









学习了numpy和matplotlib,基本上线性代数,概率论的很多计算啊之类的都可以很容易的实现了。此外再学习下scipy这个科学函数库吧。
scipy包包含致力于科学计算中常见问题的各个工具箱。它的不同子模块相应于不同的应用。像插值,积分,优化,图像处理,特殊函数等等。
1 模块
scipy 由一些特定功能的子模块组成,它们全依赖numpy,但是每个之间基本独立
| 模块 | 功能 |
|---|---|
| scipy.cluster | 矢量量化 / K-均值 |
| scipy.constants | 物理和数学常数 |
| scipy.fftpack | 傅里叶变换 |
| scipy.integrate | 积分程序 |
| scipy.interpolate | 插值 |
| scipy.io | 数据输入输出 |
| scipy.linalg | 线性代数程序 |
| scipy.ndimage | n维图像包 |
| scipy.odr | 正交距离回归 |
| scipy.optimize | 优化 |
| scipy.signal | 信号处理 |
| scipy.sparse | 稀疏矩阵 |
| scipy.spatial | 空间数据结构和算法 |
| scipy.special | 任何特殊数学函数 |
| scipy.stats | 统计 |
之后就学习下部分几个模块吧。
2 插值 scipy.interpolate
scipy.interpolate对从实验数据拟合函数来求值没有测量值存在的点非常有用
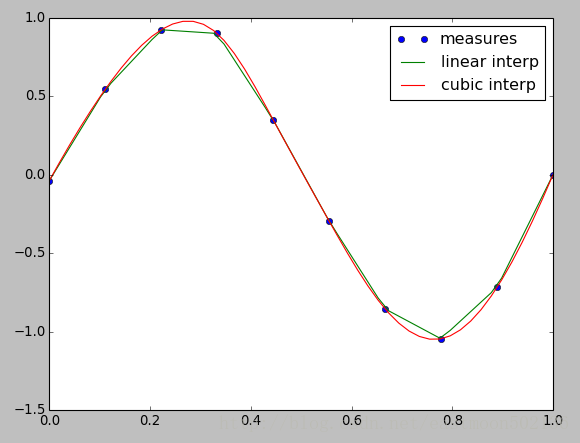
正弦函数的实验:
import numpy as np
from scipy.interpolate import interp1d
import pylab as plt
measured_time = np.linspace(0, 1, 10)
noise = (np.random.random(10)*2 - 1) * 1e-1
measures = np.sin(2 * np.pi * measured_time) + noise
#scipy.interpolate.interp1d类会构建线性插值函数:
linear_interp = interp1d(measured_time, measures)
#然后scipy.interpolate.linear_interp实例需要被用来求得感兴趣时间点的值:
computed_time = np.linspace(0, 1, 50)
linear_results = linear_interp(computed_time)
#三次插值也能通过提供可选关键字参数kind来选择
cubic_interp = interp1d(measured_time, measures, kind='cubic')
cubic_results = cubic_interp(computed_time)
#Matplotlib图像中显示如下
plt.plot(measured_time, measures, 'o', ms=6, label='measures')
plt.plot(computed_time, linear_results, label='linear interp')
plt.plot(computed_time, cubic_results, label='cubic interp')
plt.legend()
plt.show()运行结果如下:
3 信号处理 scipy. signal
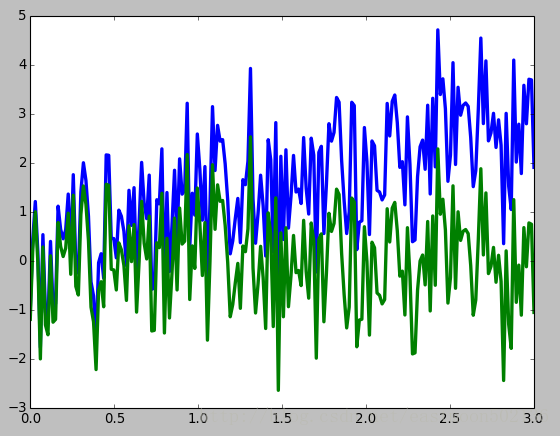
3.1 移除信号的线性趋势
import numpy as np
import pylab as plt
from scipy import signal
t = np.linspace(0, 3, 200)
x = t + np.random.normal(size=200)
plt.plot(t, x, linewidth=3)
#移除信号的线性趋势
plt.plot(t, signal.detrend(x), linewidth=3)
plt.show()运行结果:
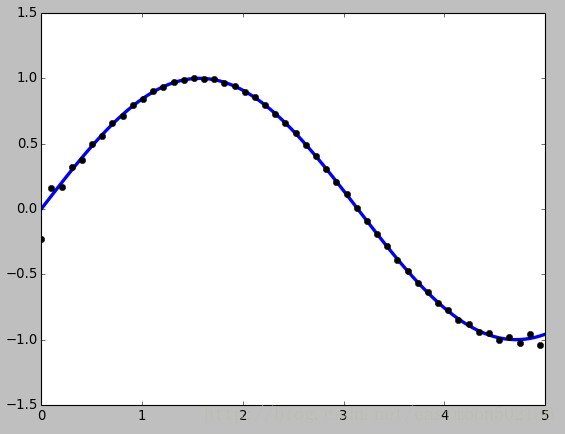
3.2FFT重采样
import numpy as np
import pylab as plt
from scipy import signal
