







一、新关键字
1、auto 和 decltype 类型推断
string name = "asdf";
auto iter = name.begin();
decltype(name) username;返回值类型后置:
template<typename T, typename U>
auto product(const T& t, const U& u) -> decltype (t* u)
{
return t * u;
}2、nullptr 空指针,替代原来的0和NULL
char *name = nullptr;
if(name==nullptr)
.......3、列表初始化
unordered_map<string, double> grades =
{
{"lily",98.5},{"lucy",90.5},{"lilei",79.8}
};4、非成员的迭代器
const char* names[]{ "Huey", "Dewey", "Louie" };
auto firstGT4 = find_if(begin(names), end(names),
[](const auto & s) {return strlen(s) > 4; });
cout << *firstGT4 << endl;
const char names[]{ 'a','b','c','d' };
auto firstc = find_if(std::begin(names), std::end(names),
[](const char a) { return a == 'c'; });std::cbegin() / std::cend();
std::rbegin / std::rend();
std::crbegin / std::crend();
5、基于范围的for循环
list<int> li ={ 10, 3, 8, 12, -54, 11, 458 };
for (auto& elt : li)
elt += 10000;
for (const auto& elt : li)
cout << elt << " "; 6、编译期的断言
static_assert(condition, “message”);
static_assert(sizeof(long long) >= 8,
"This app requires long long to be at least 64 bits.");7、noexcept,constexpr 常量表达式(在编译期间就可以计算出结果的表达式)
8、enum classes
enum class color {
red,
yellow,
green = 20,
blue
};
color::red9、类的定义
=default, =delete
override / final override函数必须在基类有定义,且为虚函数, final 修饰的成员函数不允许子类重载该虚函数,final 修饰的类不允许被继承。
定义类时初始化成员变量:
class Derived : public Base
{
public:
explicit Derived(int _age); //单参数构造函数,禁止隐性类型转换
void f(int) override;
void h(int) {};
public:
int age = 20;
static const int book = 500;
static int price = 30; //非常量不能在定义时初始化
};10、新类型,元组和字节类型。
std::get: 获得元组某个位置的值,使用一个常量表达式,也可以通过类型std::get<double>(t)
std::tuple<int, string, float, double> student{21,"lilei",98.5f,24.6};
auto s2 = std::get<2>(student);//98.5f
int age;
float math;
//解包
std::tie(age,std::ignore,math,std::ignore) = student;
string name = "name";
auto quoted_name = std::quoted(name);
double s = 49.8;
auto s3 = std::tie(age, name, math,s);//只能用变量
auto s4 = std::make_tuple(4, 5.0f, 6, 7.2);
std::byte b1{ 0b1100'1010 }; //主要操作是移位和逻辑运算
auto i2 = std::to_integer<int>(b1);
auto i3 = std::to_integer<bool>(b1);
std::byte bb11{ 42 };
std::byte bb12[] = { std::byte{43} };
//常量表达式
constexpr int bin_size = std::numeric_limits<unsigned char>::digits;
auto to_binary = std::bitset<bin_size>{ std::to_integer<unsigned char>(bb11) };
std::cout << to_binary << endl; //输出二进制
auto bb13 = static_cast<std::byte>(to_binary.to_ulong());
bb11 <<= 2;//移位
bb11 &= std::byte{ 0b11001100 };
//转换成二进制字符串
char buffer[10];
memset(buffer, 0, 10);
if (auto [ptr, ec] = std::to_chars(buffer, buffer + 9,
std::to_integer<int>(bb11), 2); ec == std::errc())
*ptr = '\0';
string out_str{ buffer };
//读取二进制文件到byte数组
string fName = "d:\\ninja-win.zip";
std::basic_ifstream<std::byte> ifs{ fName, std::ios::binary };
ifs.seekg(0, std::ios::end);
int len = ifs.tellg();
ifs.seekg(0, std::ios::beg);
std::vector<std::byte> file_content{ std::istreambuf_iterator<std::byte>(ifs), {} };
//文件读取到byte数组
FILE* fp;
if ((fp = std::fopen("d:\\ninja-win.zip", "rb")) == NULL) {
cout << "can't open this file!" << endl;
}
std::byte buffer[300];
if (std::fread(buffer, sizeof(buffer), 1, fp) != 1) {
cout << "file write error!" << endl;
