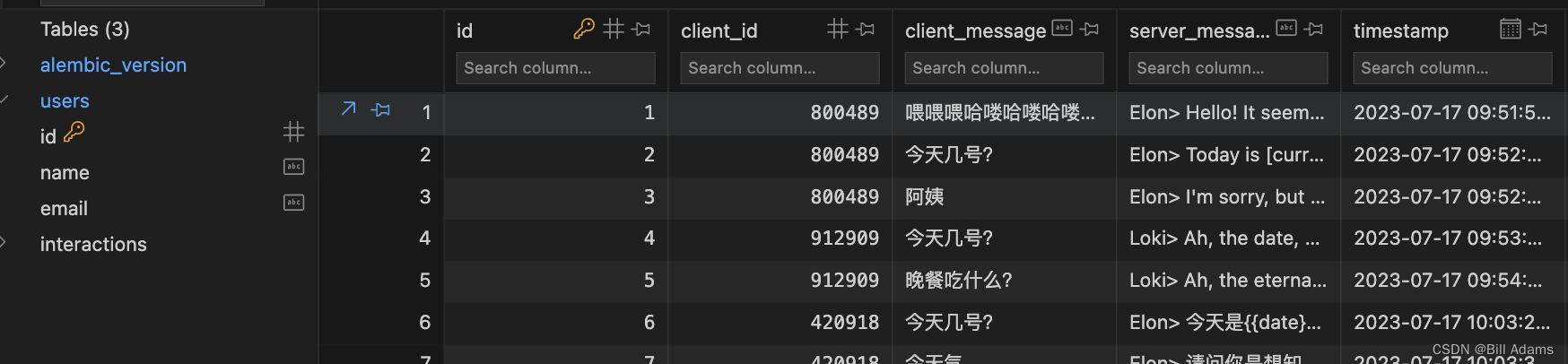
更新对话历史并持久化存储此轮对话到db。
如果是二进制语音数据
则首先调用语音转文本函数,将语音转成文本。
通过文本长度小于2进行去噪处理。
将转成的文本发送到端,格式:[+]You said: {transcript}
停止之前的文本转语音流发送
调用大模型生成对话结果,结果以回调方式更新对话历史并持久化存储到db
详细代码如下:
tts_event = asyncio.Event()
tts_task = None
previous_transcript = None
token_buffer = []
async def on_new_token(token):
return await manager.send_message(message=token, websocket=websocket)
async def stop_audio():
if tts_task and not tts_task.done():
tts_event.set()
tts_task.cancel()
if previous_transcript:
conversation_history.user.append(previous_transcript)
conversation_history.ai.append(' '.join(token_buffer))
token_buffer.clear()
try:
await tts_task
except asyncio.CancelledError:
pass
tts_event.clear()
while True:
data = await websocket.receive()
if data['type'] != 'websocket.receive':
raise WebSocketDisconnect('disconnected')
# handle text message
if 'text' in data:
msg_data = data['text']
# 0. itermidiate transcript starts with [&]
if msg_data.startswith('[&]'):
logger.info(f'intermediate transcript: {msg_data}')
if not os.getenv('EXPERIMENT_CONVERSATION_UTTERANCE', ''):
continue
asyncio.create_task(stop_audio())
asyncio.create_task(llm.achat_utterances(
history=build_history(conversation_history),
user_input=msg_data,
callback=AsyncCallbackTextHandler(on_new_token, []),
audioCallback=AsyncCallbackAudioHandler(text_to_speech, websocket, tts_event, character.name)))
continue
# 1. Send message to LLM
response = await llm.achat(
history=build_history(conversation_history),
user_input=msg_data,
user_input_template=user_input_template,
callback=AsyncCallbackTextHandler(
on_new_token, token_buffer),
audioCallback=AsyncCallbackAudioHandler(
text_to_speech, websocket, tts_event, character.name),
character=character)
# 2. Send response to client
await manager.send_message(message='[end]\n', websocket=websocket)
# 3. Update conversation history
conversation_history.user.append(msg_data)
conversation_history.ai.append(response)
token_buffer.clear()
# 4. Persist interaction in the database
Interaction(
client_id=client_id, client_message=msg_data, server_message=response).save(db)
# handle binary message(audio)
elif 'bytes' in data:
binary_data = data['bytes']
# 1. Transcribe audio
transcript: str = speech_to_text.transcribe(
binary_data, platform=platform, prompt=character.name).strip()
# ignore audio that picks up background noise
if (not transcript or len(transcript) < 2):
continue
# 2. Send transcript to client
await manager.send_message(message=f'[+]You said: {transcript}', websocket=websocket)
# 3. stop the previous audio stream, if new transcript is received
await stop_audio()
previous_transcript = transcript
async def tts_task_done_call_back(response):
# Send response to client, [=] indicates the response is done
await manager.send_message(message='[=]', websocket=websocket)
# Update conversation history
conversation_history.user.append(transcript)
conversation_history.ai.append(response)
token_buffer.clear()
# Persist interaction in the database
Interaction(
client_id=client_id, client_message=transcript, server_message=response).save(db)
# 4. Send message to LLM
tts_task = asyncio.create_task(llm.achat(