t = np.linspace(0, 5, 100)
x = np.sin(t)
plt.plot(t, x, linewidth=3)
#使用FFT重采样n个点
plt.plot(t[::2], signal.resample(x, 50), 'ko')
plt.show()运行结果:
4 统计 scipy.stats
scipy.stats包括统计工具和随机过程的概率过程。各个随机过程的随机数生成器可以从numpy.random中找到。
| 模块 | 功能 |
|---|---|
| rvs | 随机变量(就是从这个分布中抽一些样本) |
| 概率密度函数 | |
| cdf | 累计分布函数 |
| sf | 残存函数(1-CDF) |
| ppf | 分位点函数(CDF的逆) |
| isf | 逆残存函数(sf的逆) |
| stats | 返回均值,方差,(费舍尔)偏态,(费舍尔)峰度 |
| moment | 分布的非中心矩 |
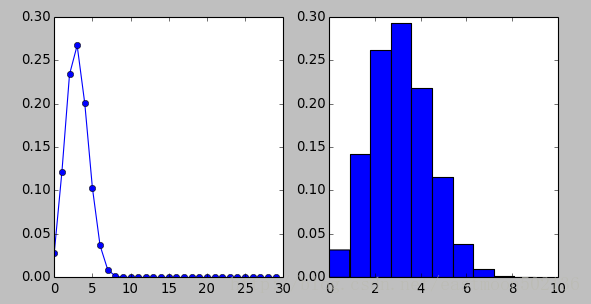
4.1 二项分布
抛掷10次硬币,假设在该试验中正面朝上的概率为0.3。使用stats.binom.pmf计算每次观测的概率质量函数。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
plt.subplot(121)
n = 10
p = 0.3
k = np.arange(0, 30)
binomial = stats.binom.pmf(k, n, p)
plt.plot(k, binomial, 'o-')
#使用rvs函数模拟一个二项随机变量,其中参数size指定你要进行模拟的次数,这里为10000次。
plt.subplot(122)
binom_sim = data = stats.binom.rvs(n=10, p=0.3, size=10000)
print "Mean: %g" % np.mean(binom_sim)
print "Sd: %g" % np.std(binom_sim, ddof=1)
plt.hist(binom_sim, bins=10, normed=True)
plt.show()运行结果:
Mean: 2.9956
Sd: 1.44187
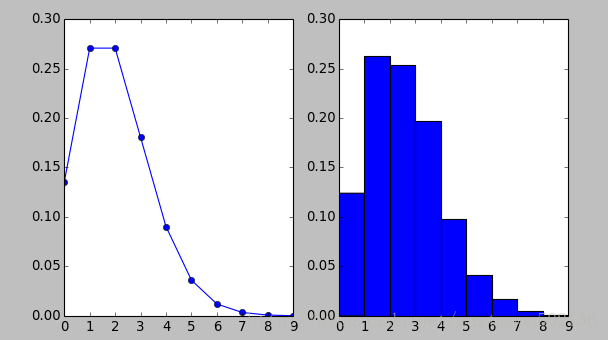
4.2 泊松分布
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
rate =2
n = np.arange(0, 10)
y = stats.poisson.pmf(n, rate)
plt.subplot(121)
plt.plot(n, y, 'o-')
#模拟1000个服从泊松分布的随机变量
plt.subplot(122)
data = stats.poisson.rvs(mu=2, loc=0, size=1000)
print "Mean: %g" % np.mean(data)
print "Sd: %g" % np.std(data, ddof=1)
plt.hist(data, bins=9, normed=True)
plt.show()运行结果:
Mean: 2.105
Sd: 1.4677
4.3 正态分布
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
plt.subplot(121)
mu = 0
sigma = 1
x = np.arange(-5, 5, 0.1)
y = stats.norm.pdf(x, 0, 1)
plt.plot(x, y)
plt.subplot(122)
data = stats.norm.rvs(0, 1, size=1000)
plt.hist(data, bins=10, normed=True)
plt.show()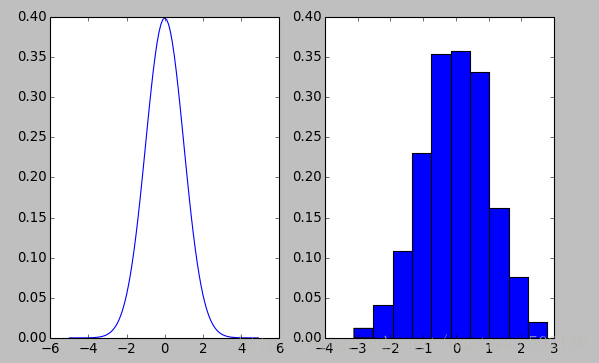
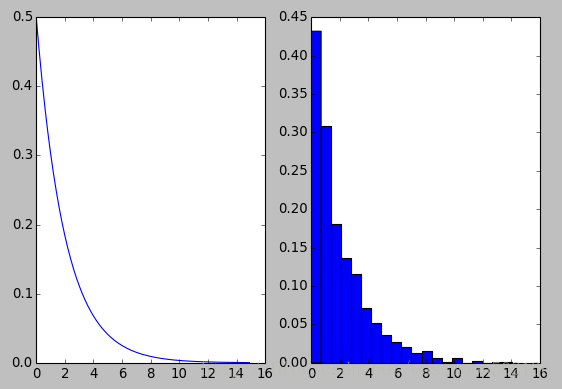
4.4 指数分布
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
plt.subplot(121)
lambd = 0.5
x = np.arange(0, 15, 0.1)
y = lambd*np.exp(-lambd*x)
plt.plot(x, y)
#下模拟1000个随机变量
plt.subplot(122)
