









自然语言处理 - 要代替 RNN、LSTM 的 Transformer
Seq2Seq 模型,通常来讲里面是由 RNN、GRU、LSTM 的 cell 来组建的,但最近 Google 推出了一个新的架构 Transformer. 这个模型解决了 Seq2Seq 模型依赖之前结果无法并行的问题,而且最终的效果也是非常棒。
已经这么详细的翻译了,我这里为自己总结一下关键点。
-
Transformer 结构
Seq2Seq 模型是这个样子的:

Transformer 的宏观结构也是这样的,不同的是内部的微观结构。它里面又多个 Encoder 或 多个 Decoder 组成,而每个 Coder 内部又拥有不同的结构:


-
计算过程
最关键的是对每个词向量,每次在 Self -Attention 时初始化(后续反向传播更新)三个矩阵 query/key/value,利用 query * key 计算得到 score 并通过 softmax 计算得到 概率权重,乘以 value,得到激活词向量。
每个词向量分别进入独立的 FFNN 计算。
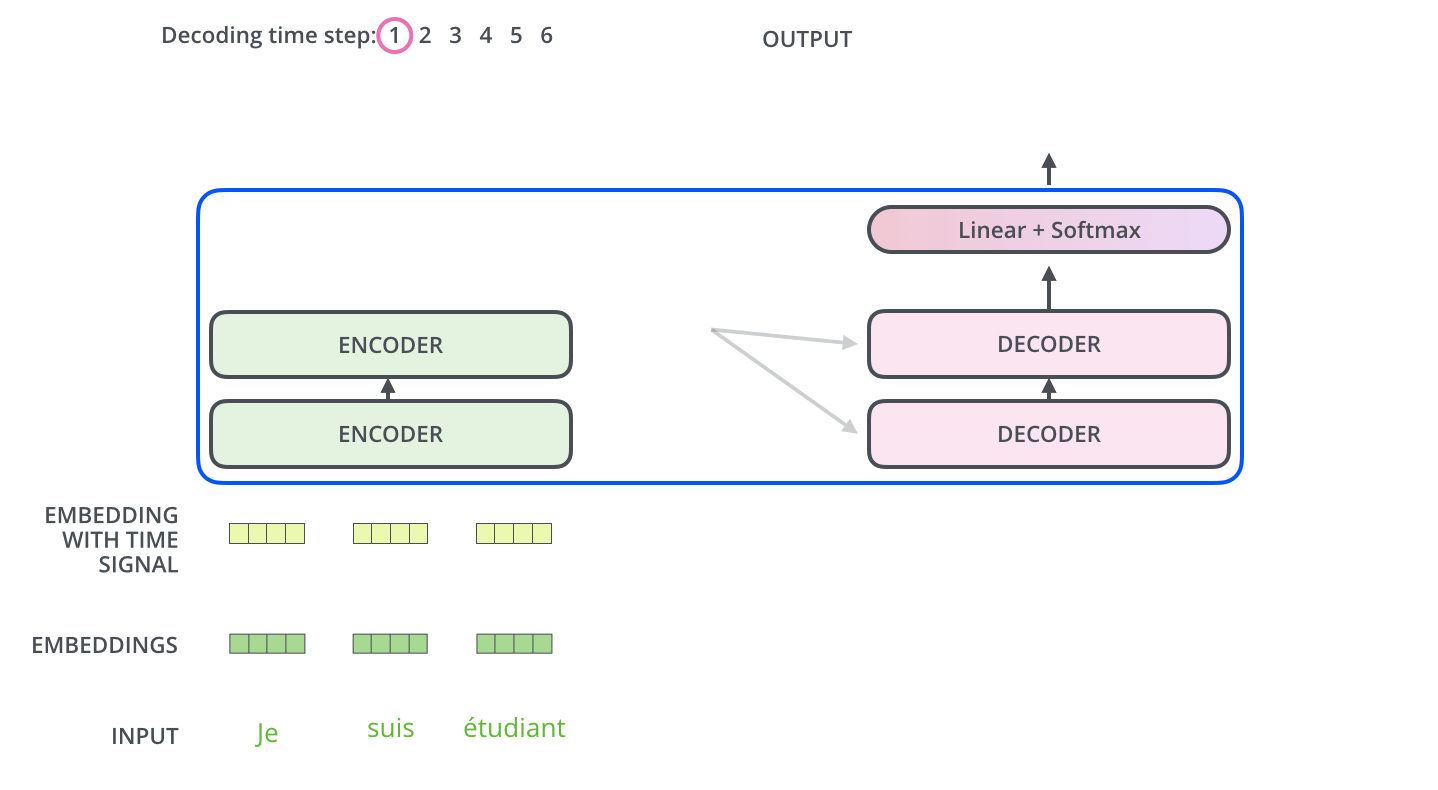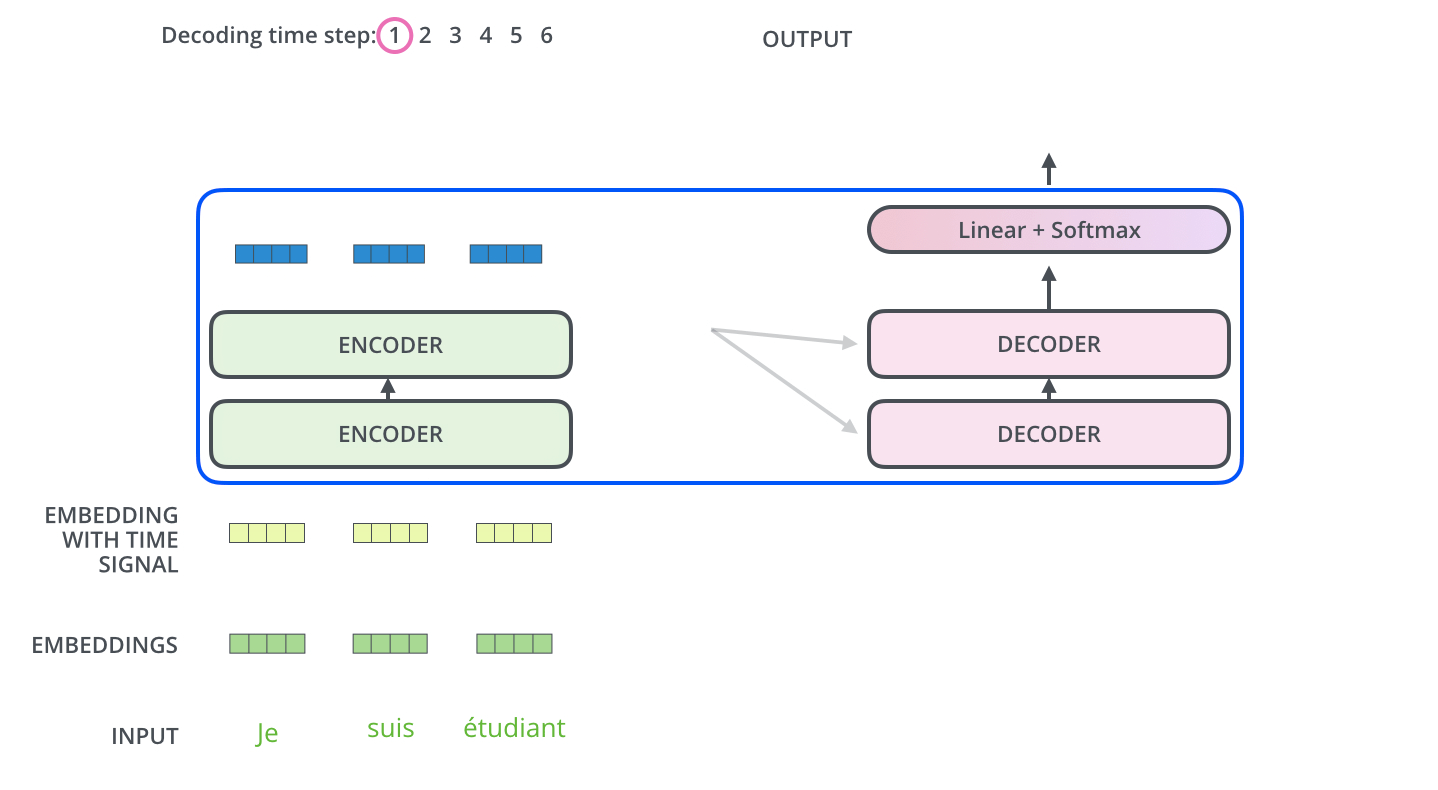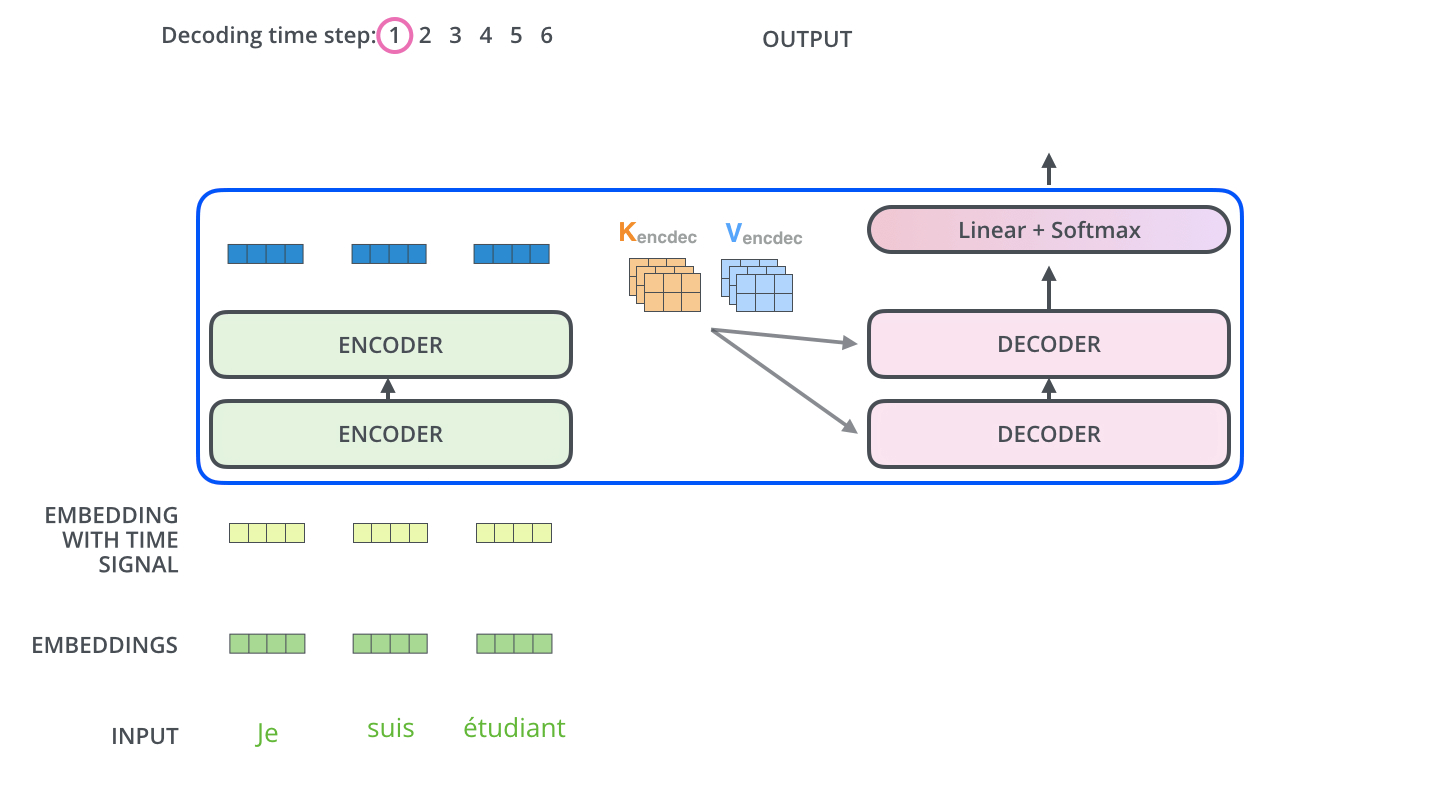