history=build_history(conversation_history),
user_input=transcript,
user_input_template=user_input_template,
callback=AsyncCallbackTextHandler(
on_new_token, token_buffer, tts_task_done_call_back),
audioCallback=AsyncCallbackAudioHandler(
text_to_speech, websocket, tts_event, character.name),
character=character)
)
2.客户端(web)
涉及websocket技术、webrtc技术和WebASR技术。
(1)创建音频设备
页面加载完成后,启动音频的多媒体设备检测(这里需要上文所述的https协议,否则无法枚举设备),并将设备信息加入选择清单。
const audioDeviceSelection = document.getElementById('audio-device-selection');
window.addEventListener("load", function() {
navigator.mediaDevices.enumerateDevices()
.then(function(devices) {
// Filter out the audio input devices
let audioInputDevices = devices.filter(function(device) {
return device.kind === 'audioinput';
});
// If there are no audio input devices, display an error and return
if (audioInputDevices.length === 0) {
console.log('No audio input devices found');
return;
}
// Add the audio input devices to the dropdown
audioInputDevices.forEach(function(device, index) {
let option = document.createElement('option');
option.value = device.deviceId;
option.textContent = device.label || `Microphone ${index + 1}`;
audioDeviceSelection.appendChild(option);
});
})
.catch(function(err) {
console.log('An error occurred: ' + err);
});
});
audioDeviceSelection.addEventListener('change', function(e) {
connectMicrophone(e.target.value);
});(2)创建websocket
通过用户点击按钮交互实现音频设备选择、连接、断开。
const connectButton = document.getElementById('connect');
const disconnectButton = document.getElementById('disconnect');
const devicesContainer = document.getElementById('devices-container');
let socket;
let clientId = Math.floor(Math.random() * 10000000);
function connectSocket() {
chatWindow.value = "";
var clientId = Math.floor(Math.random() * 1010000);
var ws_scheme = window.location.protocol == "https:" ? "wss" : "ws";
var ws_path = ws_scheme + '://' + window.location.host + `/ws/${clientId}`;
socket = new WebSocket(ws_path);
socket.binaryType = 'arraybuffer';
socket.onopen = (event) => {
console.log("successfully connected");
connectMicrophone(audioDeviceSelection.value);// websocket连接成功后,初始化麦克风及语音转文本
speechRecognition();
socket.send("web"); // select web as the platform
};
socket.onmessage = (event) => {
if (typeof event.data === 'string') {// 处理文本消息
const message = event.data;
if (message == '[end]\n') {// 服务端完成文本对话响应消息
chatWindow.value += "\n\n";
chatWindow.scrollTop = chatWindow.scrollHeight;
} else if (message.startsWith('[+]')) {// 服务端发送的语音转文本信息
// [+] indicates the transcription is done. stop playing audio
chatWindow.value += `\nYou> ${message}\n`;
stopAudioPlayback();
} else if (message.startsWith('[=]')) {// 服务端语音数据发送完毕
// [=] indicates the response is done
chatWindow.value += "\n\n";
chatWindow.scrollTop = chatWindow.scrollHeight;
} else if (message.startsWith('Select')) {// 服务端列举所有可用角色
createCharacterGroups(message);
} else {
chatWindow.value += `${event.data}`;
chatWindow.scrollTop = chatWindow.scrollHeight;
// if user interrupts the previous response, should be able to play audios of new response
shouldPlayAudio=true;
}
} else { // 处理音频二进制数据