data = stats.expon.rvs(scale=2, size=1000)
print "Mean: %g" % np.mean(data)
print "Sd: %g" % np.std(data, ddof=1)
plt.hist(data, bins=20, normed=True)
plt.show()运行结果如下:
Mean: 2.01166
Sd: 2.02959
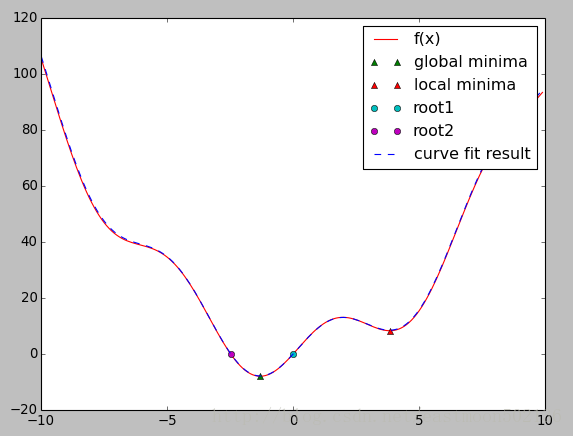
5 优化和拟合 scipy.optimize
优化是找到最小值或等式的数值解的问题
import numpy as np
import matplotlib.pyplot as plt
from scipy import optimize
#定义以下函数x^2+2sin(x)
def f(x):
return x**2+10*np.sin(x)
x = np.arange(-10, 10, 0.1)
#找到这个函数最小值一般而有效的方法是从初始点使用梯度下降法,这里用拟牛顿法
print optimize.fmin_bfgs(f, 0)
#如果函数有局部最小值,算法会因初始点不同找到这些局部最小而不是全局最小
print optimize.fmin_bfgs(f, 3, disp=0)
#为了找到全局最小点,最简单的算法是蛮力算法
grid = (-10, 10, 0.1)
xmin_global = optimize.brute(f, (grid,))
print xmin_global
#为了找到局部最小,我们把变量限制在(0, 10)之间
xmin_local =optimize.fminbound(f, 0, 10)
print xmin_local
#找到标量函数的根
root1 = optimize.fsolve(f, 1)
print root1
root2 = optimize.fsolve(f, -2)
print root2
#曲线拟合
xdata = np.linspace(-10, 10, num=20)
ydata = f(xdata) + np.random.random(xdata.size)
def f2(x, a, b):
return a*x**2+b*np.sin(x)
guess = [2, 2]
#通过最小二乘拟合拟合来找到幅度
params, params_convariance = optimize.curve_fit(f2, xdata, ydata, guess)
print params
#画图显示所有的信息
plt.plot(x, f(x), c='r', label="f(x)")
plt.plot(xmin_global, f(xmin_global), '^', label='global minima')
plt.plot(xmin_local, f(xmin_local), '^', label='local minima')
plt.plot(root1, f(root1), 'o', label='root1')
plt.plot(root2, f(root2), 'o', label='root2')
plt.plot(x, f2(x, params[0], params[1]), '--', c='b', label="curve fit result")
plt.legend()
plt.show()运行结果:
Optimization terminated successfully.
Current function value: -7.945823
Iterations: 5
Function evaluations: 24
Gradient evaluations: 8
[-1.30644003]
[ 3.83746663]
[-1.30641113]
3.8374671195
[ 0.]
[-2.47948183]
[ 1.0089413 9.92366871]
参考:
http://blog.chinaunix.net/uid-21633169-id-4437868.html
http://www.cnblogs.com/ttrrpp/p/6822214.html
基本上把python用到的数学库简单的过了一遍,相信之后遇到一些函数库也不会那么陌生了。接下去就开始真正的学习机器学习算法了。















 2358
2358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