}
std::fclose(fp);
std::vector<int> a{ 2,3,4,5 };
std::vector<int> b;
b.resize(a.size());
std::copy(a.begin(), a.end(), b.begin());
std::exchange(a, { 1,0,2,4 });
std::vector<int> int_v(10);
std::iota(int_v.begin(), int_v.end(), 23); //序列,每次增加1
auto result1 = std::minmax_element(int_v.begin(), int_v.end());
int min_v = *result1.first;
int max_v = *result1.second;function、可选参数optional,bind和placehold
optional<string> func(const string& in) {
if (in.size() == 0)
return nullopt; //C++ 17 中提供的没有值的 optional 的表达形式,等同于 { }
return { in + std::to_string(in.size()) };
}
auto fun3 = [](int a) {return a * 2; }; //lamda表达式
auto retval = fun3(24); //直接调用
std::function<int(int)> callback;
callback = fun3; //std::function包装lamda表达式
retval = callback(12);
int bind_func(int a, char c, float f)
{
std::cout << a << std::endl;
std::cout << c << std::endl;
std::cout << f << std::endl;
return a;
}
auto fun1 = bind(bind_func, placeholders::_1, placeholders::_2, placeholders::_3);
//占位符->第二个参数和函数第一个参数匹配(int),第三个参数和第二个参数匹配(char),第一个参数和第三个参数匹配
auto fun2 = bind(bind_func, placeholders::_2, placeholders::_3, placeholders::_1);
auto fun3 = bind(bind_func, placeholders::_1, placeholders::_2, 301.5f);
fun1(20, 'a', 101.1f);
fun2(201.6f, 30, 'b');
fun3(40, 'c');std::size_t 类型
int v[]{ 1,2,3,4,5 };
std::size_t v_size = std::size(v);二、Lambda表达式
[capture-list](parameters)mutable->return-type{statement}
关于捕捉列表,给出以下说明
[val]:表示以值传递的方式捕捉变量val
[=]:表示以值传递的方式捕捉该作用域中的全部变量,以及全局变量
[&val]:表示以引用的方式捕捉变量val
[&]:表示以引用的方式捕捉该作用域内的全部变量
[this]:表示已值传递方式捕捉当前的this指针
局部变量捕获方式:
引用捕获: [&variable1, &variable2]
值捕获和引用捕获:[variable1, &variable2]
[=] (or) [&]
[=, &variable1]
auto fun3 = [](int a) {return a * 2; }; //lamda表达式
auto retval = fun3(24); //直接调用
std::function<int(int)> callback;
callback = fun3; //std::function包装lamda表达式
retval = callback(12);三、类的构造和赋值函数
增加了移动构造函数和移动赋值函数,现有6大构造函数
class Big {
public:
Big(); // 1. default ctor
~Big(); // 2. destructor
Big(int x); // (non-canonical)
Big(const Big&); // 3. copy ctor
Big& operator=(const Big&); // 4. copy assign.
Big(Big&&); // 5. move ctor
Big& operator=(Big&&); // 6. move assign.
private:
double x; // other data…
};四、字符编码
1、不同编码的字符类型
Linux上的wchar_t是32位的,windows为16位(某些unicode字符无法表示)。三种可选的unicode编码:
utf32:一个码位固定4字节,一个码位表示一个字符编码。
utf16:兼容之前的16位编码,一个码位2字节,但1或2个码位表示一个字符编码(所以有可能会有问题)。
utf8:兼容ASCII编码,一个码位1字节,但1到6个码位表示一个字符编码。(现行标准其实要求最多4个码位,但出于保障兼容性的原因,5、6个码位的情况是可能出现的,即使这算无效编码。)
// ascii(本地)编码 对应 std::string
string str = "中国";
// 宽字符编码 对应 std::wstring
wstring wstr = L"中国";
// 16位固定宽度unicode编码, 小写字母u前缀 对应 std::u16string
u16string c16str = u"中国";
// 32位固定宽度unicode编码, 大写字母U前缀 对应 std::u32string
u32string c32str = U"中国";
// 宽度不固定多字节utf8编码,u8前缀中u为小写字母 c++17才开始支持
string u8str = u8"中国";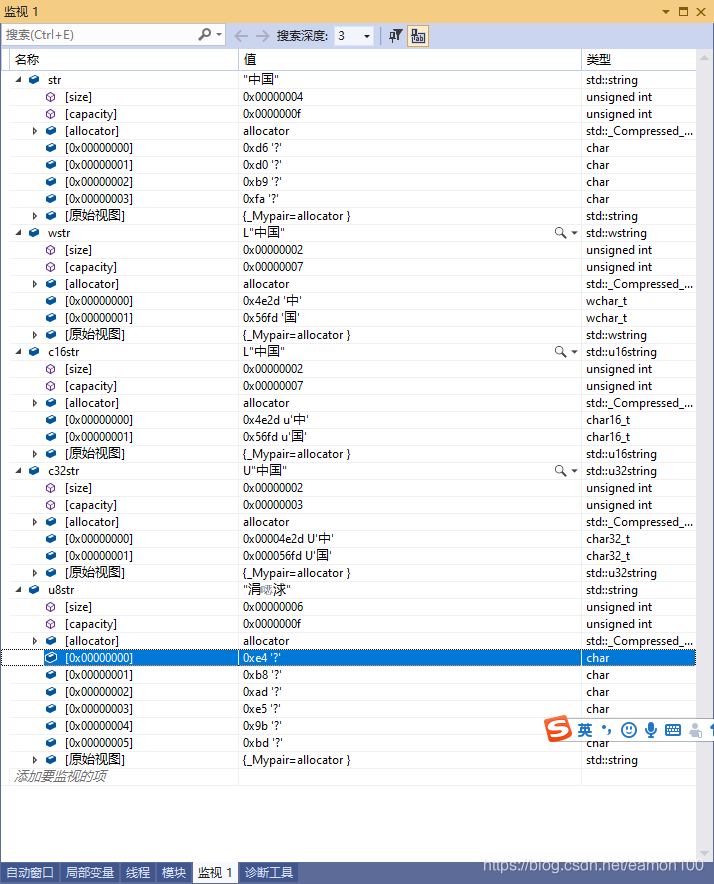
C++20中增加了 char8_t和 std::u8string对于 UTF-8提供支持,字符共五种类型。
// c++20开始支持 char8_t std::u8string
char s1 = 'a';
char8_t s2 = u8'a';
char16_t s3 = u'a';
char32_t s4 = U'a';
wchar_t s5 = L'a';
u8string u8str = u8"中国";
string u8str = u8"中国"; // 在 C++20中不再支持,需要使用u8string。2、编码转换
在C++标准提供的codecvt中,能够直接用于std::wstring_convert的只有三个:
std::codecvt_utf8,std::codecvt_utf16以及std::codecvt_utf8_utf16。