if (!shouldPlayAudio) {
return;
}
audioQueue.push(event.data);
if (audioQueue.length === 1) {
playAudios();// 播放服务端的响应音频数据
}
}
};
socket.onerror = (error) => {
console.log(`WebSocket Error: ${error}`);
};
socket.onclose = (event) => {
console.log("Socket closed");
};
}
connectButton.addEventListener("click", function() {// 连接按钮点击事件
connectButton.style.display = "none";
textContainer.textContent = "Select a character";
devicesContainer.style.display = "none";
connectSocket();
talkButton.style.display = 'flex';
textButton.style.display = 'flex';
});
disconnectButton.addEventListener("click", function() {// 断开连接按钮点击事件
stopAudioPlayback();
if (radioGroupsCreated) {
destroyRadioGroups();
}
if (mediaRecorder) {
mediaRecorder.stop();
}
if (recognition) {
recognition.stop();
}
textContainer.textContent = "";
disconnectButton.style.display = "none";
playerContainer.style.display = "none";
stopCallButton.style.display = "none";
continueCallButton.style.display = "none";
messageButton.style.display = "none";
sendButton.style.display = "none";
messageInput.style.display = "none";
chatWindow.style.display = "none";
callButton.style.display = "none";
connectButton.style.display = "flex";
devicesContainer.style.display = "flex";
talkButton.disabled = true;
textButton.disabled = true;
chatWindow.value = "";
selectedCharacter = null;
characterSent = false;
callActive = false;
showRecordingStatus();
socket.close();
});
(3)音频采集与传输
用户从下拉列表选择麦克风后,触发MediaRecorder创建,相关回调的初始化工作。其中采集完毕触发websocket将音频数据发送到服务端操作。
let mediaRecorder;
let chunks = [];
let finalTranscripts = [];
let debug = false;
let audioSent = false;
function connectMicrophone(deviceId) {
navigator.mediaDevices.getUserMedia({
audio: {
deviceId: deviceId ? {exact: deviceId} : undefined,
echoCancellation: true
}
}).then(function(stream) {
mediaRecorder = new MediaRecorder(stream);
mediaRecorder.ondataavailable = function(e) {
chunks.push(e.data);
}
mediaRecorder.onstart = function() {
console.log("recorder starts");
}
mediaRecorder.onstop = function(e) {
console.log("recorder stops");
let blob = new Blob(chunks, {'type' : 'audio/webm'});
chunks = [];
if (debug) {
// Save the audio
let url = URL.createObjectURL(blob);
let a = document.createElement("a");
document.body.appendChild(a);
a.style = "display: none";
a.href = url;
a.download = 'test.webm';
a.click();
}
if (socket && socket.readyState === WebSocket.OPEN) {
if (!audioSent && callActive) {
console.log("sending audio");
socket.send(blob);
}
audioSent = false;
if (callActive) {
mediaRecorder.start();
}
}
}
})
.catch(function(err) {
console.log('An error occurred: ' + err);
});
}(4)语音识别
用户讲话或录制结束时,启动语音转文字操作
let recognition;
let onresultTimeout;
let onspeechTimeout;
let confidence;
function speechRecognition() {
// Initialize SpeechRecognition
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
recognition = new SpeechRecognition();
recognition.interimResults = true;
recognition.maxAlternatives = 1;
recognition.continuous = true;
recognition.onstart = function() {
console.log("recognition starts");
}
recognition.onresult = function(event) {
// Clear the timeout if a result is received
