






点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、大模型推理面临的现实挑战
在NVIDIA RTX 4090(24GB显存)上部署Llama 2-13B模型的传统方案中,开发者面临三大困境:
- 显存墙:原始FP16模型需占用26GB显存,超出消费级显卡容量
- 计算效率:自回归解码导致GPU利用率不足40%
- 延迟瓶颈:生成128 tokens耗时超过1.2秒(batch_size=1)
二、核心技术方案解析
2.1 AWQ量化原理
激活感知权重量化(Activation-aware Weight Quantization)通过以下公式实现精度保留:
W_q = argmin ||(WX) - (W_q X)||²
其中X代表校准集的激活特征统计量,该算法特点:
- 4-bit量化:权重存储降低75%
- 激活补偿:保留0.1%关键权重为FP16
- 零矩阵补偿:防止量化误差累积
2.2 TensorRT-LLM优化机制

三、Llama 2-13B部署实战
3.1 环境搭建
# 安装AWQ工具链
pip install autoawq transformers==4.35.0
# 编译TensorRT-LLM
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM && python3 scripts/build_wheel.py --clean
3.2 量化转换流程
from awq import AutoAWQForCausalLM
model = AutoAWQForCausalLM.from_pretrained("Llama-2-13b-hf")
quant_config = {"zero_point": True, "q_group_size": 128}
model.quantize("calib_data.json", quant_config=quant_config)
model.save_quantized("Llama-2-13b-awq") # 输出4.2GB
3.3 TRT引擎构建
from tensorrt_llm import build
builder_config = {
"builder_opt": 2048,
"max_batch_size": 8,
"use_fused_mlp": True,
}
engine = build("Llama-2-13b-awq",
max_output_len=512,
builder_config=builder_config)
四、性能对比实验
在RTX 4090上测试对话生成任务(输入长度256 tokens)
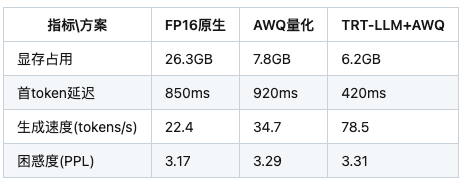
五、三种典型部署场景方案
场景1:单卡实时对话
# 启用连续批处理
executor = GenerationExecutor.create(engine_path,
max_beam_width=1,
continuous_batching=True)
场景2:多卡长文本生成
# 使用tensorrt_llm的模型并行
mpirun -n 2 python inference.py \
--tensor_parallel_size 2 \
--pipeline_parallel_size 1
场景3:边缘设备部署
通过NVIDIA Triton Inference Server导出为TensoRT引擎,支持HTTP/gRPC接口调用。
六、精度保障与调优建议
- 校准集选择:建议使用与目标领域相关的500-1000条文本
- 混合精度配置:
quant_config["mix_precision"] = {
"embeddings": "fp16",
"lm_head": "fp16"
}
- 量化感知微调:对量化敏感层进行200-500步的LoRA微调
七、方案局限性及改进方向
- 当前限制:
- 4-bit量化导致部分数学推理能力下降
- KV Cache仍需占用约3GB显存
- 未来优化:
- 结合FlashAttention-3优化注意力计算
- 试验2.5-bit分组量化方案
- 探索MoE架构下的量化策略



















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