可见,标准只支持UTF族的字符编码。为了获取其它字符编码的codecvt,需要使用std::codecvt_byname,这个类可以通过字符编码的名称来创建一个codecvt。
这看起来挺不错,但遗憾的是,字符编码的名称并没有统一的标准,各个平台的支持情况都不一样。通常使用系统自定义的转换函数进行转换。
// utf-8 to utf16
std::wstring_convert< std::codecvt_utf8_utf16<char16_t>, char16_t >{}.from_bytes(str);
std::wstring_convert< std::codecvt_utf8_utf16<char16_t>, char16_t >{}.to_bytes(str16);
// utf-8 to utf32
std::wstring_convert< std::codecvt_utf8<char32_t>, char32_t >{}.from_bytes(str);
std::wstring_convert< std::codecvt_utf8<char32_t>, char32_t >{}.to_bytes(str32);
// utf-8 to wstring
std::wstring_convert< std::codecvt_utf8<wchar_t>, wchar_t >{}.from_bytes(str);
std::wstring_convert< std::codecvt_utf8<wchar_t>, wchar_t >{}.to_bytes(wstr);std::wstring_convert 与 std::codecvt_utf8 在 C++17 中已经被标记为弃用。可以使用ICU4C库进行编码转换。
International Components for Unicode (ICU) - Win32 apps | Microsoft Docs
On Windows 10 Version 1709 and above, you should include the combined header instead:#include <icu.h> , link : icu.lib
五、数值表示和转换
1、不同进制的数值表示
2进制、8进制,16进制表示175:
int a1 = 0b1010'1111;
int a2 = 0b10101111; //二进制
int a3 = 0xaf; //16进制
int a4 = 0257; //8进制
long long a5; //至少64位的长整形2、字符串和数值类型转换
std::string s{"123"};
int i{ std::stoi(s) };c++11标准在string 头文件提供了 stol()、stoll() 、stoul()、stoull()、stof()、stod() 和 stold() 函数,它们都包含在 std 名称空间中,可分别将字符串转换为 long、long long、unsigned long、unsigned long long、float、double 和 long double 类型。
c++11标准增加了全局函数std::to_string,将整数、浮点数转换成string类型:
string to_string (int val);
string to_string (long val);
string to_string (long long val);
string to_string (unsigned val);
string to_string (unsigned long val);
string to_string (unsigned long long val);
string to_string (float val);
string to_string (double val);
string to_string (long double val);
std::string pi = std::to_string(3.1415926); C++17标准增加了整数、浮点数与字符串的转换函数: std::from_chars和std::to_chars
std::array<char, 10> str2;
if (auto [ptr, ec] = std::to_chars(str2.data(), str2.data() + str2.size(),
-3.14159, std::chars_format::fixed); ec == std::errc())
std::cout << std::string_view(str2.data(), ptr) << '\n';
else
std::cout << std::make_error_code(ec).message() << '\n';
if (auto [ptr, ec] = std::to_chars(str2.data(), str2.data() + str2.size(),
-3.14159, std::chars_format::scientific, 3); ec == std::errc())
std::cout << std::string_view(str2.data(), ptr) << '\n';
else
std::cout << std::make_error_code(ec).message() << '\n';六、字面量
1、字符串字面量
- 对于raw(未处理的)字符串字面量是形式是R"定界()定界",其中定界是可选的,因为默认()是一对定界符,这里的额外的定界是为了标记定界括号用的,例如:
上面的由于无定界符所以在123后面的)"会被当作字符串结尾,但是存在定界符:char str[] = R"((123)")";
此时未出理的字符串内容就是(123)"了,因为标记范围已经明确.char str[] = R"...((123)")..."; char32_t str3[] = UR"...((123)")...";
2、浮点字面量
概要:十六进制浮点数字面量
注释:具有十六进制底数和十进制指数的浮点数字面量:0xC.68p+2、0x1.P-126。C语言自从C99开始就支持这种语法, printf的%a可以输出这种形式的浮点数。
后缀 若存在,则为 f、F、l 或 L 之一。后缀决定浮点字面量的类型:
- (无后缀)定义 double
f F定义 floatl L定义 long double
数位间可插入作为分隔符的单引号('),在编译时忽略它们。 | (C++14 起) |
浮点数类型有如下三种:
| 类型 | 所占字节数 |
|---|---|
| float | 4 |
| double | 8 |
| long double | 8 |
浮点数字面量的默认识别类型是double,可以通过F、L后缀将一个浮点数字面量转化为其他类型。
使用十进制科学计数法,表示浮点字面量的值是有效数字乘以 10 的 指数 次幂。123e4 的数学含义是 123×104
| 若浮点字面量以字符序列 对于十六进制浮点字面量,其有效数字被解释为十六进制有理数,而指数的 数字序列 被解释成有效数字要放大的 2 的整数幂次。 | (C++17 起) |