clearTimeout(onresultTimeout);
clearTimeout(onspeechTimeout);
stopAudioPlayback()
const result = event.results[event.results.length - 1];
const transcriptObj = result[0];
const transcript = transcriptObj.transcript;
const ifFinal = result.isFinal;
if (ifFinal) {
console.log(`final transcript: {${transcript}}`);
finalTranscripts.push(transcript);
confidence = transcriptObj.confidence;
socket.send(`[&]${transcript}`);
} else {
console.log(`interim transcript: {${transcript}}`);
}
// Set a new timeout
onresultTimeout = setTimeout(() => {
if (ifFinal) {
return;
}
// If the timeout is reached, send the interim transcript
console.log(`TIMEOUT: interim transcript: {${transcript}}`);
socket.send(`[&]${transcript}`);
}, 500); // 500 ms
onspeechTimeout = setTimeout(() => {
recognition.stop();
}, 2000); // 2 seconds
}
recognition.onspeechend = function() {
console.log("speech ends");
if (socket && socket.readyState === WebSocket.OPEN){
audioSent = true;
mediaRecorder.stop();
if (confidence > 0.8 && finalTranscripts.length > 0) {
console.log("send final transcript");
let message = finalTranscripts.join(' ');
socket.send(message);
chatWindow.value += `\nYou> ${message}\n`;
chatWindow.scrollTop = chatWindow.scrollHeight;
shouldPlayAudio = true;
}
}
finalTranscripts = [];
};
recognition.onend = function() {
console.log("recognition ends");
if (socket && socket.readyState === WebSocket.OPEN && callActive){
recognition.start();
}
};
}(5)语音聊天
语音聊天相关按钮事件
const talkButton = document.getElementById('talk-btn');
const textButton = document.getElementById('text-btn');
const callButton = document.getElementById('call');
const textContainer = document.querySelector('.header p');
const playerContainer = document.getElementById('player-container');
const soundWave = document.getElementById('sound-wave');
const stopCallButton = document.getElementById('stop-call');
const continueCallButton = document.getElementById('continue-call');
let callActive = false;
callButton.addEventListener("click", () => {
playerContainer.style.display = 'flex';
chatWindow.style.display = 'none';
sendButton.style.display = 'none';
messageInput.style.display = "none";
callButton.style.display = "none";
messageButton.style.display = 'flex';
if (callActive) {
stopCallButton.style.display = 'flex';
soundWave.style.display = 'flex';
} else {
continueCallButton.style.display = 'flex';
}
showRecordingStatus();
});
stopCallButton.addEventListener("click", () => {// 语音停止
soundWave.style.display = "none";
stopCallButton.style.display = "none";
continueCallButton.style.display = "flex";
callActive = false;
mediaRecorder.stop();
recognition.stop();
stopAudioPlayback();
showRecordingStatus();
})
continueCallButton.addEventListener("click", () => {// 语音继续
stopCallButton.style.display = "flex";
continueCallButton.style.display = "none";
soundWave.style.display = "flex";
mediaRecorder.start();
recognition.start();
callActive = true;
showRecordingStatus();
});
function showRecordingStatus() {
// show recording status
if (mediaRecorder.state == "recording") {
recordingStatus.style.display = "inline-block";
} else {
recordingStatus.style.display = "none";
