







RNN应用中存在的问题是,每一个RNN Cell的state都取决于前一个RNN Cell的state,因此RNN很难采用并行计算,计算的速度往往较慢。但是RNN的优势是,能够依据attention利用输入句子的全部信息。所以就有人提出,如果只用attention,不用RNN是否可行,这就是2017年的一篇论文提出的解决方案(原文)。

该神经网络的优势是,采用了非Recurrent的Encoder-decoder结构,这样就可以在GPU中充分利用并行计算的优势提高运算速度。
- 首先的input向量和其对应的output向量都要经过Positional Encoding,Positional Encoding相当于给每个向量附加上了位置信息,即
P E ( p o s , i ) = { s i n ( p o s / 1000 0 i / d m o d e l ) i为偶数 c o s ( p o s / 1000 0 ( i − 1 ) / d m o d e l ) i为奇数 PE(pos, i)=\begin{cases} sin(pos/10000^{i/d_{model}}) & \text{i为偶数} \\ cos(pos/10000^{(i-1)/d_{model}}) & \text{i为奇数} \end{cases} PE(pos,i)={sin(pos/10000i/dmodel)cos(pos/10000(i−1)/dmodel)i为偶数i为奇数
其中pos为向量在句子中的第几个位置, d m o d e l d_{model} dmodel为词向量的维度, i i i为对应的在词向量的第几个位置。 - Multihead attension是整个模块的关键。该模块会将输入的分量中内部多个不同的词之间进行相关性的计算。这个和RNN里的attention机制是类似的。首先看attention。
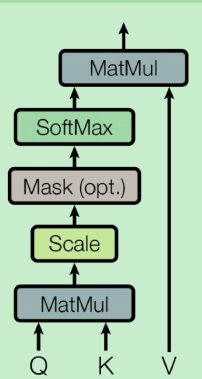
其中,attention会将输入的三个分量 Q , K , V \mathbf{Q, K, V} Q,K,V进行运算,得到
A ( Q , K , V ) = s o f t m a x ( Q K T d k ) V A(\mathbf{Q, K, V})=softmax(\frac{\mathbf{QK}^T}{\sqrt{d_k}})\mathbf V A(Q,K,V)=softmax(dkQKT)V
这里 Q \mathbf Q Q可以看成query, K , V \mathbf{K,V} K,V看成一个(key,value)的pair。对于 Q \mathbf Q Q的每一行的分量 q \mathbf q q,实际上计算的是
A ( q , K , V ) = ∑ i e q k i T ∑ j e q k i T v i A(\mathbf{q, K, V})=\sum_i \frac{e^{\mathbf{qk_i^T}}}{\sum_j e^{\mathbf{qk_i^T}}}\mathbf v_i A(q,K,V)=i∑∑jeqkiTeqkiTvi
即对 V \mathbf V V的每一行求了一个加权平均,而加权平均的权重取决于query和key的相关度。同时为了避免 q \mathbf q q的长度 d k d_k dk过长,导致和 q v i T \mathbf {qv_i^T} qviT的某些值太大,因此取了一个normalization。而"Multihead"的attention,则是为 Q , K , V \mathbf{Q, K, V} Q,K,V提供了多种“体位”下的attention,即
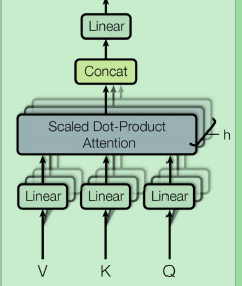
即对 Q , K , V \mathbf{Q, K, V} Q,K,V进行了多种方式的线性变换,得到 Q i , K i , V i \mathbf{Q_i, K_i, V_i} Qi,Ki,Vi。再对每一组 i i i,进行attention,得到输出结果,再Concat起来。 - Add的操作和ResNet类似,将输出和模块的输入进行相加,解决深层网络的梯度消失的问题。LayerNorm则是对输出的每一个句子的每一个词的向量进行了标准化。
- FeedForward是一个简单的fully connected network。
- 对于每一个Encoder,multihead attention+Add&Norm+Feed Forward+Add&Norm共同构成了一个Encoder的子层,然后再构建 N N N个这样这样的子层。在论文里, N = 6 N=6 N=6。将最高的子层的输出作为Decoder的一个输入。
- Decoder端和Encoder相似,有两个模块是专门处理Output的,而中间的模块则是“合并”Encoder的输出和Output的,这三个模块共同组成了一个子层。在论文里,同样Decoder也有 N = 6 N=6 N=6个这样的子层。
这里Decoder的训练和测试输入是不相同的。训练时,Decoder的输入是Input的batch对应的output的batch。而测试时,Decoder先输入一个句子的开始标志,算出句子的一个单词是哪一个。然后再将开始标志和输出的单词共同再组成Decoder的输入,依次类推,直到达到最大的句子长度或输出结束标志为止。这种做法是的RNN是很接近的。
除了上述之外,论文也做了其它的优化,这里就不再详述了。














 2213
2213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