示例: 0xC.68p+3; = (12 + 6/16 + 8/16/16 )*2^3
浮点数转化为二进制有它自己的规则:
1.浮点数的整数部分,仍按照整数转二进制的规则,除2取余(直到余数为0),倒序排列
2.浮点数的小数部分,采用乘2取整(直到小数部分为0),正序排列
例如123.45整数部分和小数部分分别转化为二进制串:
可见,整数部分一定能完全转化为二进制串(余数总会归0),但小数部分不一定能完全转化为二进制串(小数部分不一定归0)。因此,计算机是不能完全表示浮点数的(显然当小数部分是1 / 2^n时可以完全转化,但仍要考虑存储宽度的问题,因为可能要很多位才能完全表示这个小数部分),这就涉及到表示的浮点数的精度问题。
实际上一个浮点数通过上述方法分别计算出整数部分和小数部分二进制串之后并不能直接存储到计算机中,因为这样至少要能标志小数点的位置。
实际存储到计算机中的浮点数二进制串是经过IEEE754标准生成的,二进制串包括符号位、指数部分、位数部分,具体可以参考IEEE754标准。
3.自定义字面值
(1)前缀
//前缀
int a1 = 0123; //8进制
int a2 = 0x12; //16进制
int b1 = 0b10101; //2进制(2)系统预定义后缀
整形、浮点型后缀
//后缀
unsigned int a3 = 12u;
long a4 = 12322l;
long long a5 = 23424ll;
float a6 = 12.3f;字符串后缀
string s_1 = "dg\0d\0g"s;
string s_2 = "dg\0d\0g";
string_view sv_1 = "sd\0fs\0df v"sv;
string_view sv_2 = "sd\0fs\0df v"; 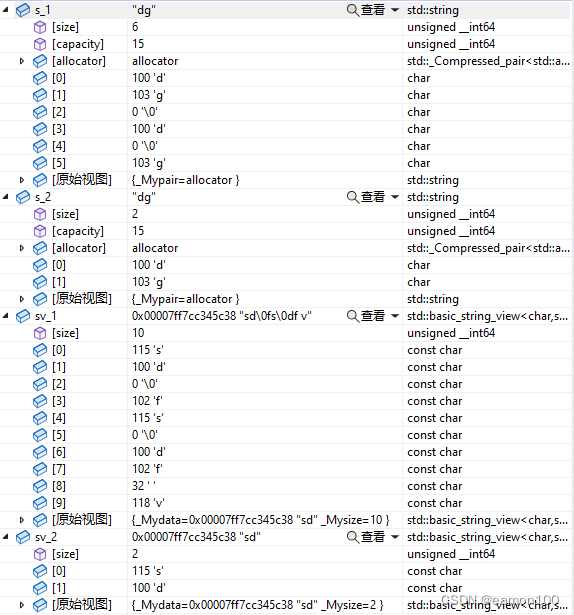
时间后缀
用户定义的后缀以_开头。使用了using namespace std::literals;之后,我们可以3s直接表示3秒、3ms表示3毫秒、3h表示3小时。literals 和 chrono_literals 是内联命名空间。
year : operator""y
day : operator""d
hours : operator""h
minutes : operator""min
seconds : operator""s
milliseconds : operator""ms
microseconds : operator""us
nanoseconds : operator""ns(3)自定义后缀,通过重载“”运算符
//单位为千米,返回米
long double operator "" _km(long double s)
{
return s * 1000;
}
auto s = 23.5_km;七、新的容器类型
1、容器
std::array 传统数组
std::forward_list 单向链表
std::unordered_map 哈希表
std::unordered_set 哈希集合
2、结构化绑定
std::map<int, std::string> mymap = { {1, "el"}, {3, "tom"}, {4, "nic"} };
//修改容器的值
for (auto& [key, value] : mymap)
{
if (key == 1)
value = value + "_new"s;
}
//绑定到数组
int i_val[2]{ 1,3 };
auto& [i, j] = i_val;
i = 20;
int newi = i_val[0];
//绑定到std::tuples 和 std::pair
std::tuple<char, float, std::string> tp('1', 6.6f, "hello");
auto [a, b, c] = tp;
//绑定到返回值
std::map<std::string, int> coll;
auto [pos, ok] = coll.insert({ "new",42 });
if (ok) {
}八、C++20的文本格式化
文本格式化库提供 printf 函数族的安全且可扩展的替用品。有意使之补充既存的 C++ I/O 流库并复用其基础设施。C++20提供了std::format全局函数,提供媲美Python的文本格式化支持。需要包含头文件 : #include <format>。
1、函数重载定义
template<class... Args>
std::string format(std::string_view fmt, const Args&... args);
template<class... Args>
std::wstring format(std::wstring_view fmt, const Args&... args);
template<class... Args>
std::string format(const std::locale& loc, std::string_view fmt, const Args&... args);
template<class... Args>
std::wstring format(const std::locale& loc, std::wstring_view fmt, const Args&... args);按照格式字符串 fmt 格式化 输出参数 args ,并返回作为 string 的结果。 loc 若存在,则用于本地环境特定的格式化。
输入参数说明:
fmt - 表示格式字符串的字符串视图。
格式字符串由以下内容组成:
- 通常字符(除了 { 与 } ),它们被不加修改地复制到输出
- 转义序列 {{ 与 }} ,它们在输出中被分别替换成 { 与 }
- 替换域
每个替换域拥有下列格式: {arg-id:格式说明}
(可选) arg-id ,一个非负数
(可选) 冒号( : )后随格式说明
arg-id 指定用于格式化其值的 args 中的参数的下标;若省略 arg-id ,则按顺序使用参数。格式字符串中的 arg-id 必须全部存在或全部被省略,混合手动和自动指定下标是错误。
格式说明由对应参数特化的 std::formatter 定义。
- 对于基本类型和标准字符串类型,格式说明为标准格式说明
- 对于标准日期和时间类型,格式说明为 chrono 格式说明
- 对于用户定义类型,格式说明由用户定义的 std::formatter 特化决定
args… - 要格式化的参数
loc - 用于本地环境特定格式化的 std::locale
返回值
保有格式化结果的 string 对象。
异常
若 fmt 对于提供的参数不是合法的格式字符串则抛出 std::format_error 。并且会传播任何格式化器所抛的异常。
注意,提供多于格式字符串所要求的参数不是错误:
std::format("{} {}!", "Hello", "world", "something");
// OK :产生 "Hello world!"简单示例:
#include <format>
#include <cassert>
int main() {
std::string message = std::format("The answer is {}.", 42);