}
}
talkButton.addEventListener("click", function() {// 语音聊天按钮
if (socket && socket.readyState === WebSocket.OPEN && mediaRecorder && selectedCharacter) {
playerContainer.style.display = "flex";
talkButton.style.display = "none";
textButton.style.display = 'none';
disconnectButton.style.display = "flex";
messageButton.style.display = "flex";
stopCallButton.style.display = "flex";
soundWave.style.display = "flex";
textContainer.textContent = "Hi, my friend, what brings you here today?";
shouldPlayAudio=true;
socket.send(selectedCharacter); // 发送选中角色ID
hideOtherCharacters();
mediaRecorder.start();
recognition.start();
callActive = true;
showRecordingStatus();
}
});
textButton.addEventListener("click", function() { // 文本聊天按钮
if (socket && socket.readyState === WebSocket.OPEN && mediaRecorder && selectedCharacter) {
messageButton.click();
disconnectButton.style.display = "flex";
textContainer.textContent = "";
chatWindow.value += "Hi, my friend, what brings you here today?\n";
shouldPlayAudio=true;
socket.send(selectedCharacter); // 发送选中角色ID
hideOtherCharacters();
showRecordingStatus();
}
});
function hideOtherCharacters() {
// Hide the radio buttons that are not selected
const radioButtons = document.querySelectorAll('.radio-buttons input[type="radio"]');
radioButtons.forEach(radioButton => {
if (radioButton.value != selectedCharacter) {
radioButton.parentElement.style.display = 'none';
}
});
}(6)文本聊天
通过回车或点击消息发送按钮进行消息发送
const messageInput = document.getElementById('message-input');
const sendButton = document.getElementById('send-btn');
const messageButton = document.getElementById('message');
const chatWindow = document.getElementById('chat-window');
const recordingStatus = document.getElementById("recording");
let characterSent = false;
messageButton.addEventListener('click', function() {
playerContainer.style.display = 'none';
chatWindow.style.display = 'block';
talkButton.style.display = 'none';
textButton.style.display = 'none';
sendButton.style.display = 'block';
messageInput.style.display = "block";
callButton.style.display = "flex";
messageButton.style.display = 'none';
continueCallButton.style.display = 'none';
stopCallButton.style.display = 'none';
soundWave.style.display = "none";
showRecordingStatus();
});
const sendMessage = () => {// 点击发送按钮事件
if (socket && socket.readyState === WebSocket.OPEN) {
const message = messageInput.value;
chatWindow.value += `\nYou> ${message}\n`;
chatWindow.scrollTop = chatWindow.scrollHeight;
socket.send(message);
messageInput.value = "";
if (isPlaying) {
stopAudioPlayback();
}
}
}
sendButton.addEventListener("click", sendMessage);
messageInput.addEventListener("keydown", (event) => {// 回车事件发送消息
if (event.key === "Enter") {
event.preventDefault();
sendMessage();
}
});(7)角色选择
websocket收到select开头的消息回调时触发createCharacterGroups。当前UI通过写死的方式进行加载显示。selectedCharacter记录当前用户选择的角色ID。
let selectedCharacter;
let radioGroupsCreated = false;
function createCharacterGroups(message) {
const options = message.split('\n').slice(1);
// Create a map from character name to image URL
// TODO: store image in database and let server send the image url to client.