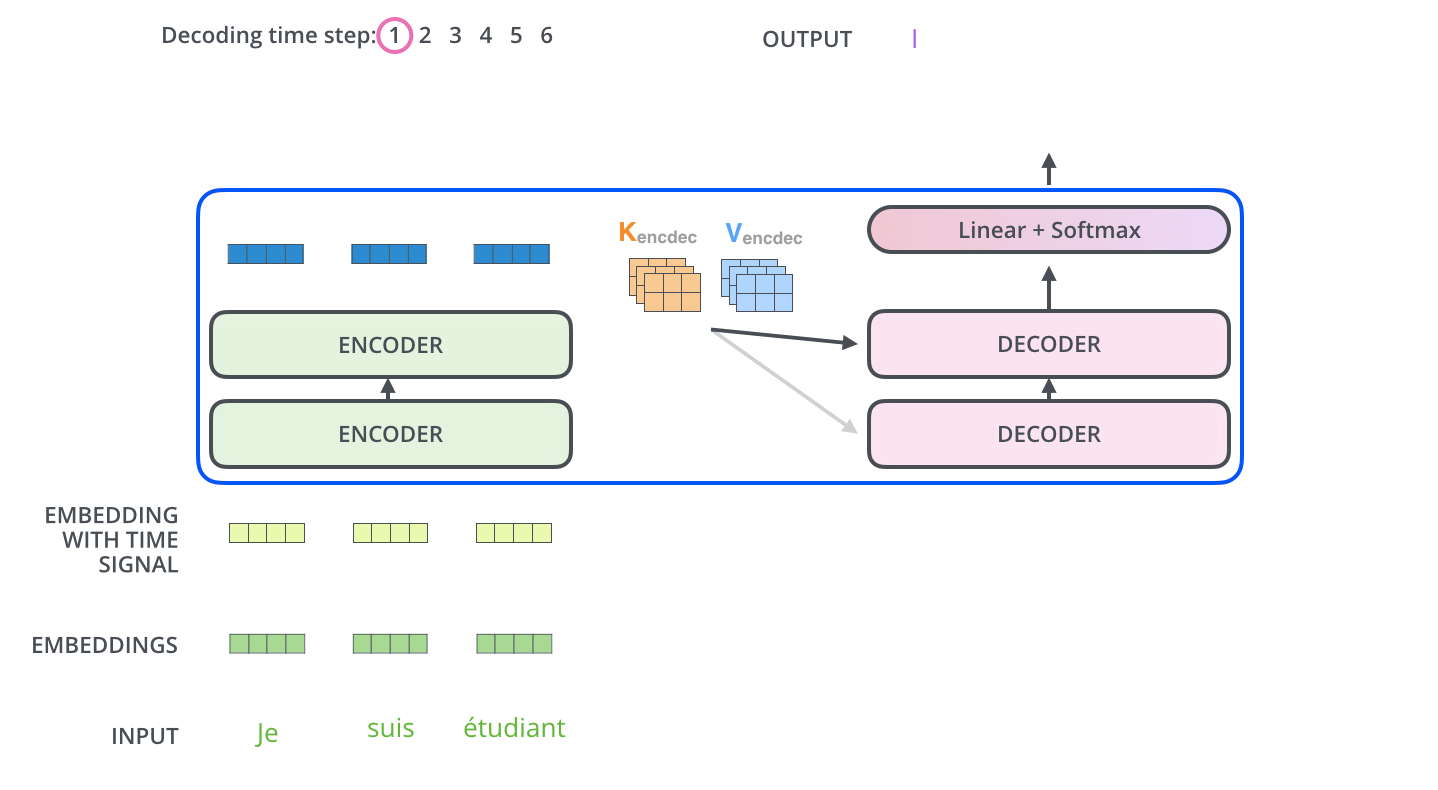
当 Encoder 计算完毕后,再转化为两个矩阵 key/value 代入到 Decoder 中 Encoder-Decoder Attention 的计算中。
















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