assert( message == "The answer is 42." );
}标准格式说明:
基本格式:
填充与对齐(可选) 符号(可选) #(可选) 0(可选) 宽度(可选) 精度(可选) L(可选) 类型(可选)
符号 、 # 及 0 选项仅当使用整数或浮点显示类型时合法。
填充与对齐
一个可选的填充字符(可为任何 { 或 } 外的的字符),后随对齐选项 < 、 > 、 ^ 之一。对齐选项的意义如下:
< :强制域在可用空间内左对齐。这在使用非整数非浮点显示类型时为默认。
> :强制域在可用空间内右对齐。这在使用整数或浮点显示类型时为默认。
^ :强制域在可用空间中央,通过在值的前面插入n/2向下取整个字符,后面插入n/2向上取整个字符,其中 n 是待插入的总字符数。
char c = 120;
auto s0 = std::format("{:6}", 42); // s0 的值为 " 42"
auto s1 = std::format("{:6}", 'x'); // s1 的值为 "x "
auto s2 = std::format("{:*<6}", 'x'); // s2 的值为 "x*****"
auto s3 = std::format("{:*>6}", 'x'); // s3 的值为 "*****x"
auto s4 = std::format("{:*^6}", 'x'); // s4 的值为 "**x***"
auto s5 = std::format("{:6d}", c); // s5 的值为 " 120"
auto s6 = std::format("{:6}", true); // s6 的值为 "true "符号、 # 与 0
符号 选项能为下列之一:
- + :指示符号应该一同用于非负数和负数。在非负数的输出值前插入 + 号。
- - :指示符号应该仅用于负数(这是默认行为)。
- 空格:指示应对非负数使用前导空格,而对负数使用负号。
负零被当作负数。符号 选项应用于浮点无穷大和 NaN 。
double inf = std::numeric_limits<double>::infinity();
double nan = std::numeric_limits<double>::quiet_NaN();
auto s0 = std::format("{0:},{0:+},{0:-},{0: }", 1); // s0 的值为 "1,+1,1, 1"
auto s1 = std::format("{0:},{0:+},{0:-},{0: }", -1); // s1 的值为 "-1,-1,-1,-1"
auto s2 = std::format("{0:},{0:+},{0:-},{0: }", inf); // s2 的值为 "inf,+inf,inf, inf"
auto s3 = std::format("{0:},{0:+},{0:-},{0: }", nan); // s3 的值为 "nan,+nan,nan, nan"# 选项导致将替用形式用于转换。
- 对于整数类型,使用二进制、八进制或十六进制显示类型时,替用形式插入前缀(
0b、0或0x)到输出值中,若有符号则于符号(可为空格)前,否则于输出值前。 - 对于浮点类型,替用形式导致有限值的转换结果始终含有小数点字符,即使其后无数位。正常情况下,小数点字符仅若有数位后随它才出现于转换结果。另外,对于
g与G转换,不从结果移除尾随的零。
0 选项以前导零填充域(后随任何符号或底)到域宽,除了应用到无穷大或 NaN 时。若 0 字符与对齐选项一同出现,则忽略 0 字符。
char c = 120;
auto s1 = std::format("{:+06d}", c); // s1 的值为 "+00120"
auto s2 = std::format("{:#06x}", 0xa); // s2 的值为 "0x000a"
auto s3 = std::format("{:<06}", -42); // s3 的值为 "-42 " (因 < 对齐忽略 0 )宽度与精度
宽度 为正十进制数,或嵌套的替换域( {} 或 {n} )。宽度若存在则指定最小域宽。
精度 为点( . )后随非负十进制数或嵌套的替换域。此域指示精度或最大域大小。它仅能用于浮点与字符串类型。对于浮点类型,此域指定格式化精度。对于字符串类型,它提供要复制到输出的字符串前缀的估计宽度(见后述)的上界。对于以 Unicode 编码的字符串,复制到输出的文本是整个扩展字素集群的,使得估计宽度不大于精度的最长前缀。
若 宽度 或 精度 中使用嵌套的替换域,而对应的参数不是整数类型,或为负,或对于 宽度 为零,则抛出 std::format_error 类型异常。
float pi = 3.14f;
auto s1 = std::format("{:10f}", pi); // s1 = " 3.140000" (宽度 = 10 )
auto s2 = std::format("{:{}f}", pi, 10); // s2 = " 3.140000" (宽度 = 10 )
auto s3 = std::format("{:.5f}", pi); // s3 = "3.14000" (精度 = 5 )
auto s4 = std::format("{:.{}f}", pi, 5); // s4 = "3.14000" (精度 = 5 )
auto s5 = std::format("{:10.5f}", pi); // s5 = " 3.14000"
// (宽度 = 10 ,精度 = 5 )
auto s6 = std::format("{:{}.{}f}", pi, 10, 5); // s6 = " 3.14000"
// (宽度 = 10 ,精度 = 5 )
auto b1 = std::format("{:{}f}", pi, 10.0); // 抛出:宽度不是整数类型
auto b2 = std::format("{:{}f}", pi, -10); // 抛出:宽度为负
auto b3 = std::format("{:.{}f}", pi, 5.0); // 抛出:精度不是整数类型
对于字符串类型,宽度定义为适合将它显示到终端的估计列位置数值。
就宽度计算目的,假设字符串用实现定义的编码。宽度计算的方法是未指定的,但对于以 Unicode 的字符串,实现应该估计字符串的宽度为其扩展字素集群中首个码位的估计宽度之和。若 Unicode 码位在下列范围内,则估计宽度为 2 ,否则为 1 :
- U+1100 - U+115F
- U+2329 - U+232A
- U+2E80 - U+303E
- U+3040 - U+A4CF
- U+AC00 - U+D7A3
- U+F900 - U+FAFF
- U+FE10 - U+FE19
- U+FE30 - U+FE6F
- U+FF00 - U+FF60
- U+FFE0 - U+FFE6
- U+1F300 - U+1F64F
- U+1F900 - U+1F9FF
- U+20000 - U+2FFFD
- U+30000 - U+3FFFD
auto s1 = std::format("{:.^5s}", "🐱"); // s1 = ".🐱.."