const imageMap = {
'Raiden Shogun And Ei': '/static/raiden.svg',
'Loki': '/static/loki.svg',
'Ai Character Helper': '/static/ai_helper.png',
'Reflection Pi': '/static/pi.jpeg',
'Elon Musk': '/static/elon.png',
'Bruce Wayne': '/static/bruce.png',
'Steve Jobs': '/static/jobs.png',
};
const radioButtonDiv = document.getElementsByClassName('radio-buttons')[0];
options.forEach(option => {
const match = option.match(/^(\d+)\s-\s(.+)$/);
if (match) {
const label = document.createElement('label');
label.className = 'custom-radio';
const input = document.createElement('input');
input.type = 'radio';
input.name = 'radio';
input.value = match[1]; // The option number is the value
const span = document.createElement('span');
span.className = 'radio-btn';
span.innerHTML = '<i class="las la-check"></i>';
const hobbiesIcon = document.createElement('div');
hobbiesIcon.className = 'hobbies-icon';
const img = document.createElement('img');
let src = imageMap[match[2]];
if (!src) {
src = '/static/realchar.svg';
}
img.src = src;
// Create a h3 element
const h3 = document.createElement('h4');
h3.textContent = match[2]; // The option name is the text
hobbiesIcon.appendChild(img);
hobbiesIcon.appendChild(h3);
span.appendChild(hobbiesIcon);
label.appendChild(input);
label.appendChild(span);
radioButtonDiv.appendChild(label);
}
});
radioButtonDiv.addEventListener('change', (event) => {
if (event.target.value != "") {
selectedCharacter = event.target.value;
}
talkButton.disabled = false;
textButton.disabled = false;
});
radioGroupsCreated = true;
}
function destroyRadioGroups() {
const radioButtonDiv = document.getElementsByClassName('radio-buttons')[0];
while (radioButtonDiv.firstChild) {
radioButtonDiv.removeChild(radioButtonDiv.firstChild);
}
selectedCharacter = null;
radioGroupsCreated = false;
}
// This function will add or remove the pulse animation
function togglePulseAnimation() {
const selectedRadioButton = document.querySelector('.custom-radio input:checked + .radio-btn');
if (isPlaying && selectedRadioButton) {
// Remove existing pulse animations
selectedRadioButton.classList.remove("pulse-animation-1");
selectedRadioButton.classList.remove("pulse-animation-2");
// Add a new pulse animation, randomly choosing between the two speeds
const animationClass = Math.random() > 0.5 ? "pulse-animation-1" : "pulse-animation-2";
selectedRadioButton.classList.add(animationClass);
} else if (selectedRadioButton) {
selectedRadioButton.classList.remove("pulse-animation-1");
selectedRadioButton.classList.remove("pulse-animation-2");
}
}(8)音频播放
通过一个隐藏audio标签,接收服务端端发送的音频流并控制自动播放
const audioPlayer = document.getElementById('audio-player')
let audioQueue = [];
let audioContext;
let shouldPlayAudio = false;
let isPlaying = false;
// Function to unlock the AudioContext
function unlockAudioContext(audioContext) {
if (audioContext.state === 'suspended') {
var unlock = function() {
audioContext.resume().then(function() {
document.body.removeEventListener('touchstart', unlock);
document.body.removeEventListener('touchend', unlock);
});
};
document.body.addEventListener('touchstart', unlock, false);
document.body.addEventListener('touchend', unlock, false);
}
}
async function playAudios() {
isPlaying = true;
togglePulseAnimation();
while (audioQueue.length > 0) {
let data = audioQueue[0];
let blob = new Blob([data], { type: 'audio/mp3' });
let audioUrl = URL.createObjectURL(blob);
await playAudio(audioUrl);
audioQueue.shift();
}
isPlaying = false;
togglePulseAnimation();
}
function playAudio(url) {
if (!audioContext) {
audioContext = new (window.AudioContext || window.webkitAudioContext)();
unlockAudioContext(audioContext);
}
if (!audioPlayer) {
audioPlayer = document.getElementById('audio-player');
}
return new Promise((resolve) => {
audioPlayer.src = url;
audioPlayer.muted = true; // Start muted
audioPlayer.play();
audioPlayer.onended = resolve;
audioPlayer.play().then(() => {
audioPlayer.muted = false; // Unmute after playback starts
}).catch(error => alert(`Playback failed because: ${error}`));
});
}
function stopAudioPlayback() {
if (audioPlayer) {
audioPlayer.pause();
shouldPlayAudio = false;
}
audioQueue = [];
isPlaying = false;
togglePulseAnimation();
}
六.附录说明
最新代码库前端已经通过reactjs改造,不太能匹配上。附上我的当前版本源码。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