auto s2 = std::format("{:.5s}", "🐱🐱🐱"); // s2 = "🐱🐱"
auto s3 = std::format("{:.<5.5s}", "🐱🐱🐱"); // s3 = "🐱🐱."L (本地环境特定的格式化)
L 选项导致使用本地环境特定的形式。此选项仅对算术类型合法。
- 对于整数类型,本地环境特定形式按照环境的本地环境,插入适合的数位组分隔字符。
- 对于浮点类型,本地环境特定形式按照环境的本地环境,插入适合的数位组和底分隔字符。
- 对于
bool的文本表示,本地环境特定形式使用如同通过 std::numpunct::truename 或 std::numpunct::falsename 获得的字符串。
类型
类型 选项确定应该如何显示数据。
可用的字符串显示类型为:
- 无、
s:复制字符串到输出。
可用的 char 、 wchar_t 与 bool 外的整数类型的整数显示类型为:
b:二进制格式。如同通过调用 std::to_chars(first, last, value, 2) 产生输出。底前缀为0b。B:同b,除了底前缀为0B。c:复制字符 static_cast<CharT>(value) 到输出,其中 CharT 是格式字符串的字符类型。若值不在 CharT 的可表示值的范围中则抛出 std::format_error 。d:十进制格式。如同通过调用 std::to_chars(first, last, value) 产生输出。o:八进制格式。如同通过调用 std::to_chars(first, last, value, 8).产生输出。若对应参数值非零则底前缀为0,否则为空。x:十六进制格式。如同通过调用 std::to_chars(first, last, value, 16) 产生输出。底前缀为0x。X:同x,除了对 9 以上的数字使用大写字母且底前缀为0X。- 无:同
d。
可用的 char 及 wchar_t 表示类型为:
- 无、
c:复制字符到输出。 b、B、d、o、x、X:使用整数表示类型。
可用的 bool 表示类型为:
- 无、
s:复制文本表示(true或false或本地环境特定形式)到输出。 b、B、c、d、o、x、X:以值static_cast<unsigned char>(value)使用整数表示类型。
可用的浮点表示类型为:
a:若指定精度,则如同通过调用 std::to_chars(first, last, value, std::chars_format::hex, precision) 产生输出,其中precision是指定的精度,否则如同通过 std::to_chars(first, last, value, std::chars_format::hex) 产生输出。A:同a,除了对 9 以上的数字使用大写字母并用P指示指数。e:如同通过调用 std::to_chars(first, last, value, std::chars_format::scientific, precision) 产生输出,其中precision为指定的精度,或若未指定精度则为 6 。E:同e,除了用E指示指数。f、F:如同通过调用 std::to_chars(first, last, value, std::chars_format::fixed, precision) 产生输出,其中precision为指定的精度,或若未指定精度则为 6 。g:如同通过调用 std::to_chars(first, last, value, std::chars_format::general, precision) 产生输出,其中precision为指定的精度,或若未指定精度则为 6 。G:同g,除了用E指示指数。- 无:若指定精度,则如同通过调用 std::to_chars(first, last, value, std::chars_format::general, precision) 产生输出,其中
precision为指定的精度;否则如同通过调用 std::to_chars(first, last, value) 产生输出。
对于小写表示类型,分别格式化无穷大和 NaN 为 inf 与 nan 。对于大写表示类型,分别格式化无穷大和 NaN 为 INF 与 NAN 。
可用的指针表示类型(亦用于 std::nullptr_t )为:
- 无、
p:若定义 std::uintptr_t ,则如同通过调用 std::to_chars(first, last, reinterpret_cast<std::uintptr_t>(value), 16) 产生输出,并添加前缀0x到输出;否则输出为实现定义。
2、时间文本格式化
参考: std::formatter - cppreference.com https://zh.cppreference.com/w/cpp/chrono/system_clock/formatter#.E6.A0.BC.E5.BC.8F.E8.AF.B4.E6.98.8E格式说明
https://zh.cppreference.com/w/cpp/chrono/system_clock/formatter#.E6.A0.BC.E5.BC.8F.E8.AF.B4.E6.98.8E格式说明
格式说明拥有形式
填充与对齐(可选) 宽度(可选) 精度(可选) L(可选) 时间说明(可选)
填充与对齐、 宽度 及 精度 拥有同标准格式说明中的含义。
精度 仅对表示类型 Rep 为浮点类型的 std::chrono::duration 类型合法,否则抛出 std::format_error 。
L 用于格式化的本地环境确定如下:
- 若格式说明中不存在
L则为默认的 "C" 本地环境, - 否则,若有传递给格式化函数的 std::locale 则为其所代表的本地环境,
- 否则(
L存在但无传递给格式化函数的 std::locale )为全局本地环境。
时间说明 由一或更多个转换说明符与通常字符(除了 {、 } 与 % )构成。 时间说明 必须始于一个转换说明符。写入所有通常字符到输出而不修改。每个无修饰的转换说明符始于 % 字符后随一个确定说明符行为的字符。某些转换说明符拥有修饰形式,其中 E 或 O 修饰字符插入到 % 字符后。按描述于下的方式以适合的字符替换每个转换说明符。
若 时间说明 为空,则如同以流化时间对象到 std::stringstream 类型对象 os ,感染格式化本地环境( std::locale::classic()、传递的 std::locale 对象和 std::locale::global() 之一)后复制 os.str() 到输出缓冲,附带按照每个格式说明符的填充和调整一般,格式化时间对象。
下列格式说明符可用:
| 转换说明符 | 解释 |
| %% | 写字面的 % 字符。 |
| %n | 写换行符。 |
| %t | 写水平制表符。 |
| 年 | |
|---|---|
| %C | 写年除以 100 向下取整除的结果。若结果为单个十进制位,则前附 0 。 |
| %EC | 修饰的命令 %EC 写本地环境的替用世纪表示。 |
| %y | 写年的末二位十进制数。若结果为单个数位,则前附 0 。 |
| %Oy | 修饰的命令 %Oy 写本地环境的替用表示。 |
| %Ey | 修饰的命令 %Ey 写距 %EC 的偏移(仅年)的本地环境替用表示。 |
| %Y | 按十进制数写年。若结果少于四位,则左填充 0 到四位。 |
| %EY | 修饰的命令 %EY 写本地环境的替用完整年表示。 |
| 月 | |
| %b | 写本地环境的缩写月名。 |
| %h | |
| %B | 写本地环境的完整月名。 |
| %m | 按十进制数写月份(一月为 01 )。若结果为单个数位,则前附 0 。 |
| %Om | 修饰的命令 %Om 写本地环境的替用表示。 |
| 日 | |
| %d | 按十进制数写月之日。若结果为单个十进制位,则前附 0 。 |
| %Od | 修饰的命令 %Od 写本地环境的替用表示。 |
| %e | 按十进制数写月之日。若结果为单个十进制位,则前附空格。 |
| %Oe | 修饰的命令 %Oe 写本地环境的替用表示。 |
| 星期日 | |
| %a | 写本地环境的缩写星期名。 |
| %A | 写本地环境的完整星期名。 |
| %u | 按十进制数写 ISO 星期之日( 1-7 ),其中星期一为 1 。 |
| %Ou | 修饰的命令 %Ou 写本地环境的替用表示。 |
| %w | 写星期之日为十进制数( 0-6 ),其中星期日为 0 。 |
| %Ow | 修饰的命令 %Ow 写本地环境的替用表示。 |
| 基于 ISO 8601 星期的年 | |
| ISO 8601 星期始于星期一而年的第一星期必须满足下列要求:
| |
| %g | 写基于 ISO 8601 星期的年的后二位十进制数。若结果为单个数位,则前附 0 。 |
| %G | 按十进制数写基于 ISO 8601 星期的年。若结果少于四位,则左填充 0 到四位。 |
| %V | 按十进制数年的 ISO 8601 星期。若结果为单个数位,则前附 0 。 |
| %OV | 修饰的命令 %OV 写本地环境的替用表示。 |
| 年之星期/日 | |
| %j | 按十进制数写年的日( 1 月 1 日为 001 )。若结果少于三位,则左填充 0 到三位。 |
| %U | 按十进制数写年的星期数。该年的首个星期日为 01 星期的首日。同年中之前的日在 00 星期中。若结果为单个数位,则前附 0 。 |
| %OU | 修饰的命令 %OU 写本地环境的替用表示。 |
| %W | 按十进制数写年的星期数。该年的首个星期一为 01 星期的首日。同年中之前的日在 00 星期中。若结果为单个数位,则前附 0 。 |
| %OW | 修饰的命令 %OW 写本地环境的替用表示。 |
| 日期 | |
| %D | 等价于 "%m/%d/%y" 。 |
| %F | 等价于 "%Y-%m-%d" 。 |
| %x | 写本地环境的日期表示。 |
| %Ex | 修饰的命令 %Ex 产生本地环境的替用日期表示。 |
| 当天时刻 | |
| %H | 按十进制数字写时( 24 小时时钟)。若结果为单个数位,则前附 0 。 |
| %OH | 修饰的命令 %OH 写本地环境的替用表示。 |
| %I | 按十进制数字写时( 12 小时时钟)。若结果为单个数位,则前附 0 。 |
| %OI | 修饰的命令 %OI 写本地环境的替用表示。 |
| %M | 按十进制数字写分。若结果为单个数位,则前附 0 。 |
| %OM | 修饰的命令 %OM 写本地环境的替用表示。 |
| %S | 按十进制数字写秒。若结果为单个数位,则前附 0 。 |
| %OS | 若输入的精度不能准确地以秒表示,则格式为 fixed 格式且精度匹配输入精度的十进制浮点数(或若不能在 18 位小数内转换到浮点数十进制秒,则为到微秒精度)。用作小数点的字符按照本地环境本地化。 |
| 修饰的命令 %OS 写本地环境的替用表示。 | |
| %p | 写与 12 小时时钟相关的 AM/PM 设计的本地环境版本。 |
| %R | 等价于 "%H:%M" 。 |
| %T | 等价于 "%H:%M:%S" 。 |
| %r | 写本地环境的 12 小时时钟时间。 |
| %X | 写本地环境的时间表示。 |
| %EX | 修饰的命令 %EX 写本地环境的替用时间表示。 |
| 时区 | |
| %z %Ez %Oz | 以 ISO 8601 格式写自 UTC 的偏移。例如 -0430 表示 UTC 后 4 小时 30 分。若偏移为 0 ,则使用 +0000 。 修饰的命令 %Ez 与 %Oz 在时与分间插入 : (例如 -04:30 )。 |
| %Z | 写时区缩写。 |
| 杂项 | |
| %c | 写本地环境的日期与时间表示。 |
| %Ec | 修饰的命令 %Ec 写本地环境的替用日期与时间表示。 |
下列说明符得到辨识,但会导致抛出 std::format_error :
| 转换 说明符 | 解释 |
|---|---|
| 时长计数 | |
%Q | 写时长的计次数,即经由 count() 获得的值。 |
%q | 写 operator<<() 中指定的时长单位后缀。 |
示例:
using namespace std;
auto a = chrono::system_clock::now();
auto b = chrono::time_point_cast<chrono::seconds>(a);
string nowtime = format("{0:%Y-%m-%d %H:%M:%S}", chrono::floor<seconds>(a));
cout << format("Now : {0:%F}T{0:%T} - ", a) <<a.time_since_epoch().count()<< endl;
cout << format("Now : {0:%F}T{0:%T} - ", b) <<b.time_since_epoch().count()<< endl;
std::map<string, string> time_map;
auto utc_time = utc_clock::now();
auto sys_time = chrono::floor<seconds>(chrono::system_clock::now());
auto local_time = zoned_time(current_zone(), sys_time).get_local_time();
auto two_days_ageo = local_time - 48h;
string current_time = std::format("{0:%Y-%m-%d %H:%M:%S}",local_time);
time_map.insert_or_assign("utc_time", std::format("{0:%Y-%m-%d %H:%M:%S}", utc_time));
time_map.insert_or_assign("sys_time", std::format("{0:%Y-%m-%d %H:%M:%S}", sys_time));
time_map.insert_or_assign("local_time", std::format("{0:%Y-%m-%d %H:%M:%S}", local_time));
time_map.insert_or_assign("two_days_ageo", std::format("{0:%Y-%m-%d %H:%M:%S}", two_days_ageo));
std::erase_if(time_map, [¤t_time](const auto& p) {
auto const& [key, value] = p;//解包,C++17 结构化绑定
return value == current_time;
});输出:
Now : 2023-01-22T13:32:26.9696865 - 16743943469696865
Now : 2023-01-22T13:32:26 - 1674394346
G++目前不支持std::format函数,需要13.0以上版本,预计2023年4月发布。
九、时间库 std::chrono
1、时钟
chrono::system_clock::now(); //操作系统的时钟
chrono::steady_clock::now(); //不随系统时间修改而改变的时钟
chrono::utc_clock::now();//包含闰秒
chrono::high_resolution_clock::now();
chrono::tai_clock::now(); //原子钟
chrono::file_clock::now();
chrono::gps_clock::now(); 2、时长
duration<double, std::milli> ms3k(3000);
auto ms3k_seconds = duration_cast<seconds>(ms3k);
auto t = ms3k + 2s;3、时间点
const time_point<system_clock> now = system_clock::now();
auto now_seconds = time_point_cast<seconds>(now);
auto now_day = time_point_cast<days>(now);
//时间dian
chrono::year_month_day ymd{ year(2021), month(9), day(20) };
auto tp = sys_days{ ymd };
auto ymd2 = ymd + months(12);
auto ymd2 = 2021y / September / 20d;4、格式化
auto a2 = chrono::system_clock::now();
string nowtime = std::format("{0:%Y-%m-%d %H:%M:%S}", chrono::floor<seconds>(a2));
chrono::time_point<system_clock,seconds> tp2;
stringstream ss{"2023-10-25 10:20:30"};
//Gcc13中未定义,VS2022可以使用
ss>>std::chrono::parse("%Y-%m-%d %H:%M:%S",tp2);
if (!ss.fail())
{
//计算结果长度
size_t len = std::formatted_size("{0:%Y-%m-%d %H:%M:%S}", tp2);
std::vector<char> buf(len);
std::format_to_n(buf.data(), len, "{0:%Y-%m-%d %H:%M:%S}", tp2);
string nowtime = std::format("{0:%Y-%m-%d %H:%M:%S}", tp2);
}
std::chrono::sys_seconds tp{ std::chrono::seconds{1683656751ull} };
std::vformat("{0: % F}T{0: % T}"sv, std::make_format_args(tp));十、其他
1、比率
std::ratio<8, 12> m2_3;
std::ratio<1, 4> m1_4;
m2_3.den; //分母(denominator) 3
m2_3.num; //分子(numerator) 22、去除白字符
string& trim(string& source)
{
const string ws = " \r\n\t\f\v"s;
return source.erase(source.find_last_not_of(ws) + 1).erase(0, source.find_first_not_of(ws));
}
//使用
string sss = " \t my name is jack! \n\r\v"s;
trim(sss);
cout << sss << endl;














 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









